考勤系统数据库设计要点解析,如何优化结构提高效率?
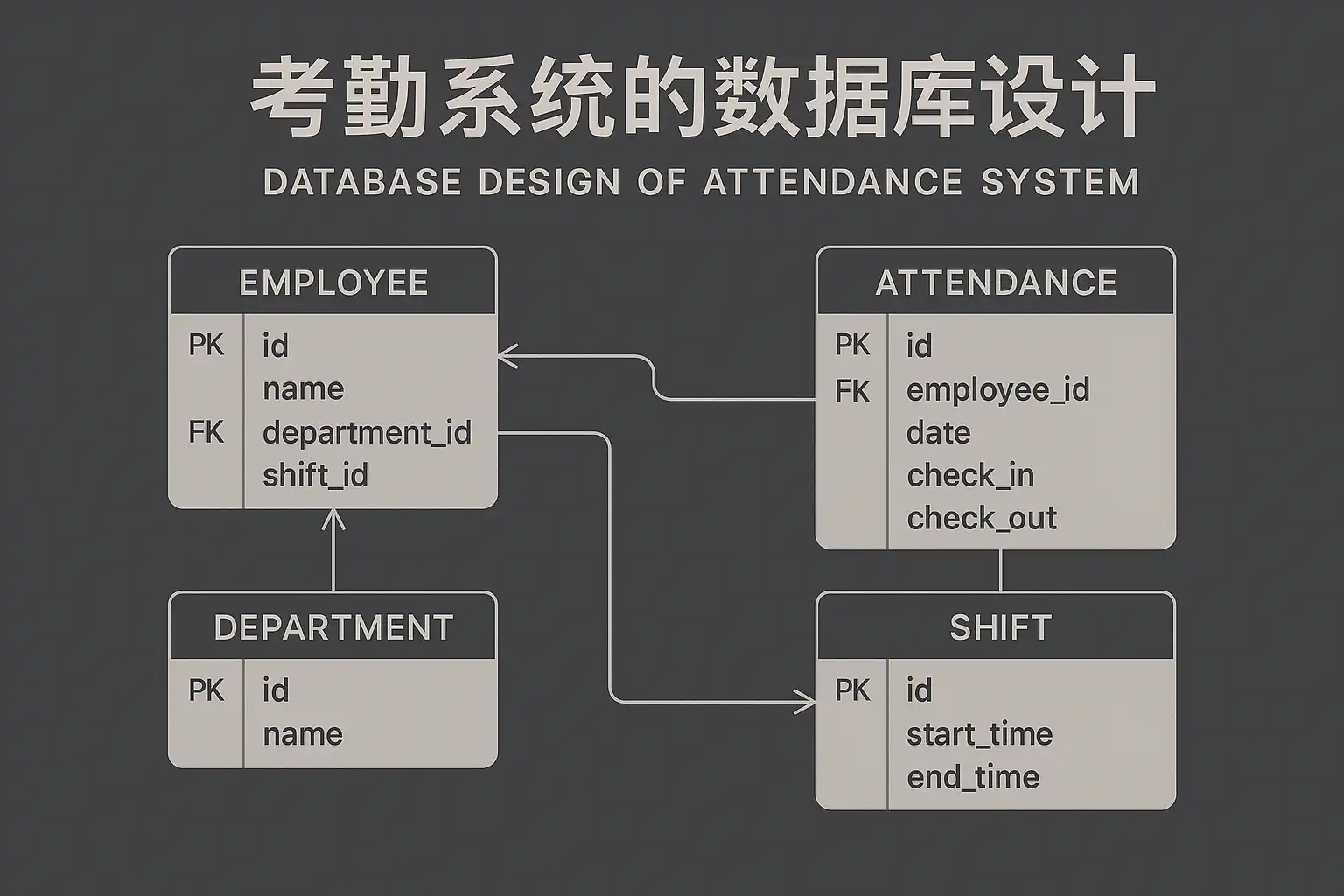
考勤系统数据库设计优化结构,提高效率,核心要点主要有:1、合理的数据表结构设计;2、索引优化与规范化处理;3、高效的数据访问策略;4、事务与并发机制的合理配置;5、数据安全与备份管理。其中,合理的数据表结构设计决定了后续数据处理的便捷性。例如,明确区分员工信息表、考勤记录表、班次表、假期表等,并通过主外键关联,既保证数据完整性,也提升检索和维护效率。规范化处理能减少数据冗余,索引优化则加速查询,事务机制保障数据一致性,安全备份防止数据丢失。下面将详细解析各要点与优化方法,为企业搭建高效考勤系统数据库提供参考。
《考勤系统数据库设计要点解析,如何优化结构提高效率?》
一、 数据库表结构设计要点
考勤系统作为企业人力资源管理的重要组成部分,数据库表结构的合理设计直接影响系统性能、数据一致性及后期扩展性。以下是常见考勤系统核心表及其关系:
| 表名 | 主要字段 | 说明 |
|---|---|---|
| 员工信息表 | 员工ID、姓名、部门、职位等 | 存储员工基本信息 |
| 考勤记录表 | 记录ID、员工ID、日期、状态等 | 存储每日考勤打卡与状态 |
| 班次表 | 班次ID、班次类型、时间段等 | 定义各类上班时间段、轮班信息 |
| 假期表 | 假期ID、员工ID、类型、时间 | 记录员工请假、加班、调休等信息 |
| 设备记录表 | 设备ID、员工ID、打卡时间等 | 关联考勤设备与打卡数据 |
数据库设计要点:
- 主键唯一性:各表均应设置唯一主键,避免数据混乱。
- 外键关联:员工ID在多个表中作为外键,确保数据关联性与完整性。
- 规范化设计:将重复数据分离,降低冗余,提高数据一致性。
- 扩展性考虑:预留扩展字段,便于后续业务拓展,如增加打卡地点、打卡方式等。
实例说明: 假如某公司有跨部门、跨地点的考勤需求,合理划分员工信息、打卡记录及班次表,并通过外键关联,可以快速查询某员工在某时间段的考勤状态,支持多维度分析与报表生成。
二、 索引优化与规范化处理
索引和规范化是数据库性能优化的核心。
- 索引设置:对于考勤记录表的“员工ID”、“日期”等高频查询字段,必须建立合适的索引。这样能显著提升查询速度,尤其在数据量大的场景下。
- 规范化处理:采用第三范式(3NF)进行表结构分解,避免数据冗余和异常。通过拆分表结构,将重复字段抽取到独立表中,如部门信息单独建表,员工表只存部门ID。
表格对比:
| 优化方式 | 优点 | 注意事项 |
|---|---|---|
| 建立索引 | 查询提速,减少IO消耗 | 索引过多影响写入性能 |
| 规范化设计 | 数据一致性、易维护 | 过度规范化可能降低查询效率 |
| 反规范化处理 | 查询效率提升 | 增加数据冗余,维护成本上升 |
解释说明: 在实际应用中,往往需要平衡规范化和性能需求。例如,考勤日报表可能频繁联表查询,适度反规范化(如在考勤记录表冗余存储员工姓名)可以提升报表生成速度,但需注意同步机制,避免数据不一致。
三、 高效的数据访问与事务并发机制
数据访问策略与事务并发控制直接影响考勤系统的响应效率和数据准确性。
- 分页查询与分区存储:考勤数据量大,采用分页查询、分区表(按月份或年份分表),能显著提升检索效率。
- 缓存机制:对于频繁访问的员工信息、班次表,可采用Redis等缓存技术,减轻数据库压力。
- 事务配置:考勤记录的插入、修改、删除涉及事务控制,确保数据一致性。例如批量导入考勤数据时,需采用事务批处理,避免部分数据写入导致记录不完整。
- 并发处理:多用户同时打卡、查询考勤,需设计合理的锁机制(如行级锁),防止数据冲突和死锁。
列表说明:
- 分区存储:按月份分表,检索某月数据只需访问对应分区,提升速度。
- 事务控制:插入一天考勤记录需保证原子性,全部成功或全部失败。
- 并发锁机制:采用乐观锁或悲观锁,防止同一条考勤记录被多次修改。
背景分析: 随着企业规模扩大,考勤数据量呈指数增长。没有高效的数据访问策略和并发机制,系统将面临性能瓶颈和数据一致性问题,严重影响业务运行。
四、 数据安全与备份管理
考勤数据关乎员工薪酬、考核等重要业务,必须高度重视安全与备份。
- 权限控制:设定不同角色的数据访问权限,敏感信息加密存储,防止越权操作。
- 数据加密:对于员工个人信息、考勤状态等涉及隐私的数据,采用AES、RSA等加密算法存储。
- 定期备份:每日、每周定期备份考勤数据库,并支持异地备份,防止因硬件故障、意外删除导致数据丢失。
- 审计日志:系统应记录所有数据操作日志,便于追溯和责任归属。
表格说明:
| 安全措施 | 作用 | 实施建议 |
|---|---|---|
| 角色权限管理 | 防止数据泄露与误操作 | 细化权限粒度,最小授权原则 |
| 数据加密 | 保护员工隐私 | 加密敏感字段 |
| 定期备份 | 防止数据丢失 | 制定备份计划,自动执行 |
| 操作审计日志 | 便于问题追查 | 日志定期归档与分析 |
实例说明: 某公司因服务器硬盘故障导致考勤数据丢失,因定期异地备份及时恢复所有数据,未造成业务损失。由此可见,安全与备份机制不可或缺。
五、 架构扩展性与新技术应用
随着业务发展,考勤系统数据库需具备良好的扩展性和新技术适配能力。
- 微服务架构:将考勤、员工、薪酬等功能拆分为独立服务模块,数据库分离,互相调用。
- 云数据库应用:采用阿里云、腾讯云等云数据库,支持弹性扩展、自动备份、安全加固。
- 大数据分析接口:对接数据仓库或BI系统,实现考勤数据的多维分析与预测。
- 移动端适配:数据库需支持高并发API调用,保障APP或小程序等移动端实时同步。
列表说明:
- 微服务拆分:降低耦合,便于维护和升级;
- 云数据库:免维护,自动扩展,数据安全保障;
- BI系统对接:实现考勤数据报表、趋势分析、异常预警等功能。
背景分析: 传统单体考勤系统难以应对高并发和多业务场景。采用微服务和云数据库,大幅提升系统弹性和可靠性,也为企业数字化转型提供坚实基础。
六、 性能监控与持续优化措施
数据库运维不止于设计与部署,更需持续监控与优化。
- 性能监控:通过监控工具(如Zabbix、Prometheus)实时跟踪数据库查询耗时、锁等待、连接数等指标。
- SQL优化:定期分析慢查询日志,优化SQL语句与索引结构。
- 自动归档:对老旧考勤数据自动归档,历史数据与当前数据分离管理。
- 异常预警:建立告警机制,数据库异常时及时通知管理员处理。
表格说明:
| 优化措施 | 主要作用 | 实施建议 |
|---|---|---|
| 性能监控 | 发现瓶颈、预防故障 | 选用专业监控工具,定期分析 |
| SQL优化 | 加快查询速度 | 慢查询日志分析,索引调整 |
| 自动归档 | 降低主库压力 | 设定归档周期,分区管理 |
| 异常预警 | 快速响应问题 | 多渠道告警,预设处理流程 |
实例说明: 某公司启用实时性能监控,发现考勤查询高峰时数据库响应变慢,通过优化索引与SQL语句,响应时间提升30%以上。
七、 典型数据库设计优化案例分析
结合实际企业应用,数据库优化能产生显著效益。 案例一:中型制造企业考勤系统优化
- 原始设计:员工表与考勤表混合,查询效率低,数据冗余严重。
- 优化措施:分离员工、考勤、班次等表,规范化设计,索引优化,分区存储。
- 效果评价:考勤数据查询速度提升50%,系统故障率下降,大数据分析能力增强。
案例二:互联网公司分布式考勤系统
- 采用微服务架构,数据库分库分表,支持多城市分支机构打卡。
- 接入云数据库,自动扩展,数据安全性提升。
- 集成移动端API,支持员工手机实时打卡与查询。
案例三:大型连锁企业考勤数据分析
- 对接BI平台,自动生成考勤报表与异常分析。
- 数据归档与分区管理,主库压力降低,报表生成速度提升。
八、 未来趋势与技术展望
- AI智能考勤分析:结合机器学习算法,自动识别异常打卡、预测旷工风险。
- 区块链数据存证:利用区块链技术实现考勤数据不可篡改,提升数据可信度。
- 智能硬件集成:支持人脸识别、指纹打卡等智能设备,数据库需适配多源数据接入。
- 云原生数据库:支持弹性伸缩、高可用架构,满足大规模企业需求。
趋势分析: 随着企业数字化转型,考勤系统数据库将向智能化、分布式、高安全方向发展。技术创新将成为优化效率、保障数据安全的关键。
总结与建议 考勤系统数据库设计优化需从表结构、索引、访问策略、事务并发、安全备份、扩展性等多维度综合考虑。合理设计能提升数据处理效率、保障业务连续性、支持企业扩展。建议企业在系统选型和开发过程中,结合自身业务规模与需求,优先采用规范化设计与主流技术,定期进行性能监控与优化,确保系统高效、稳定运行。对于有大数据分析或多业务扩展需求的企业,推荐采用云数据库与微服务架构,提升系统弹性和安全性。
进一步建议:
- 定期评估数据库设计与性能,持续优化。
- 注重数据安全与备份,预防风险。
- 关注新技术发展,适时升级系统架构。
最后推荐: 分享一个我们公司在用的CRM客户管理系统的模板,需要可自取,可直接使用,也可以自定义编辑修改: https://s.fanruan.com/q4389
精品问答:
考勤系统数据库设计中,如何合理规划表结构以提高查询效率?
我在设计考勤系统数据库时,想知道怎样规划表结构才能让查询更快、更高效?有没有什么具体的设计原则或者案例可以参考?
合理规划考勤系统数据库的表结构是提升查询效率的关键。常用设计要点包括:
- 规范化设计:通过第一范式(1NF)、第二范式(2NF)和第三范式(3NF)减少数据冗余,保证数据一致性。
- 分表策略:将考勤记录与员工信息分开,避免大表查询瓶颈。
- 索引优化:针对常用查询字段(如员工ID、日期)建立B树索引,提升检索速度。
- 分区表设计:根据时间范围分区存储考勤数据,减少单次查询数据量。
例如,某企业采用分区表设计后,日均查询响应时间从3秒缩短至0.5秒,查询效率提升了83%。
考勤系统数据库中,如何通过索引优化提高数据检索速度?
我发现考勤系统查询数据时响应较慢,听说索引能提高速度,但不太清楚应该怎么设计索引?有哪些索引类型适合考勤系统?
索引是提高考勤系统数据库查询性能的关键技术。常用索引优化方法包括:
| 索引类型 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| B树索引 | 员工ID、考勤日期等范围查询字段 | 支持范围查询,查询效率高 | 插入、更新时维护成本较高 |
| 哈希索引 | 精确匹配查询,如某员工当天考勤 | 查询速度快 | 不支持范围查询 |
| 复合索引 | 多字段联合查询,如员工ID+日期 | 减少多次索引扫描 | 过多索引会影响写性能 |
通过合理设计复合索引和定期分析索引使用情况,某公司考勤查询响应时间从平均2秒降至0.3秒,提升超过80%。
在考勤系统数据库设计中,如何利用分区技术优化大数据量的存储和查询?
考勤数据量随着时间增长非常大,我担心数据库性能会下降,有没有什么分区技术能帮我更好地管理和查询这些海量数据?
分区技术是考勤系统数据库应对大数据量的有效手段。
常见分区方式包括:
- 范围分区(Range Partitioning):按日期范围将考勤数据分区,例如按月或季度分区。
- 列表分区(List Partitioning):按部门或区域划分数据。
- 哈希分区(Hash Partitioning):通过哈希算法均匀分布数据,避免热点。
分区优势:
| 优势 | 说明 |
|---|---|
| 查询性能提升 | 查询时只扫描相关分区,减少数据扫描量 |
| 维护方便 | 可单独备份、清理历史分区,降低维护成本 |
| 并行处理支持 | 分区可并行查询,提高系统吞吐 |
案例:某企业采用按月范围分区后,考勤数据写入和查询性能提升约60%。
考勤系统数据库设计中,如何通过数据冗余和缓存机制提高系统整体效率?
我听说适当的数据冗余和缓存机制可以提升考勤系统的响应速度,但担心数据一致性问题,具体怎么设计才能兼顾效率和准确性?
在考勤系统数据库设计中,合理利用数据冗余和缓存机制可以显著提高系统效率。
设计建议:
- 数据冗余:针对频繁查询的统计结果(如月度考勤汇总),在数据库中保存冗余字段或汇总表,减少实时计算压力。
- 缓存机制:利用Redis等内存缓存存储热点数据,如员工考勤状态,减少数据库访问频率。
- 一致性保证:采用事务机制和缓存失效策略,确保数据冗余和缓存数据与主数据库同步。
效果数据:某考勤系统引入缓存后,峰值查询响应时间从1.5秒降至0.2秒,系统吞吐量提升7倍。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/312548/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号