考勤管理系统数据库结构详解,数据存储方式有哪些?
考勤管理系统的数据库结构直接影响系统的稳定性与扩展性。1、常见考勤系统数据库结构主要包括员工信息表、考勤记录表、班次表、假期申请表等核心数据表;2、数据的存储方式主要有关系型数据库、非关系型数据库和云端分布式存储三种。其中,关系型数据库(如MySQL、SQL Server)以其结构化、易于维护和高可靠性最为常用,适合大多数企业考勤系统。以关系型数据库为例,员工信息表和考勤记录表之间通常通过外键实现关联,有效保证数据一致性和查询效率。接下来将从结构设计、存储方式以及实际应用等方面进行详细分析和实例说明。
《考勤管理系统数据库结构详解,数据存储方式有哪些?》
一、考勤管理系统数据库结构概述
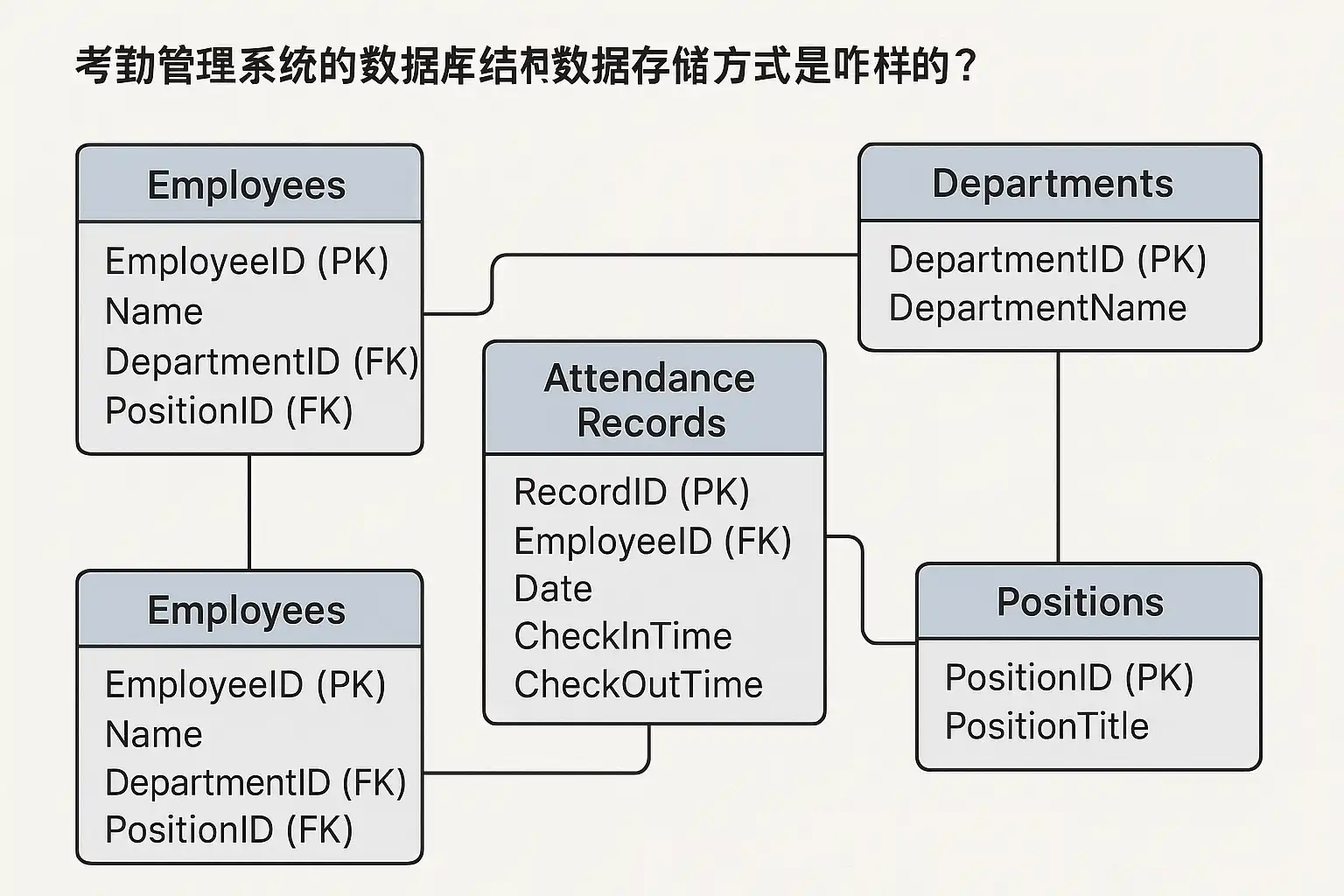
考勤管理系统的数据库结构设计目的是规范存储、便捷查询和高效维护。典型的考勤管理系统数据库结构主要包括以下几个核心数据表:
| 表名 | 主要字段示例 | 功能描述 |
|---|---|---|
| 员工信息表 | 员工ID、姓名、工号、部门、职位、入职时间、联系方式 | 存储员工基本信息 |
| 考勤记录表 | 记录ID、员工ID、打卡时间、打卡类型(上班/下班)、状态(正常/迟到/早退) | 记录员工每日考勤数据 |
| 班次表 | 班次ID、班次名称、上班时间、下班时间、适用部门 | 管理不同的上下班时间及适用范围 |
| 假期申请表 | 申请ID、员工ID、请假类型、开始时间、结束时间、审批状态 | 记录员工的请假申请及审批流程 |
| 部门表 | 部门ID、部门名称、上级部门ID | 企业组织结构管理 |
| 排班表 | 排班ID、员工ID、班次ID、日期 | 记录每位员工每日的排班情况 |
核心结构特点包括:
- 采用多表关联,保证数据一致性。
- 外键约束实现表间逻辑关联,如员工ID在多表中作为外键引用。
- 针对高频查询的字段增加索引,提升检索效率。
二、主要数据存储方式比较
考勤管理系统常见的数据存储方式有三种:关系型数据库、非关系型数据库和云端分布式存储。下面以表格方式对比其优缺点:
| 存储方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 关系型数据库 | 结构化强、支持事务、数据一致性高、查询高效 | 扩展性相对有限、大数据量时需优化 | 中小型企业、结构化数据为主 |
| 非关系型数据库 | 扩展性好、灵活性强、适合大规模并发访问 | 数据一致性弱、复杂查询能力弱 | 大型互联网企业、非结构化数据为主 |
| 云端分布式存储 | 高可用、高弹性、按需扩展、数据安全性高 | 依赖网络、成本相对较高、受限于服务厂商 | 跨地域分支、数据量大、动态扩缩容需求 |
详细描述:关系型数据库是考勤系统最常用的存储方式。 它以表格结构严密组织数据,支持SQL复杂查询、事务处理,能够高效保证数据一致性。例如,企业常用的MySQL、SQL Server都能够通过外键和索引维护大量员工及考勤数据,实现实时数据统计和分析。同时,结构化存储也便于后续系统升级和数据迁移。
三、数据库结构设计细节与表间关系
数据库结构设计决定了后续数据管理和系统扩展的便利性。以关系型数据库为例,常见表关系如下:
- 员工信息表(主表)与考勤记录表(从表):通过员工ID关联,便于统计个人考勤。
- 员工信息表和假期申请表:员工ID关联,方便查询某员工请假历史。
- 班次表与排班表:班次ID关联,用于动态调整排班。
主要表结构示例(MySQL语法):
CREATE TABLE employee (employee_id INT PRIMARY KEY AUTO_INCREMENT,name VARCHAR(50),department_id INT,position VARCHAR(50),hire_date DATE,phone VARCHAR(20));
CREATE TABLE attendance (attendance_id INT PRIMARY KEY AUTO_INCREMENT,employee_id INT,check_time DATETIME,check_type ENUM('IN', 'OUT'),status ENUM('NORMAL', 'LATE', 'EARLY_LEAVE'),FOREIGN KEY (employee_id) REFERENCES employee(employee_id));
CREATE TABLE shift (shift_id INT PRIMARY KEY AUTO_INCREMENT,shift_name VARCHAR(50),work_start TIME,work_end TIME,department_id INT);
CREATE TABLE leave_application (application_id INT PRIMARY KEY AUTO_INCREMENT,employee_id INT,leave_type VARCHAR(20),start_time DATETIME,end_time DATETIME,approval_status ENUM('PENDING', 'APPROVED', 'REJECTED'),FOREIGN KEY (employee_id) REFERENCES employee(employee_id));表间关系图:
employee ---< attendance|+---< leave_application|+---< schedule >--- shift四、数据存储方式的选择因素与实践建议
企业在选择考勤管理系统数据存储方式时,主要考虑以下因素:
- 数据量规模:小型企业优先选用关系型数据库,中大型或高并发场景可考虑云端分布式或NoSQL。
- 实时性要求:高实时性场景需考虑高性能数据库及缓存机制。
- 安全合规需求:涉敏感信息必须选用支持权限控制、加密传输的存储方案。
- 系统对接能力:需与HR、工资、考核等系统集成时,优先结构化数据库。
- 预算与维护:云服务按需扩展适合预算灵活的企业,本地部署适合有IT资源的企业。
企业应用实践:
- 某大型制造企业采用MySQL+Redis混合方案,将关键考勤数据结构化存储,近期数据实时缓存,保证查询效率,并通过定期归档保持历史数据安全。
- 某互联网公司采用MongoDB分布式存储,灵活处理多样化考勤数据格式,支持跨地域分支机构统一管理。
五、考勤管理系统数据库结构优化建议
为确保系统稳定与高效,数据库设计与运维应注意以下要点:
- 规范化设计:避免数据冗余和异常,采用第三范式。
- 合理索引:对高频查询字段(如员工ID、打卡时间)加索引。
- 分区与归档:大数据量表进行分区,定期归档历史数据。
- 审计与备份:启用数据变更审计,定期备份防止数据丢失。
- 高可用部署:采用主从复制、热备等技术,确保数据安全。
常见优化点总结表:
| 优化点 | 具体措施 | 效果 |
|---|---|---|
| 数据表分区 | 按月/年分区考勤记录表 | 提升历史数据查询与管理效率 |
| 增加缓存层 | 采用Redis等缓存近期考勤数据 | 加速高频访问 |
| 数据归档 | 自动归档超过2年历史考勤数据 | 降低主库压力 |
| 审计日志 | 记录关键操作(如补卡、请假审批) | 便于追踪与风控 |
六、考勤管理系统数据库结构的常见误区与规避方法
分析实际项目中遇到的典型误区,并给出规避建议:
- 误区:所有数据一张表,导致查询慢、维护难。
- 建议:合理分表分库,按业务逻辑拆分表结构。
- 误区:未设置外键,数据关联靠程序维护,导致数据错乱。
- 建议:用外键保证数据一致性,减少人为错误。
- 误区:考勤状态等字段设计不合理,难以扩展新的考勤类型。
- 建议:采用枚举类型或独立字典表,便于扩展和维护。
- 误区:忽视历史数据归档与备份,存储压力大。
- 建议:制定数据生命周期管理策略,定期清理归档。
七、数据库结构设计示例与实际应用场景
以某企业考勤系统为例,数据库结构应用如下:
- 员工信息表:记录全员基础信息,支持按部门、工号、职位多维查询。
- 考勤记录表:每日自动写入打卡数据,支持异常状态(如迟到、早退、缺卡)自动标记。
- 假期申请表:与审批流程系统集成,自动更新考勤状态。
- 排班表:每月初批量生成,适应灵活排班与调休需求。
实际应用流程:
- 员工自助打卡,考勤数据实时写入考勤记录表。
- 管理员通过前端查询、导出考勤报表,系统自动统计异常。
- 员工请假/调休申请,审批后自动更新考勤表及假期余额。
- 每月考勤数据归档,生成工资核算明细。
八、未来趋势与智能化管理建议
随着大数据与AI技术发展,考勤管理系统数据库结构和数据存储方式也在不断升级:
- 趋势一:结构化与非结构化数据混合存储,兼容多维度考勤数据(如GPS、刷脸照片)。
- 趋势二:云端服务普及,弹性扩容、数据灾备更灵活。
- 趋势三:智能分析与可视化,数据结构需支持快速多维统计与动态报表。
- 趋势四:与HR、工资、项目等系统一体化,数据库结构需预留接口和扩展字段。
建议:
- 新建考勤系统时,优先考虑未来扩展与集成需求,采用可扩展的表结构和标准接口。
- 定期评估数据存储与备份策略,确保数据安全合规。
- 利用智能化工具提升考勤数据分析与管理水平。
九、总结与行动建议
综上,**考勤管理系统数据库结构设计应以规范化、可扩展和高效查询为核心,数据存储方式需结合企业规模、业务需求与预算合理选择。**建议企业在系统选型和开发时,重视数据库结构科学设计,定期优化升级,结合现代云存储与智能分析工具,提升整体管理效率和数据价值。对于中小型企业,推荐优先采用结构化关系型数据库,配合定期备份和数据归档;对于大型或多分支企业,可探索云端分布式存储与大数据分析解决方案。
最后推荐:分享一个我们公司在用的CRM客户管理系统的模板,需要可自取,可直接使用,也可以自定义编辑修改:https://s.fanruan.com/q4389
精品问答:
考勤管理系统数据库结构主要包含哪些核心表?
我在了解考勤管理系统时,发现数据库结构很复杂,不知道哪些是核心表,哪些是辅助表,能不能帮我梳理一下考勤管理系统数据库结构中最重要的表?
考勤管理系统数据库结构通常包含以下核心表:
- 员工信息表(Employee): 存储员工基本信息,如员工ID、姓名、部门、职位。
- 考勤记录表(Attendance): 记录每日打卡时间、考勤状态(正常、迟到、早退等)。
- 班次表(Shift): 定义不同班次的上下班时间。
- 请假申请表(Leave): 记录员工请假类型和时间段。
- 加班记录表(Overtime): 记录加班时间及原因。
通过结构化的数据库设计,上述表之间通过外键关联,确保数据一致性和查询效率。例如,考勤记录表中的员工ID关联员工信息表,便于快速检索员工考勤情况。
考勤管理系统数据库常用的数据存储方式有哪些?
我想设计一个高效的考勤管理系统,数据库的数据存储方式选择上有哪些主流方案?它们各自的优缺点是什么?
考勤管理系统常用的数据存储方式包括:
| 存储方式 | 描述 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 关系型数据库 | 使用MySQL、PostgreSQL等存储结构化数据 | 支持复杂查询,数据一致性强 | 扩展性有限,写入压力大时性能下降 | 传统考勤数据管理,复杂报表 |
| NoSQL数据库 | 使用MongoDB、Cassandra等存储半结构化数据 | 高扩展性,支持海量数据存储 | 事务支持弱,复杂查询不便 | 大数据量实时考勤分析 |
| 云存储服务 | 利用AWS RDS、Azure SQL等云端数据库服务 | 弹性扩展,运维简单 | 依赖网络,成本相对较高 | 企业级考勤系统,跨地域部署 |
根据考勤数据的实时性和查询复杂度选择合适的数据存储方式,可以提升系统性能和用户体验。
如何通过数据库结构优化提升考勤管理系统的查询效率?
我开发考勤管理系统时,发现查询员工考勤记录很慢,有没有数据库结构上的优化建议,可以提高查询效率?
提升考勤管理系统查询效率的数据库结构优化方法包括:
- 索引优化:对常用查询字段如员工ID、考勤日期建立复合索引,减少全表扫描。
- 分表分区:按时间(如按月分表)或部门分区,降低单表数据量。
- 视图与缓存:创建视图简化复杂查询,结合缓存技术减少数据库负载。
- 数据冗余:合理冗余部分计算字段(如累计出勤天数),减少实时计算压力。
例如,某企业考勤系统通过对“考勤记录表”建立员工ID+考勤日期联合索引后,查询响应速度提升了40%。
考勤管理系统中数据存储安全性如何保障?
我担心考勤管理系统中存储的员工考勤数据泄露或被篡改,数据库层面有哪些安全措施可以保障数据安全?
保障考勤管理系统数据存储安全的措施包括:
- 权限控制:严格设置数据库访问权限,采用最小权限原则。
- 数据加密:对敏感字段(如员工身份证号)进行加密存储,传输时使用SSL/TLS协议。
- 审计日志:记录数据库访问和操作日志,方便追踪异常行为。
- 备份恢复:定期备份数据库,确保数据可恢复。
- 防SQL注入和攻击:使用预编译语句和参数化查询,防止恶意攻击。
例如,某大型企业通过启用数据库透明数据加密(TDE)和多因素认证,成功防止了多起数据泄露事件。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/312621/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号