生物信息学零代码差异分析如何进行?

差异分析可以帮助科研人员深入研究疾病发生机制、发现潜在的治疗靶点、识别生物标志物等。在过去,差异分析通常依赖于繁琐的编程和复杂的数据处理流程。然而,随着技术的进步和软件工具的发展,生信零代码差异分析逐渐成为一种受欢迎的方法。
生信零代码差异分析的基本思路是利用现有的生物信息学软件和工具,并通过图形化界面操作,实现数据导入、数据预处理、差异分析模型的构建和结果的解读等一系列步骤,从而避免了繁琐的编程步骤。下面我们将介绍一般生信零代码差异分析的基本流程。
首先,数据导入是差异分析的第一步。生信数据一般以表格形式存储,比如常用的表达谱数据(Expression Profile Data)或蛋白质组数据(Proteomic Data)。在零代码分析中,使用者只需要将数据文件上传到分析平台,然后通过简单的操作将数据导入到系统中。
第二步是数据预处理。生信数据中常常存在一些噪声、缺失值和离群值等问题,需要进行预处理。在零代码分析中,使用者可以利用平台提供的数据清洗、标准化、样本质控等功能,对原始数据进行处理和修正,以获得更加准确的结果。
接下来是差异分析模型的构建。差异分析模型是一种数学模型,用于比较不同组别之间的差异。常用的差异分析模型有t检验、方差分析(ANOVA)、线性回归等。对于生信数据,也可以采用一些基因表达模式识别的算法,比如PCA、PLS-DA等。在零代码分析中,使用者只需要选择合适的差异分析模型,并进行参数设置,即可快速构建模型,无需编写代码。
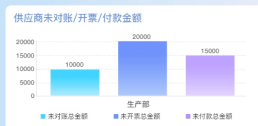
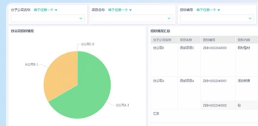
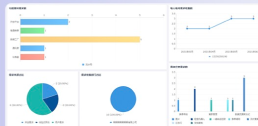
最后是结果的解读与可视化。差异分析的最终目的是获得有意义的结果,为后续的生物学研究提供参考。在零代码分析中,使用者可以借助平台提供的结果解读和可视化功能,对差异表达基因或蛋白质进行筛选、图形化展示、通路富集分析等,以便更好地理解数据。
总而言之,生信零代码差异分析为生物信息学研究者提供了一种简便、高效的分析方法。与传统的编程分析相比,零代码分析无需编写复杂的程序,大大降低了分析的门槛和学习成本,并且能够使分析结果更加可靠和可重复。对于那些没有编程经验或时间紧迫的研究人员来说,生信零代码差异分析是一种非常有吸引力的选择。
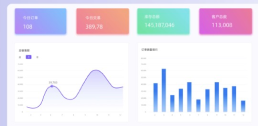
简道云是一个零代码的应用搭建平台,它提供了丰富多样的功能和模块,可以帮助各行业人员在不使用代码的情况下快速搭建个性化的CRM、ERP、OA、项目管理、进销存等系统。简道云的产品包含了自定义表单、自定义报表、自定义流程引擎、知识库、团队协作等功能,使得用户可以根据自己的需求进行系统的定制和扩展。与传统的软件开发相比,简道云的应用搭建速度更快、成本更低,同时也更加灵活和易用。无论是科研人员、医药企业、生物技术公司还是其他需要进行生信分析的用户,都可以通过简道云实现生信零代码差异分析的快速部署和使用。
综上所述,生信零代码差异分析是一种便捷、高效的分析方法,可以帮助科研人员更好地理解生物信息学数据。而简道云作为一个零代码的应用搭建平台,能够为各行业人员提供个性化的系统定制和扩展。通过简道云,生信分析将更加简单、高效,为生物科学的发展提供更多便利。