ERP高并发实现方法揭秘,如何有效提升系统性能?
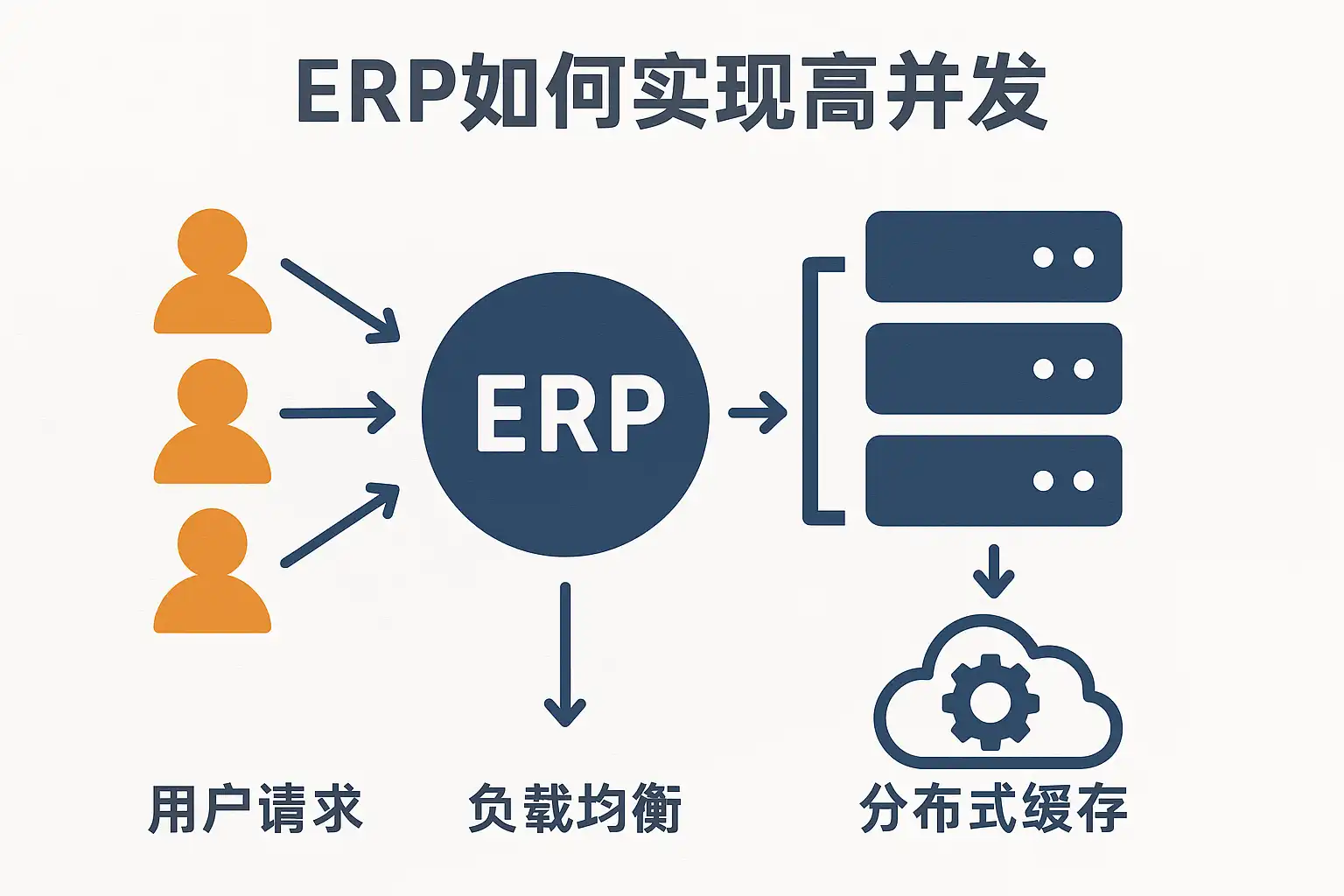
ERP实现高并发的方式主要包括:1、采用分布式架构与负载均衡;2、优化数据库性能与缓存机制;3、应用异步处理与队列技术;4、利用微服务拆分核心业务模块。其中,分布式架构与负载均衡尤为关键,它通过将请求合理分发到多台服务器上,显著提升并发处理能力。例如,通过部署多台应用服务器和反向代理,实现系统横向扩容,确保即使在业务高峰期也能保持响应速度和稳定性。其他方式如数据库优化和异步消息队列,则进一步降低数据争用和阻塞风险,共同保障ERP系统高并发场景下的可靠运行。
《erp如何实现高并发》
一、什么是ERP高并发及其挑战
企业资源计划(ERP)系统作为企业管理信息化的核心平台,常常需要支撑大规模用户同时在线操作。所谓“高并发”,指的是在同一时间段内,大量用户或业务请求同时对系统进行访问和操作。这对于系统的稳定性、响应速度以及数据一致性提出了极高要求。
主要挑战包括:
- 数据一致性问题:多用户同时操作相同数据时,如何保证数据准确且不冲突。
- 响应延迟:请求量激增可能导致页面卡顿或超时。
- 资源瓶颈:单点数据库或服务器容易成为系统短板。
- 容错需求:任意节点宕机不能影响整体业务流程。
二、高并发实现的核心技术路径
以下是实现ERP高并发的主要技术路径:
| 技术方案 | 作用简述 |
|---|---|
| 分布式架构 | 将应用拆分部署在多台服务器上,实现横向扩展,提高整体吞吐量 |
| 负载均衡 | 自动将外部请求均匀分配到各个后端节点,防止单点过载 |
| 数据库优化 | 分库分表、读写分离、索引优化等手段提升数据库吞吐率 |
| 缓存机制 | 利用Redis等缓存热点数据,减少对数据库的直接压力 |
| 异步消息队列 | 对不需实时返回的任务进行解耦处理,提高主流程响应速度 |
| 微服务化 | 拆分成多个独立可扩展小服务,各自独立伸缩 |
详细说明——以“分布式架构与负载均衡”为例:
- 系统前端部署反向代理(如Nginx),接收所有外部请求。
- 多台应用服务器组成集群,各自承担部分业务流量,实现横向扩容。
- 结合健康检查与自动伸缩机制,应对突发流量波动。
- 后端数据库亦可采用主从复制/读写分离策略,多节点协作提升性能。
三、关键实现步骤与流程梳理
要让ERP系统支持高并发,需要以下几个具体实施步骤:
- 架构设计
- 选择合适的平台与中间件(如Spring Cloud+Kubernetes)。
- 明确各模块边界,为后续拆分做准备。
- 部署实施
- 应用层面采用容器化或虚拟机集群部署。
- 配置负载均衡器(如Nginx, LVS, 阿里云SLB)。
- 数据层优化
- 热点表水平切分(Sharding)、冷门表合并减少维护成本。
- 应用Redis/Memcached对频繁读取的数据加速访问。
- 实施读写分离,将查询压力转移至只读节点。
- 异步解耦
- 使用消息队列(RabbitMQ, Kafka)推迟不紧急任务执行,如日志记录、大批量报表生成等。
- 性能监控与自动伸缩
- 部署APM监控工具,实时跟踪性能瓶颈。
- 根据流量自动调整实例数量,实现弹性扩容缩容。
四、高并发下的数据一致性保障策略
高并发环境下的数据一致性至关重要,可采用以下几种方法:
- 分布式事务管理 如TCC(Try Confirm Cancel)、SAGA模式,对跨库/跨服务操作进行补偿控制;
- 悲观锁/乐观锁 数据库层面加锁防止同时修改,但会影响部分性能;
- 最终一致性 对于非强一致场景,可以接受一定延迟后达到最终状态同步;
- 幂等设计 确保重复提交相同操作不会造成脏数据或异常结果;
举例说明:订单模块中采用乐观锁,每次更新前校验版本号字段,有冲突则提示重试,从而保证不会出现超卖情况。
五、高并发测试及瓶颈定位方法
只有经过严格测试验证才能确保ERP系统在实际环境下稳定运行,包括但不限于:
-
性能基准测试 利用JMeter、LoadRunner等工具模拟真实用户行为,高压环境检验响应时间及吞吐率;
-
压力测试流程
| 步骤 | 内容描述 |
|---|---|
| 流量模拟 | 按预期峰值用户数产生持续流量 |
| 指标采集 | 实时收集CPU/内存/带宽/IO等关键指标 |
| 日志分析 | 排查错误堆栈、慢查询SQL定位故障点 |
| 调优迭代 | 针对发现的问题逐项修正,如增加缓存、更改配置参数 |
- 瓶颈排查技巧 常见问题包括GC频繁、多线程竞争激烈、不合理SQL语句等。借助APM工具定位代码耗时最长环节,对症下药提升效率。
六、典型案例分享——简道云ERP如何应对高并发场景
简道云ERP系统作为新一代低代码企业管理平台,在应对客户大规模协同办公需求时,通过如下措施保障了高可用和高性能:
- 完全基于微服务+容器化部署,每个子业务独立弹性伸缩;
- 应用层面全面支持水平拓展;
- 引入Redis作为全局缓存,大幅降低数据库压力;
- 消息队列解耦批量审批、大型导入导出等慢任务;
- 提供API限流、防刷机制,有效防御恶意攻击或爬虫流量冲击;
这些措施不仅让简道云ERP可以轻松支撑千人级别同时在线,还保证了复杂审批流转、多部门报表统计实时无延迟。更多产品信息见官网:https://s.fanruan.com/2r29p
七、高性能ERP落地建议与未来趋势展望
为确保企业级ERP顺利应对未来日益增长的数据及用户规模,应关注如下几点建议:
- 持续关注架构演进,不断引入新的弹性计算资源,比如Serverless/FaaS模式;
- 重视开发运维一体化(DevOps),快速迭代升级软件版本,修复已知瓶颈;
- 定期开展容量评估和压测演练,应急预案提前制定完善;
- 加强安全防护措施,高并发往往也是安全攻击易被利用时期,如DDoS防护、多因子认证必不可少;
- 鼓励员工参与线上培训,提高全员故障敏感度和处理效率;
未来,高性能、高可靠、自适应弹性的智能化ERP将成为主流趋势。人工智能、大数据分析技术也会进一步融入,使得企业决策更为科学智能。
总结
综上所述,实现ERP的高并发能力,是一个涵盖架构设计、技术选型到运维保障的综合工程。充分利用现代IT技术手段,如分布式架构、缓存加速、异步解耦以及完善的数据一致性策略,是解决大规模业务挑战不可或缺的方法。同时要注重实战演练和持续改进,让系统始终保持最佳状态。建议有条件的企业可以参考简道云这类成熟方案,加速自身数字化转型之路。如需实际体验相关模板,可参考:https://s.fanruan.com/2r29p
精品问答:
ERP系统如何通过架构设计实现高并发处理能力?
作为一名ERP系统开发者,我经常遇到系统在高并发场景下响应变慢的问题。想知道架构设计方面有哪些具体方案可以提升ERP系统的并发处理能力?
ERP系统实现高并发的关键在于合理的架构设计,主要包括以下几点:
- 分布式架构:通过分布式服务拆分业务模块,避免单点瓶颈。
- 异步处理机制:利用消息队列(如Kafka、RabbitMQ)处理异步任务,提升响应速度。
- 负载均衡:部署多台服务器,通过负载均衡器(如Nginx、F5)均匀分配请求流量。
- 数据库优化:采用读写分离、分库分表技术减轻数据库压力。案例中,某大型制造企业通过引入微服务架构与Redis缓存,将峰值并发处理能力提升了300%。
使用缓存技术如何提升ERP系统的高并发性能?
我注意到很多ERP解决方案都强调缓存的重要性,但具体缓存策略是怎样帮助提高系统在高并发情况下的性能?有哪些常见的缓存技术被广泛应用?
缓存技术能显著降低数据库访问频率,从而提升ERP系统在高并发环境下的响应速度。常见缓存策略包括:
- 本地缓存(如Guava Cache):适用于低延迟访问。
- 分布式缓存(如Redis、Memcached):支持跨服务器数据共享和快速读取。
- 页面及数据预热:提前加载热点数据以减少请求延迟。
例如,一家零售企业采用Redis作为分布式缓存后,其订单处理峰值TPS(每秒事务数)从2000提升至6500,响应时间缩短了40%。
数据库优化对ERP系统高并发性能有什么影响?
我对ERP数据库优化很感兴趣,尤其是在面对大量用户同时操作时。数据库层面具体有哪些优化手段能有效支撑高并发?
数据库是ERP系统核心组件,高效的数据库设计和优化直接影响整体并发性能。主要优化措施包括:
- 分库分表:将大表拆分成多个子表或多个数据库实例,减少单节点压力。
- 索引优化:合理创建索引,加快查询速度。
- SQL语句调优:避免全表扫描,利用执行计划分析进行调整。
- 使用读写分离架构,将读操作导向只读副本,提高查询吞吐量。 实际案例显示,一家物流公司通过实施分库分表和读写分离,使其日均交易量从10万笔增长至35万笔,仍保持稳定响应。
如何通过异步消息队列技术保障ERP系统的高并发稳定性?
我听说异步消息队列能缓解高并发压力,但不太理解它具体是如何应用于ERP系统中以保证稳定性的,有没有相关案例可以说明?
异步消息队列技术允许将耗时操作异步化处理,从而避免请求阻塞,提高整体吞吐量。关键优势包括缓冲流量峰值和解耦业务模块。在ERP场景中,经常用于订单处理、库存更新等环节。例如使用RabbitMQ或Kafka来承载消息传递。在某电商平台中,引入Kafka后,其订单处理峰值TPS提高了250%,且故障恢复能力增强,实现了业务连续性保障。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/106530/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号