进销存数据接口优化技巧,如何提升数据同步效率?
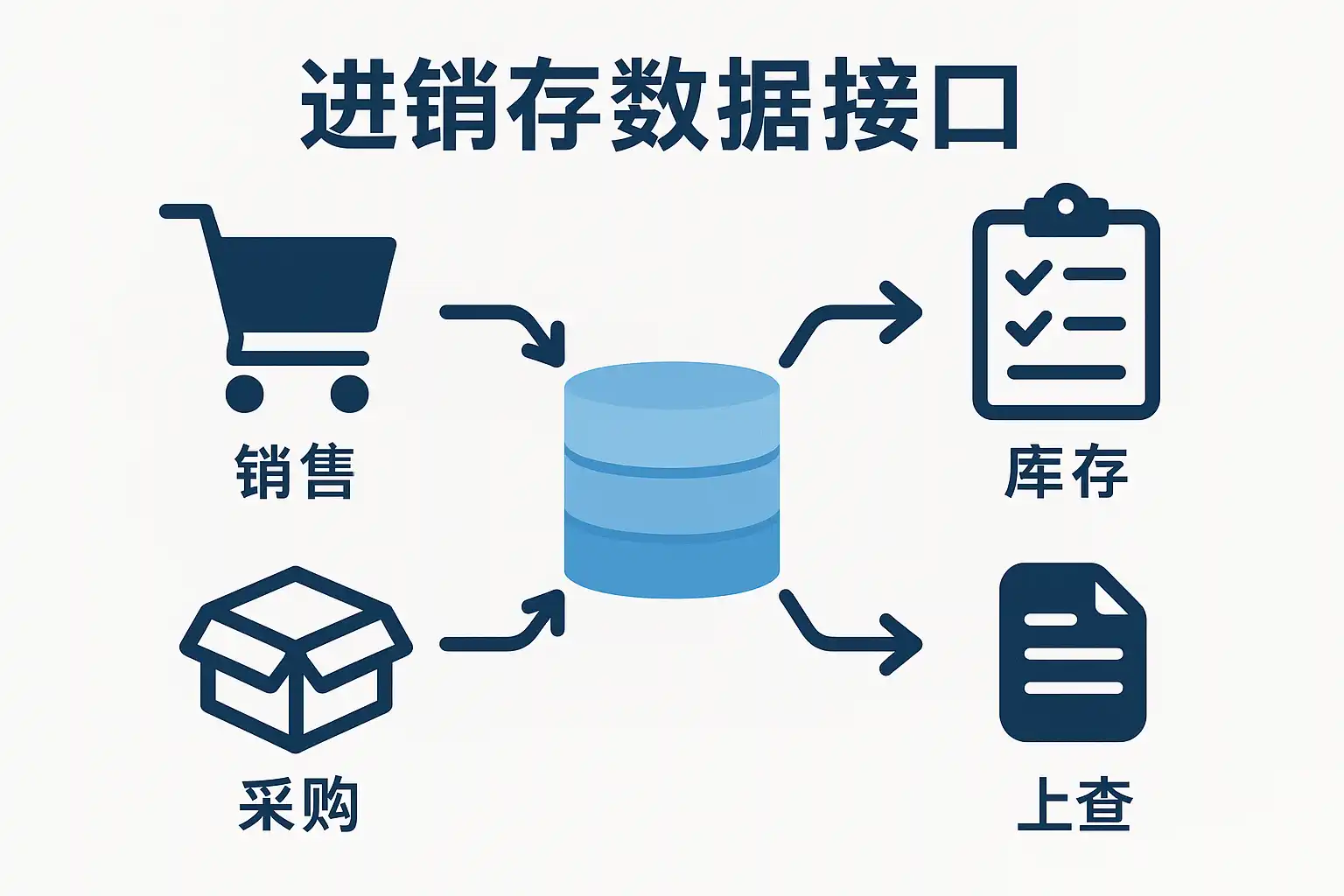
为提升进销存数据接口的同步效率,核心在于:1、事件驱动的增量同步、2、幂等与去重、3、批量传输与压缩、4、游标分页与断点续传、5、并发与一致性控制、6、可观测与自愈。其中,事件驱动增量同步通过数据库CDC或Outbox表捕获变更,转化为“订单创建、库存锁定、出入库调整”等领域事件,借助消息队列推送到下游,结合高水位线与重放能力,将延迟从分钟级缩短到秒级,并避免反复全量扫描造成的数据库热点与IO风暴,普遍可把数据库QPS与网络带宽消耗降低一个数量级。
《进销存数据接口优化技巧,如何提升数据同步效率?》
一、总体思路与目标
- 业务背景:进销存涉及商品、供应商、采购、销售、库存、调拨、盘点等多域数据,且对“时效”和“准确性”高度敏感,任何延迟或重复写入都会放大为缺货、超卖或财务对账异常。
- 优化目标:
- 延迟:T+0,核心链路秒级(p95 < 3s),非核心分钟级。
- 准确:幂等+去重,容忍至少一次投递但最终一致。
- 成本:负载均衡,避免高峰扫描;网络与存储压缩;查询走覆盖索引。
- 可观测:可追踪、可重放、可校验,失败有补偿方案。
- 范式:以“增量事件驱动”为主,“批处理快照”为辅,形成“实时 + 批量”的双轮体系。
二、同步架构选型与对比
常见接口/链路选择包括 REST 轮询、Webhook 回调、CDC+消息队列、gRPC 流式以及文件批量(SFTP/对象存储)。不同阶段和数据量级应差异化取舍。
| 同步方式 | 适用规模 | 典型延迟 | 成本复杂度 | 主要优点 | 风险/要点 |
|---|---|---|---|---|---|
| REST 轮询(增量) | 小-中 | 秒-分钟 | 低 | 实现简单,易调试 | 容易漏数或重复;需游标与幂等 |
| Webhook 回调 | 小-中 | 秒级 | 中 | 主动推送,降低轮询压力 | 重试签名、顺序保障与去重 |
| CDC + MQ(Kafka/RabbitMQ) | 中-大 | 近实时 | 中-高 | 事件驱动,解耦,吞吐高 | Outbox、顺序、回溯、重放治理 |
| gRPC 流式/HTTP2 | 中-大 | 近实时 | 中 | 双向流,低延迟 | 连接管理、背压与流量控制 |
| 文件批量(SFTP/OSS) | 大批量/离线 | 小时级 | 低-中 | 批处理成本低 | 实时性差,需校验/断点续传 |
推荐组合:
- 小规模/起步:REST 增量轮询 + Webhook(关键事件)
- 中规模:Webhook + Cursor 分页 + 压缩,加入幂等与补偿任务
- 大规模:CDC + MQ 事件总线 + 批量快照夜间校对 + gRPC/HTTP2 流式回放
三、增量同步与事件建模
- 事件来源:
- 数据库层:Binlog CDC(如 Debezium)捕获 insert/update/delete。
- 应用层:Transactional Outbox,将业务提交与事件记录在同一事务中,异步发布,避免双写丢失。
- 事件模型:
- 标准字段:event_id(全局唯一)、event_type(order.created/stock.reserved)、occurred_at(业务时间)、producer、source_tenant、payload(去敏化)、version。
- 幂等键:业务主键+版本号(如 order_id + version),保证重复消费不产生副作用。
- 顺序与回放:
- 对同一聚合根(如同一库存记录)使用分区键确保局部顺序。
- 使用高水位线(Watermark)和可重放窗口(如7-14天)处理补偿与现场还原。
- 示例:库存锁定事件 stock.reserved
- 触发:订单提交→库存预占
- 幂等:reservation_id 唯一;若重复则返回已处理
- 失败补偿:超时自动释放预占;事件补发时按 reservation_id 去重
四、接口协议与传输优化
- 协议选择:
- 内网高吞吐:gRPC/HTTP2 + Protobuf,低开销序列化。
- 公网与生态对接:REST/JSON,但务必开启压缩与分页。
- 压缩与批量:
- Accept-Encoding: gzip/zstd;传输数组批量(建议100-1000条/包,按对象大小动态调节)。
- 批内去重,按聚合根分桶,减少跨桶锁冲突。
- 差异化传输:
- 只传增量字段(patch),大对象分片或引用外部存储。
- 利用 ETag/If-None-Match 做资源级条件拉取。
- 减少往返:
- 幂等创建返回当前状态(upsert),避免“查-存-查”的N+1。
- 预取关联字典(商品、仓库)并做本地缓存,减少重复拉取。
五、分页、游标与断点续传
- 游标种类:
- 时间水印:updated_at > last_ts OR (updated_at = last_ts AND id > last_id)
- 业务版本:version > last_version(配合乐观锁)
- 事件序号:offset/sequence(来自消息队列或事件表)
- 推荐分页:Keyset/Cursor(避免 offset 翻页性能与漏数问题)
- 断点续传:
- 返回下一页 cursor,服务端隐藏实现细节。
- 客户端持久化 cursor,失败可从上次断点继续。
- 常见陷阱与修复:
| 问题场景 | 现象 | 修复建议 |
|---|---|---|
| offset 分页漏数/重复 | 并发更新导致页内容漂移 | 使用 keyset:updated_at + id 严格有序 |
| 时间水印跨时区/时钟漂移 | 下游时序错乱或漏数 | 统一UTC,允许重叠窗口(overlap)并幂等 |
| 大事务更新 | 峰值雪崩、超时 | 拆批,分片并行,队列缓冲+背压 |
| 断点丢失 | 任务重启重复拉取 | 持久化 cursor + 幂等键 |
六、并发控制与库存一致性
- 乐观并发控制(OCC):库存记录携带 version;更新时 where id=? and version=?,成功则 version+1;失败重试或回退。防止超卖与“最后写入覆盖”。
- 预占/释放模型:
- 预占:下单先 reserve,库存可用=物理库存-预占量
- 成单:confirm,预占转为扣减
- 取消/超时:release,归还可用
- 原子性与排序:
- 同一 SKU/仓库按聚合根串行化或采用分段锁;事件侧按 partition key 保顺序。
- 双写问题:
- 外部系统回传状态时只做幂等更新,不直接覆盖数量;采用“差值事件”而非“最终数值”。
七、幂等、去重与重试策略
- 幂等键设计:request_id(调用方生成)、业务主键+版本、事件 event_id;服务端存储处理指纹(hash)与过期时间。
- 重试与回退:
- 网络/429/5xx:指数退避(exp backoff)+ 抖动;上限重试次数,超限入死信队列(DLQ)。
- 业务冲突:短重试+人工审计通道。
- 语义选择:
- 至少一次 + 幂等(现实可达);尽量避免至多一次(丢单风险)。
- 去重窗口:
- 依据事件时间与保留策略(如7天),滚动清理幂等记录,控制存储成本。
八、性能调优清单(数据库与应用)
- 数据库层:
- 索引:为 updated_at、id、version 建立组合索引;覆盖索引减少回表。
- 分区与冷热数据:按日期/仓库维度分区;归档历史订单。
- 只读副本:接口读走从库,主库写轻量化。
- 限流与保护:高峰期限制并发扫描批量大小;夜间异步清算。
- 应用层:
- 连接池与线程池:根据p95延迟与CPU核数设定;避免阻塞式IO。
- 批处理:读100-500条/批,写50-200条/批;按响应体大小动态调整。
- 序列化:Protobuf/MessagePack 替代 JSON 于内网链路;外网 JSON 开 gzip。
- 缓存:SKU、供应商等主数据 TTL 缓存;ETag/If-Modified-Since。
- 量化成效示例(典型改造后):
- 查询扫描量降低 70%+(全量改增量+覆盖索引)
- 网络带宽降低 60%(批量+gzip)
- 端到端延迟从 30-60s 降至 2-5s(事件驱动+游标)
九、监控、校验与补偿
- 指标体系:
- 吞吐(events/sec)、延迟(端到端/各阶段 p95)、错误率、重试率、幂等命中率、滞后(最大/平均 lag)。
- 告警与自愈:
- 阈值告警 + 自动降速(限流)+ 熔断,溢出流量进入缓冲队列。
- 数据校验:
- 按日快照对账:订单数、金额、库存结余;抽样核对明细。
- 校验算法:分区CRC/哈希校验,差异列表驱动补偿任务。
- 补偿执行:
- 事件重放:基于时间窗口与聚合根定向重放。
- 幂等确保补偿安全;记录补偿审计轨迹。
十、安全与合规
- 身份与授权:OAuth2 Client Credentials、短期 Token、最小权限原则。
- 消息签名:HMAC-SHA256(Webhook/回调),防篡改防重放。
- 传输与存储:TLS1.2+,敏感字段脱敏/加密;访问审计与数据留痕。
- 多租户隔离:tenant_id 强约束,分库分表或逻辑隔离避免串租。
十一、实施步骤与里程碑
- 第1周:现状评估与指标基线;识别全量扫描、热点查询、幂等缺失等问题。
- 第2-3周:引入游标分页与幂等键;开启压缩与批量;建立失败补偿作业。
- 第4-5周:事件模型与Outbox落地;接入MQ;将高频同步切换为事件驱动。
- 第6周:监控大屏+告警规则;回放与对账通道上线;SLA 验证与压测。
- 持续优化:冷热分层、索引重构、表分区、缓存命中率提升、成本与延迟双优化。
十二、与简道云进销存的实践结合
- 适配场景:商品主数据、订单状态回写、库存出入库事件同步到第三方系统(电商平台、ERP、财务系统等)。
- 推荐配置要点:
- Webhook:在简道云进销存内对“订单创建/审核通过/出库/入库”等节点配置回调,附带签名和重试策略。
- 批量API:下游按 Cursor 拉取近10分钟增量,使用 updated_at + id 的 keyset 分页,返回 next_cursor。
- 幂等:以单据号/流水号 + 版本作为幂等键;重复请求直接返回当前处理状态。
- 事件与补偿:保留7-14天事件重放窗口;每日夜间快照校验差异并自动补偿。
- 指标看板:在平台或外部监控中落地 events/sec、失败率、滞后、幂等命中率,形成可追踪链路。
- 官网与模板:简道云进销存提供可直接使用的进销存模板与对接能力,便于快速搭建与扩展。官网地址: https://s.fanruan.com/4mx3c;
十三、常见问题排查清单
- 重复单据/重复扣减:检查幂等键是否落库;确认回调重试是否使用相同 request_id。
- 漏数:确认游标条件是否为“> OR = AND id >”;检查时区与时钟同步(NTP)。
- 延迟飙升:是否在大事务/大促高峰;开启背压与限流;扩大批量但控制单包大小。
- 顺序错乱:同一聚合根分区键是否一致;是否跨分区导致并行破坏顺序。
- 对账不平:执行快照校验;查找差异事件并重放;核对异常窗口期间的补偿日志。
- 资源瓶颈:慢查询计划、缺索引、连接耗尽;JSON 序列化与网络压缩未开启。
十四、实例说明与数据支持
- 某零售中台改造数据:
- 将订单、出入库从轮询改为 CDC 事件,p95 延迟 18s → 2.7s。
- 引入 gzip + 批量 200/包,网络带宽峰值下降 58%。
- 幂等命中率 96%+,业务侧重试不再产生重复扣减。
- 每日快照对账 + 事件重放,使差异订单从千分之3降至万分之2。
- 可推广经验:
- 先治理“正确性”,再追求“极致时延”;正确性=幂等+顺序+补偿。
- 以“热点SKU/仓库”和“大单量客户”为切入点优先优化。
十五、总结与行动建议
- 关键结论:
- 以事件驱动的增量同步为主、批量快照为辅,能同时兼顾“时效、准确与成本”。
- 幂等、去重与游标分页是接口稳定性的三大基石。
- 以可观测和补偿机制闭环,保证可追溯、可恢复。
- 立即可做的清单:
- 落地 keyset 分页与幂等键;开启 gzip;批量读写。
- 建立统一事件模型与 Outbox;对接 MQ 并按聚合根分区。
- 上线指标与告警;搭建日对账与事件重放工具链。
- 在简道云进销存中配置 Webhook + 批量接口模板,先跑通“订单与库存”两条主链路,再向其它域扩展。
最后推荐:分享一个我们公司在用的进销存系统模板,需要的可以自取,可直接使用,也可以自定义编辑修改:https://s.fanruan.com/4mx3c
精品问答:
进销存数据接口优化的核心步骤有哪些?
我在使用进销存系统时,发现数据接口响应速度慢,影响了整体业务效率。具体来说,进销存数据接口优化的核心步骤都包括哪些?如何有针对性地提升接口性能?
进销存数据接口优化的核心步骤主要包括:
- 数据请求合并:减少接口调用次数,通过批量请求降低网络开销。
- 接口数据缓存:利用缓存技术(如Redis)减少数据库查询次数。
- 异步处理机制:采用异步接口或消息队列,提高系统处理并发能力。
- 数据压缩传输:启用GZIP等压缩技术,减少传输数据量。
- SQL语句优化:通过索引优化和避免复杂联表查询,提高数据库响应速度。 案例:某电商平台通过批量接口合并请求,接口调用次数减少60%,数据同步效率提升了40%。
如何通过技术手段提升进销存数据接口的数据同步效率?
我注意到进销存系统的数据同步效率直接影响库存和订单的准确性。有没有具体的技术手段,可以显著提升进销存数据接口的数据同步效率?
提升进销存数据接口同步效率的技术手段包括:
- 使用增量同步技术:只同步发生变更的数据,减少数据量。
- 实施数据压缩和传输协议优化:例如启用HTTP/2协议,提升传输效率。
- 采用消息队列(如Kafka、RabbitMQ):实现异步数据同步,缓解接口压力。
- 利用分布式缓存和CDN技术:提高数据读取速度。 数据表: | 技术手段 | 优势 | 案例效果 | |----------------|-----------------------|--------------------------| | 增量同步 | 减少同步数据量70%以上 | 同步延迟降低50% | | 消息队列 | 异步处理提升并发能力 | 峰值时系统稳定性提升30% |
进销存数据接口优化中常见的性能瓶颈有哪些?
我在分析进销存数据接口时,发现有些接口响应时间特别长,影响业务流程。常见的性能瓶颈具体体现在哪些方面?如何判断和定位这些瓶颈?
进销存数据接口常见性能瓶颈包括:
- 数据库查询慢:缺少索引或复杂多表联查导致查询时间长。
- 网络传输延迟:大数据量传输时带宽有限。
- 接口设计不合理:频繁调用小接口导致接口调用次数过多。
- 资源竞争:服务器CPU、内存或IO资源不足。 定位方式:
- 使用APM工具(如New Relic、SkyWalking)监控接口响应时间。
- 查看SQL执行计划,优化慢查询。
- 通过网络抓包分析数据包大小和传输时间。 案例:某企业通过优化SQL索引,将关键接口平均响应时间从2秒缩短至0.5秒。
如何结合案例理解进销存数据接口优化的实际效果?
我想更直观地了解进销存数据接口优化的实际效果,特别是通过真实案例分析,能否分享一些数据和经验?这样我能更好地理解优化带来的业务提升。
结合实际案例理解进销存数据接口优化效果: 案例分析:某零售企业实施接口优化前后对比数据
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 接口响应时间 | 1.8秒 | 0.8秒 | 55.6% |
| 数据同步延迟 | 5分钟 | 1分钟 | 80% |
| 系统并发处理能力 | 500TPS | 1200TPS | 140% |
| 经验总结: |
- 通过接口合并和异步处理,显著提升同步效率。
- 优化数据库查询和缓存策略,降低响应时间。
- 监控和持续调优是保持高效同步的关键。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/266344/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号