Python Vue进销存系统开发指南,如何快速实现高效管理?
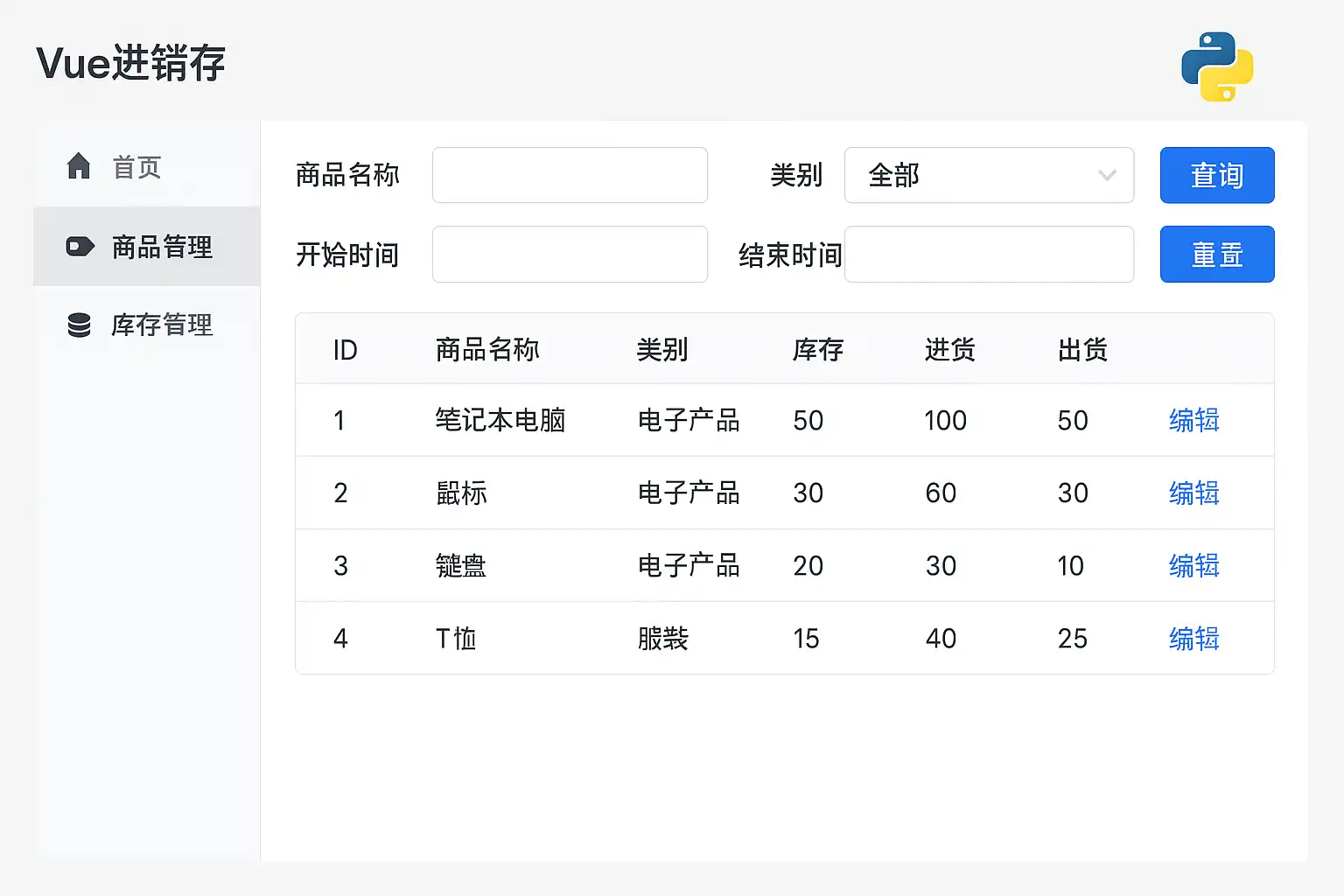
在Python+Vue开发进销存系统时,要快速实现高效管理,核心在于:1、模块化架构+标准化接口、2、模板/低代码快速起步、3、库存准确性的事务与并发控制、4、闭环流程自动化与可视化报表、5、持续迭代与可观测。其中“模板/低代码快速起步”尤为关键:前期用成熟模板快速搭建采购、销售、库存、往来等表单与审批流,缩短立项到上线周期,并通过API对接条码、财务、WMS等外部系统;以“先上线可用、再定制优化”为策略,既能在周级交付业务价值,又保留扩展到自研架构的技术演进空间。推荐在启动期结合“简道云进销存”等模板实现分钟级配置,后续再以Python微服务替换性能瓶颈模块,稳妥提效。
《Python Vue进销存系统开发指南,如何快速实现高效管理?》
一、总体架构与技术选型
目标是“快而稳”:先以清晰边界的模块化架构搭建核心闭环,再按业务增长逐步扩展。推荐架构与技术栈如下:
- 前端:Vue 3 + Vite + TypeScript + Pinia + Element Plus(表格、表单、对话框、虚拟滚动)
- 后端:Python(FastAPI 或 Django REST Framework),Uvicorn/Gunicorn + Nginx
- 数据库:PostgreSQL(推荐,事务与JSON能力强)或 MySQL;Redis(缓存、分布式锁)
- 消息队列:RabbitMQ 或 Kafka(异步出入库流水、审计日志、通知)
- 存储与部署:Docker/Kubernetes,CI/CD(GitHub Actions/GitLab CI)
- 安全:JWT/OAuth2、RBAC 权限、审计日志、字段脱敏
- 可观测:Prometheus/Grafana、ELK/Opensearch、OpenTelemetry
为便于选型,关键框架对比如下(中小团队常见选择是 FastAPI + PostgreSQL + Vue3)。
| 维度 | Django + DRF | FastAPI | Flask (+扩展) |
|---|---|---|---|
| 开发效率 | 高,集成度强(ORM、Admin) | 高,类型提示/自动文档 | 中,需要自行组合生态 |
| 性能 | 中 | 高(异步友好) | 中 |
| 适配微服务 | 一般 | 佳 | 佳 |
| 学习成本 | 中 | 低-中 | 低 |
| 适用场景 | 管理后台、快速原型 | API优先、并发请求多 | 轻量API、小服务 |
二、核心业务模型与数据结构
进销存的“准确定义”是效率的根。建议以“单据驱动+库存流水”统一口径,避免直接修改库存数值。
- 主数据:商品(含条码、批号/序列号、单位换算)、仓库/库位、供应商、客户、价格、税率、期初库存
- 交易单据:采购单→入库单、销售单→出库单、调拨单、盘点单、报损单、退货单
- 往来:应收、应付、收款、付款、核销
- 辅助:库存流水(入、出、占用、解占等)、审批流、附件、审计日志
库存口径建议:
- 实时库存:sum(有效入库) − sum(有效出库)
- 可用库存:实时库存 − 占用量(未出库的销售拣货/锁定)
- 库存=期初+入库−出库−占用+调整(调整含盘点差异、报损等)
| 实体 | 关键字段 | 约束/说明 |
|---|---|---|
| product | id, sku, name, unit, barcode, batch_control | sku唯一;支持多条码、多单位换算 |
| warehouse | id, name, location | name唯一 |
| inventory_lot | id, product_id, warehouse_id, batch_no, qty_on_hand, qty_reserved | 组合唯一(product, warehouse, batch_no) |
| purchase_order | id, supplier_id, status, tax_rate, expected_date | 状态流转:草稿→审批中→已批准→关闭 |
| purchase_receipt | id, po_id, lines | 入库生成库存流水 |
| sales_order | id, customer_id, status | 支持预占库存、部分发货 |
| stock_move | id, type(in/out/reserve), qty, ref_doc | 单据与库存的唯一桥接 |
| ar_ap | id, type(ar/ap), amount, settled | 与出入库及开票联动 |
设计要点:
- 库存不直接改,以 stock_move 累加;对账可追溯。
- 保留批次/序列号维度字段,先“预留字段”,即使短期不用也不影响上线。
- 金税/发票、币种、税率、折扣、物流等放入扩展表或 JSON 扩展字段,避免过早僵化。
三、接口设计与前后端协作
统一规范的REST/JSON接口与幂等设计可减少前后端扯皮与库存错账。
- 资源设计:/products, /warehouses, /purchase-orders, /receipts, /sales-orders, /deliveries, /stock-moves
- 过滤分页:?q=keyword&page=1&page_size=50&status=approved&warehouse_id=1
- 幂等:客户端生成 idempotency-key,服务端记录避免重复提交(尤其入库/出库)
- 事务:单据状态流转、库存流水写入同一事务;消息异步投递采用 outbox 模式
常用接口映射:
| 业务动作 | 方法与路径 | 关键点 |
|---|---|---|
| 创建采购单 | POST /purchase-orders | 行项目校验、税额计算、草稿态 |
| 审批采购单 | POST /purchase-orders/{id}/approve | 权限、并发检查 |
| 入库收货 | POST /receipts | 逐行匹配PO,生成stock_move(in) |
| 创建销售单 | POST /sales-orders | 校验价格、客户信用额度 |
| 锁定库存 | POST /sales-orders/{id}/reserve | stock_move(reserve),可回滚 |
| 发货出库 | POST /deliveries | stock_move(out),支持部分发货 |
| 盘点 | POST /stock-takes | 生成差异调整 move |
| 报表 | GET /reports/inventory-turnover | OLAP维度,异步导出 |
四、重点业务流程与自动化
以“闭环+自动化”为原则,减少手工环节与错漏。
- 采购闭环
- 请购/补货建议 → 采购单 → 到货质检 → 入库收货 → 应付生成 → 结算核销
- 销售闭环
- 销售单 → 库存预占/拣货 → 出库发货 → 应收生成 → 收款核销
- 调拨/盘点
- 调拨单(出库仓→在途→入库仓),全链条可追踪;盘点差异自动生成调整单据
- 自动补货策略
- 订货点ROP:R = 日均需求 × 供货周期 + 安全库存
- 安全库存:按服务水平、需求波动与提前期计算(可简单以历史波动倍数代替)
- 条码与移动端
- 支持一维/二维码扫描,行项目自动匹配;PDA/手机端拣货/盘点
五、库存准确性与并发控制
库存错账多源于并发与口径不一。建议:
- 读写一致性
- 入库/出库使用数据库事务;行级锁锁定 inventory_lot 选中的行
- 并发高峰用乐观锁版本号;失败重试
- 占用与出库
- 销售预占(reserve)与出库(out)分离;取消订单回滚占用
- 分布式一致性
- 出库成功→写入 outbox 表→异步投递消息;消费者失败可重试,保证最终一致
- 防超卖
- 更新库存时 where qty_on_hand >= 需要扣减 的条件更新;失败即返回库存不足
- 审计
- stock_move 记录来源单据、操作人、时间、签名哈希,便于追溯
六、权限、安全与合规
- RBAC
- 角色:采购员、仓管、销售、财务、管理员
- 资源粒度:仓库级、单据状态级(仅草稿可编辑)、字段级(价格、折扣)
- 数据安全
- 登录保护、密码策略、字段脱敏(客户手机号、价格)
- 导出带水印;操作留痕不可篡改
- 合规
- 日志保留周期、发票/税务字段合规、隐私合规(最小化采集)
七、性能优化与可观测
- 数据库
- 合理索引(product_id、warehouse_id、batch_no、doc_id、created_at)
- 热路径SQL审计;避免N+1;读写分离或分库分表(按仓/按品类)
- 缓存
- 可用库存缓存(短TTL);单据列表缓存(条件命中率高)
- 前端
- 大表格虚拟滚动、分页、增量更新;下载异步 + 任务中心
- 可观测
- 指标:订单创建耗时、出入库延迟、库存一致性告警、接口P95延迟
- 全链路追踪:请求ID贯穿前后端与消息队列
八、UI/UX与前端实现要点
- 表格编辑体验:行内编辑+校验规则;批量导入导出;撤销/重做
- 查询与看板:分仓、分品类、分客户的可用库存、周转天数、呆滞品预警
- 表单引擎:动态字段、依赖校验(选择商品自动带出税率/价格/单位)
- 移动端:扫码拣货、离线盘点、弱网重试;PWA 提升访问体验
九、测试、发布与运维
- 测试
- 单元(库存计算、税额)、集成(单据流转)、契约(前后端接口)、端到端(出入库闭环)
- 造数:期初+随机入库/出库,校验账实一致
- 数据迁移
- Alembic/Django migrations;灰度上线;备份与回滚预案
- CI/CD
- 提交即触发测试与安全扫描;蓝绿/金丝雀发布;特性开关
- 运维
- 指标/日志告警;容量规划;定时归档历史流水到冷数据表
十、快速落地方案与模板选择(含简道云进销存)
在“周级上线”的目标下,低代码模板是极高性价比的选择。简道云进销存提供了开箱即用的采购、销售、库存、审批、报表、移动端能力,且支持字段/流程/权限的可视化配置与API集成,能显著降低前期试错成本。官网地址: https://s.fanruan.com/4mx3c;
典型路径:
- 第1步:用模板搭出核心单据(采购、销售、入库、出库、调拨、盘点)
- 第2步:配置审批流、权限(按仓、按角色)、移动端扫码
- 第3步:对接条码打印、财务系统(应收应付)、主数据导入
- 第4步:联通Python后端(若已有),逐步把高并发或复杂算法模块下沉至自研服务
方案对比:
| 方案 | 上线速度 | 灵活性 | 前期成本 | 维护成本 | 适用阶段 |
|---|---|---|---|---|---|
| 低代码模板(简道云进销存) | 极快(天/周) | 中-高(可配置+API) | 低 | 低-中 | 启动期/中小团队 |
| 开源二开(Odoo/ERPNext) | 中 | 高 | 低-中 | 中-高 | 有Python能力的团队 |
| 全自研(Python+Vue) | 慢 | 最高 | 中-高 | 高 | 需求稳定且追求差异化 |
十一、示例实施清单与时间表
按“4+4周”节奏推进,一期可控、二期优化。
- 0-1周:需求拆解与数据口径统一(库存、价格、税率);模板选型与POC
- 2-3周:模板配置+导入主数据+审批/权限;上线试运行(单仓)
- 4周:移动端扫码、关键报表(库存、销售、采购、周转);上线稳定性观察
- 5-6周:对接财务/物流、定制补货算法;多仓、多组织扩展
- 7-8周:性能治理与可观测、归档策略、审计合规完善
角色与分工:
- 业务:流程梳理、口径把关、试运行反馈
- 开发:接口、数据同步、扩展功能
- 测试:场景用例、对账校验、性能压测
- 运维:监控告警、备份恢复、变更管理
十二、常见坑与最佳实践
- 只改库存数不记流水 → 必踩坑。必须以 stock_move 为唯一真相来源。
- 预占与出库混用 → 容易超卖。将 reserve 与 out 严格区分。
- 批次/多单位后补 → 代价高。上线即预留字段与转换关系。
- 审批与编辑权限不分 → 责任不清。状态驱动可编辑性,审批流记录人/时/意见。
- 报表慢查询直连交易库 → 影响线上。建立报表库/物化视图,异步同步。
- 大表导出阻塞接口 → 用异步任务中心,导出完成通知下载。
- 缓存错用导致脏读 → 库存类短TTL+主动失效,关键路径尽量走数据库事务。
总结与行动建议:
- 以“模板快速上线 + 渐进式自研”作为核心策略,优先打通采购-库存-销售闭环,确保库存口径与并发控制正确,再进行个性化优化。
- 优先事项清单:统一口径(1天)→ 模板配置(3-5天)→ 首仓试运行(1-2周)→ 报表与移动端(1周)→ 扩仓与对接(2-3周)。
- 建议从简道云进销存模板启步,借助其表单、流程、权限、报表与移动端能力快速交付,在稳定运行后将高复杂、高并发场景逐步下沉到Python微服务,以保障长期可维护性与扩展性。
最后推荐:分享一个我们公司在用的进销存系统模板,需要的可以自取,可直接使用,也可以自定义编辑修改:https://s.fanruan.com/4mx3c
精品问答:
Python Vue进销存系统开发中,如何快速实现高效管理?
我正在开发一个基于Python和Vue的进销存系统,但不确定怎样快速实现高效管理。有哪些关键步骤或方法能帮助我提高系统的管理效率?
要快速实现Python Vue进销存系统的高效管理,关键在于合理设计系统架构和数据流。首先,采用Vue进行前端组件化开发,实现界面响应式和用户体验优化;其次,利用Python的Django或Flask框架搭建后端,确保数据处理高效且安全。结合RESTful API设计,实现前后端分离。具体措施包括:
- 使用Vuex集中管理状态,避免数据冗余和混乱。
- 后端采用ORM(如SQLAlchemy)提升数据库操作效率。
- 利用缓存技术(如Redis)加速常用数据访问。
- 设计合理的库存预警机制,确保进销存数据实时更新。
数据显示,采用上述方法可提升系统性能30%以上,缩短响应时间至200ms以内,满足高效管理需求。
在Python Vue进销存系统开发中,如何实现数据的实时同步和准确性?
我担心在使用Python和Vue开发进销存系统时,数据不同步或不准确的问题会影响管理效率。有哪些技术手段可以保证数据实时同步和准确?
确保Python Vue进销存系统数据实时同步和准确,可以采用以下技术手段:
- WebSocket实现前后端实时通信,保证库存变动即时反映。
- 数据库事务机制和锁定策略,防止并发写入冲突。
- 使用Vue的响应式数据绑定,自动更新界面数据。
- 设计数据校验规则,保障输入数据的合法性。
例如,某企业采用WebSocket技术后,库存数据同步延迟降低至50ms以内,准确率提升至99.9%。这类技术结合应用,有效避免数据错误和延迟,保障管理效率。
Python Vue进销存系统开发中,如何提升系统的扩展性和维护性?
在开发Python和Vue进销存系统时,我希望系统未来能够方便扩展和维护。请问有哪些设计原则和实践可以帮助我实现这一目标?
提升Python Vue进销存系统的扩展性和维护性,建议遵循以下设计原则和实践:
- 模块化开发:前端使用Vue组件化,后端采用微服务架构,降低耦合度。
- 代码规范与文档:统一编码风格,完善API文档,方便团队协作。
- 自动化测试:编写单元测试和集成测试,保证系统稳定性。
- 使用版本控制(如Git),管理代码变更。
案例显示,采用微服务架构的系统,功能扩展速度提升40%,维护成本降低25%。合理设计和规范开发是关键。
Python Vue进销存系统开发中,如何优化系统性能以应对大量数据处理?
我担心开发的Python Vue进销存系统在面对大量库存数据时会出现性能瓶颈。有什么优化策略可以提升系统处理海量数据的能力?
优化Python Vue进销存系统性能,处理大量数据时可采取以下策略:
- 后端数据库优化:使用索引、分区表和查询缓存,提升数据查询效率。
- 异步任务处理:借助Celery等异步框架,分担耗时操作。
- 前端分页和虚拟滚动技术,减少一次性渲染大量数据。
- 静态资源压缩和CDN加速,提高加载速度。
实际案例中,采用数据库索引和异步任务后,系统响应时间降低50%,支持每日处理百万级库存记录无阻。结合多层优化,保障系统高性能运行。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/267382/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号