SQL进销存管理技巧详解,如何高效实现库存控制?
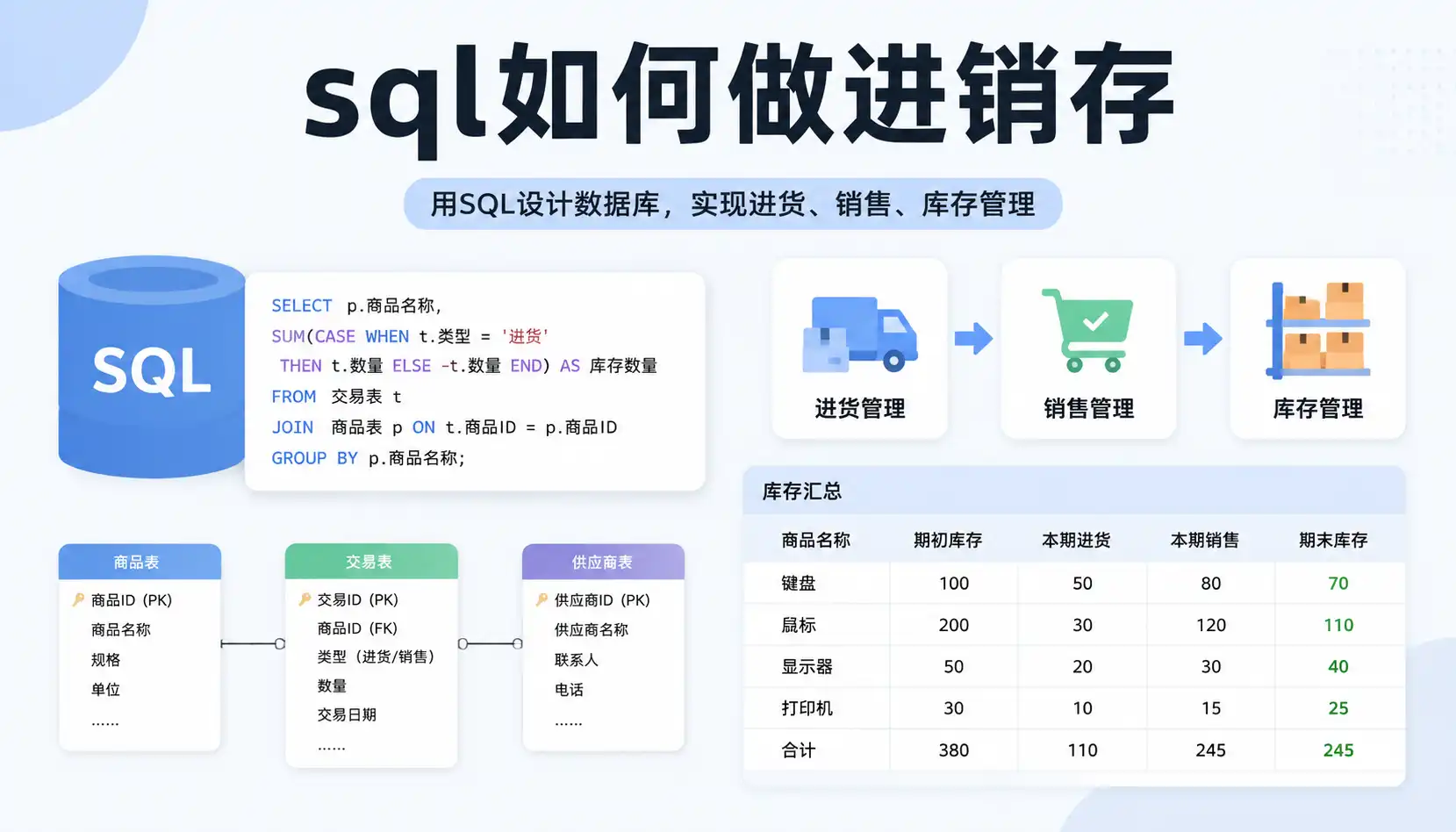
通过 SQL 设计进销存系统,可以实现高度可控的库存管理、自动化的入库出库记录以及清晰的库存台账。合理划分商品、仓库、单据、流水等数据表,再配合视图、触发器和存储过程等 SQL 技巧,就能在 MySQL、PostgreSQL、SQL Server 等数据库中搭建出稳定的进销存管理方案。核心就是用结构化数据管理“入库、出库、库存结余与成本”,并保证每一笔业务都可追溯、可统计、可审计。结合进销存软件或模板(如云端的进销存系统模板)还能大幅减少开发工作量,让企业更专注于业务策略和库存优化。
《SQL进销存管理技巧详解,如何高效实现库存控制?》
SQL进销存管理技巧详解,如何高效实现库存控制?
🧩 一、进销存与库存控制的核心逻辑
1. 进销存系统的基本概念
在利用 SQL 搭建进销存管理系统之前,先要明确进、销、存的业务含义,并把它抽象成可以用 SQL 表结构表示的数据模型:
- 进(采购入库 / 生产入库)
- 供应商 → 采购订单 → 入库单 → 增加库存
- 销(销售出库 / 领料出库)
- 客户 → 销售订单 → 出库单 → 减少库存
- 存(库存状态)
- 某时间点下,各仓库、各商品的库存数量、可用库存、占用库存、在途库存等
这些动作都可以归结为库存变动流水,因此在 SQL 进销存管理中,数据库的核心就是:
用标准化表结构记录每一次库存变动(入库、出库、调拨、盘点),再通过 SQL 查询聚合出当前库存、历史库存和各种报表。
2. SQL 在进销存管理中的角色
用 SQL 管理进销存系统,有几大优势:
- 数据结构清晰:用规范化设计管理商品、仓库、单据、明细。
- 查询灵活:可以根据业务场景编写多种库存控制 SQL,比如安全库存预警、滞销品分析等。
- 可扩展性强:当业务扩展到多仓库、多公司、多币种时,只要表结构设计合理,扩展成本较低。
- 与其他系统集成方便:ERP、财务系统都以 SQL 或数据接口为基础。
3. 高效库存控制的关键指标
在设计 SQL 进销存系统时,需围绕几个库存控制的核心指标构建数据结构与 SQL:
- 实时库存(On-hand Quantity)
- 可用库存(Available Quantity) = 实时库存 - 已承诺未出库数量
- 安全库存(Safety Stock)
- 在途库存(In-transit Stock):已采购未入库或在调拨中的数量
- 批次/序列号追踪:食品、药品、电子元件等行业尤为重要
- 成本:移动加权平均、标准成本、FIFO 等
这些指标最终都要通过 SQL 查询来实现,所以从一开始就要围绕这些指标设计表结构。
📦 二、SQL 进销存数据模型整体设计思路
1. 核心表结构模块概览
典型 SQL 进销存系统的表结构,可以划分为以下模块(以英文表名为例,方便跨数据库环境):
| 模块 | 示例表名 | 关键内容 |
|---|---|---|
| 商品与分类 | products, categories | 商品基本信息、分类、计量单位 |
| 仓库与库位 | warehouses, locations | 仓库、库区、货位信息 |
| 单据主表 | purchase_orders, sales_orders, stock_transfers | 采购单、销售单、调拨单头信息 |
| 单据明细表 | *_details | 每个单据包含的商品明细 |
| 库存流水 | inventory_transactions | 入库、出库、调拨、盘点等流水 |
| 库存快照/台账 | inventory_balances | 某日/某时刻的库存结余 |
| 往来单位 | suppliers, customers | 供应商与客户信息 |
| 价格与成本 | price_lists, cost_layers | 销售价格、成本记录 |
这种模块化拆分,既方便通过 SQL 管理进销存,又能将业务逻辑分解清楚,便于后期维护与扩展。
2. 规范化 vs. 反规范化:如何在 SQL 中平衡性能与灵活性
为实现高效库存控制,数据模型设计的取舍尤为关键:
- 规范化优点:消除冗余,结构清晰,更新一致性高。
- 规范化缺点:复杂查询时需要 JOIN 多表,性能可能受影响。
- 反规范化:在一些高频查询的场景下,可以预先汇总,如维护一张
inventory_balances表,以减少每次查询都从流水表进行汇总。
典型的折中方案:
- 使用高度规范化的流水表记录所有真实交易。
- 使用库存结余表作为统计结果缓存,通过触发器或批处理同步更新。
- 关键查询(如当前库存、可用库存)优先使用结余表,必要时才回溯流水表。
🧱 三、商品与仓库表结构设计及 SQL 实现
1. 商品基础信息表设计(products)
商品表是整个 SQL 进销存系统的数据基石:
CREATE TABLE products (product_id BIGINT PRIMARY KEY,sku VARCHAR(50) NOT NULL UNIQUE, -- 货号 / SKUproduct_name VARCHAR(255) NOT NULL,category_id BIGINT,unit VARCHAR(20) NOT NULL, -- 基本计量单位,如 pcs, kgbarcode VARCHAR(100),status VARCHAR(20) DEFAULT 'ACTIVE', -- ACTIVE, INACTIVEcreated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,CONSTRAINT fk_products_categoryFOREIGN KEY (category_id) REFERENCES categories(category_id));优化要点:
- 建立
sku唯一索引,方便通过商品编码快速查询。 - 增加
status字段控制启用/停用商品,而不是直接删除,提高数据可追溯性。 - 如需支持多计量单位,可单独设计
product_units表。
2. 仓库与库位表结构设计
仓库表 warehouses:
CREATE TABLE warehouses (warehouse_id BIGINT PRIMARY KEY,warehouse_code VARCHAR(50) NOT NULL UNIQUE,warehouse_name VARCHAR(255) NOT NULL,address VARCHAR(255),status VARCHAR(20) DEFAULT 'ACTIVE',created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP);库位表 locations(可选):
CREATE TABLE locations (location_id BIGINT PRIMARY KEY,warehouse_id BIGINT NOT NULL,location_code VARCHAR(50) NOT NULL,location_name VARCHAR(255),status VARCHAR(20) DEFAULT 'ACTIVE',created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,CONSTRAINT fk_locations_warehouseFOREIGN KEY (warehouse_id) REFERENCES warehouses(warehouse_id));索引设计建议:
warehouses.warehouse_code建唯一索引。locations(warehouse_id, location_code)建组合索引,提升按仓库+库位查询库存的性能。
📑 四、入库、出库、调拨单据的 SQL 表结构与设计要点
1. 单据主表与明细表示例
以采购入库与销售出库为例,可以采用统一的设计风格。
1)采购单主表与明细表(purchase_orders 与 purchase_order_details)
CREATE TABLE purchase_orders (po_id BIGINT PRIMARY KEY,po_number VARCHAR(50) NOT NULL UNIQUE,supplier_id BIGINT NOT NULL,warehouse_id BIGINT NOT NULL,order_date DATE NOT NULL,expected_date DATE,status VARCHAR(20) NOT NULL, -- DRAFT, APPROVED, RECEIVED, CLOSED, CANCELLEDtotal_amount DECIMAL(18, 2),currency VARCHAR(10),created_by BIGINT,created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,CONSTRAINT fk_po_supplierFOREIGN KEY (supplier_id) REFERENCES suppliers(supplier_id),CONSTRAINT fk_po_warehouseFOREIGN KEY (warehouse_id) REFERENCES warehouses(warehouse_id));CREATE TABLE purchase_order_details (po_detail_id BIGINT PRIMARY KEY,po_id BIGINT NOT NULL,product_id BIGINT NOT NULL,quantity DECIMAL(18, 4) NOT NULL,unit_price DECIMAL(18, 4) NOT NULL,tax_rate DECIMAL(5, 2),line_amount DECIMAL(18, 2),received_qty DECIMAL(18, 4) DEFAULT 0,status VARCHAR(20) DEFAULT 'OPEN', -- OPEN, PARTIAL, CLOSEDCONSTRAINT fk_pod_poFOREIGN KEY (po_id) REFERENCES purchase_orders(po_id),CONSTRAINT fk_pod_productFOREIGN KEY (product_id) REFERENCES products(product_id));2)销售单主表与明细表(sales_orders 与 sales_order_details)
CREATE TABLE sales_orders (so_id BIGINT PRIMARY KEY,so_number VARCHAR(50) NOT NULL UNIQUE,customer_id BIGINT NOT NULL,warehouse_id BIGINT NOT NULL,order_date DATE NOT NULL,delivery_date DATE,status VARCHAR(20) NOT NULL, -- DRAFT, CONFIRMED, SHIPPED, CLOSED, CANCELLEDtotal_amount DECIMAL(18, 2),currency VARCHAR(10),created_by BIGINT,created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP);CREATE TABLE sales_order_details (so_detail_id BIGINT PRIMARY KEY,so_id BIGINT NOT NULL,product_id BIGINT NOT NULL,quantity DECIMAL(18, 4) NOT NULL,unit_price DECIMAL(18, 4) NOT NULL,tax_rate DECIMAL(5, 2),line_amount DECIMAL(18, 2),shipped_qty DECIMAL(18, 4) DEFAULT 0,status VARCHAR(20) DEFAULT 'OPEN', -- OPEN, PARTIAL, CLOSEDCONSTRAINT fk_sod_soFOREIGN KEY (so_id) REFERENCES sales_orders(so_id),CONSTRAINT fk_sod_productFOREIGN KEY (product_id) REFERENCES products(product_id));2. 调拨单据设计(仓库间转移)
调拨单对库存控制影响很大,它不涉及采购/销售金额,但影响多个仓库的实物库存。
CREATE TABLE stock_transfers (transfer_id BIGINT PRIMARY KEY,transfer_number VARCHAR(50) NOT NULL UNIQUE,from_warehouse BIGINT NOT NULL,to_warehouse BIGINT NOT NULL,transfer_date DATE NOT NULL,status VARCHAR(20) NOT NULL, -- DRAFT, IN_TRANSIT, COMPLETED, CANCELLEDcreated_by BIGINT,created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP);CREATE TABLE stock_transfer_details (transfer_detail_id BIGINT PRIMARY KEY,transfer_id BIGINT NOT NULL,product_id BIGINT NOT NULL,quantity DECIMAL(18, 4) NOT NULL,shipped_qty DECIMAL(18, 4) DEFAULT 0,received_qty DECIMAL(18, 4) DEFAULT 0,CONSTRAINT fk_std_transferFOREIGN KEY (transfer_id) REFERENCES stock_transfers(transfer_id),CONSTRAINT fk_std_productFOREIGN KEY (product_id) REFERENCES products(product_id));🔄 五、库存流水表与实时库存计算的 SQL 技巧
1. 设计统一的库存流水表(inventory_transactions)
库存流水是进销存系统中最关键的基础表,用于记录所有库存变动记录:
CREATE TABLE inventory_transactions (transaction_id BIGINT PRIMARY KEY,transaction_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,warehouse_id BIGINT NOT NULL,location_id BIGINT,product_id BIGINT NOT NULL,quantity_change DECIMAL(18, 4) NOT NULL, -- 入库为正,出库为负transaction_type VARCHAR(30) NOT NULL, -- PURCHASE_IN, SALES_OUT, TRANSFER_OUT, TRANSFER_IN, ADJUSTMENT, STOCKTAKEref_document_type VARCHAR(30), -- 如 PO, SO, TRANSFER, ADJUSTMENTref_document_id BIGINT,ref_document_line BIGINT,batch_number VARCHAR(100),remarks VARCHAR(255),created_by BIGINT,created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,CONSTRAINT fk_it_warehouseFOREIGN KEY (warehouse_id) REFERENCES warehouses(warehouse_id),CONSTRAINT fk_it_locationFOREIGN KEY (location_id) REFERENCES locations(location_id),CONSTRAINT fk_it_productFOREIGN KEY (product_id) REFERENCES products(product_id));设计要点:
- 统一入口:所有库存变动统一记入该表,方便后期用 SQL 查询分析。
- 正负号规则:约定入库为正数,出库为负数,简化库存计算。
transaction_type+ref_document_type+ref_document_id支持从业务单据追溯库存变动来源。
2. 基于流水表计算实时库存的 SQL 语句
按仓库和商品汇总当前库存:
SELECTit.warehouse_id,it.product_id,SUM(it.quantity_change) AS current_stockFROMinventory_transactions itGROUP BYit.warehouse_id,it.product_id;按仓库 + 库位 + 批次汇总库存:
SELECTit.warehouse_id,it.location_id,it.product_id,it.batch_number,SUM(it.quantity_change) AS current_stockFROMinventory_transactions itGROUP BYit.warehouse_id,it.location_id,it.product_id,it.batch_number;在业务中,这类 SQL 会被频繁调用,建议:
- 为
warehouse_id、product_id、location_id建立组合索引; - 大数据量时考虑使用物化视图或库存结余表缓存结果(后面章节会详述)。
3. 入库、出库时的库存流水插入示例
采购入库生成库存流水示例:
INSERT INTO inventory_transactions (transaction_id,transaction_time,warehouse_id,product_id,quantity_change,transaction_type,ref_document_type,ref_document_id,ref_document_line,batch_number,created_by)SELECTNEXTVAL('seq_inventory_tx') AS transaction_id,NOW() AS transaction_time,po.warehouse_id,pod.product_id,pod.quantity AS quantity_change,'PURCHASE_IN' AS transaction_type,'PO' AS ref_document_type,po.po_id AS ref_document_id,pod.po_detail_id AS ref_document_line,NULL AS batch_number,:current_user_id AS created_byFROMpurchase_orders poJOINpurchase_order_details pod ON po.po_id = pod.po_idWHEREpo.po_id = :po_id AND po.status = 'RECEIVED';销售出库生成库存流水示例(注意 quantity 为负):
INSERT INTO inventory_transactions (transaction_id,transaction_time,warehouse_id,product_id,quantity_change,transaction_type,ref_document_type,ref_document_id,ref_document_line,batch_number,created_by)SELECTNEXTVAL('seq_inventory_tx'),NOW(),so.warehouse_id,sod.product_id,-sod.quantity AS quantity_change,'SALES_OUT','SO',so.so_id,sod.so_detail_id,NULL,:current_user_idFROMsales_orders soJOINsales_order_details sod ON so.so_id = sod.so_idWHEREso.so_id = :so_id AND so.status = 'SHIPPED';4. 使用事务与锁控制库存一致性
在 SQL 进销存系统中,必须通过数据库事务确保库存的一致性,避免出现负库存或重复出库。
典型库存扣减流程(伪代码):
BEGIN;
-- 1. 查询当前库存(行级锁 FOR UPDATE)SELECTSUM(quantity_change) AS current_stockFROMinventory_transactionsWHEREwarehouse_id = :warehouse_idAND product_id = :product_idFOR UPDATE;
-- 2. 判断是否有足够库存IF current_stock < :deduct_qty THENROLLBACK;RAISE ERROR '库存不足';END IF;
-- 3. 插入出库流水INSERT INTO inventory_transactions (...);
COMMIT;通过 FOR UPDATE 行锁,在并发出库时,可以避免多个事务同时读取同一库存并各自扣减而导致超卖。
📊 六、库存结余表与性能优化的 SQL 实战
1. 库存结余表(inventory_balances)设计
当库存流水较多时,每次实时汇总会影响性能。可引入一张库存结余表:
CREATE TABLE inventory_balances (warehouse_id BIGINT NOT NULL,location_id BIGINT,product_id BIGINT NOT NULL,batch_number VARCHAR(100),balance_qty DECIMAL(18, 4) NOT NULL DEFAULT 0,last_updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (warehouse_id, location_id, product_id, batch_number));使用建议:
- 将
location_id和batch_number允许为 NULL,用统一主键约束做组合。 - 每次库存流水发生时,同步更新结余表,而不是事后全表重算。
2. 使用触发器自动更新库存结余表(适用于中小规模)
以 PostgreSQL 为例,实现库存流水插入时自动更新 inventory_balances:
CREATE OR REPLACE FUNCTION fn_update_inventory_balance()RETURNS TRIGGER AS $$BEGINUPDATE inventory_balancesSETbalance_qty = balance_qty + NEW.quantity_change,last_updated_at = NOW()WHEREwarehouse_id = NEW.warehouse_idAND COALESCE(location_id, 0) = COALESCE(NEW.location_id, 0)AND product_id = NEW.product_idAND COALESCE(batch_number, '') = COALESCE(NEW.batch_number, '');
IF NOT FOUND THENINSERT INTO inventory_balances (warehouse_id, location_id, product_id, batch_number, balance_qty, last_updated_at) VALUES (NEW.warehouse_id, NEW.location_id, NEW.product_id, NEW.batch_number,NEW.quantity_change, NOW());END IF;
RETURN NEW;END;$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_inventory_transactions_after_insertAFTER INSERT ON inventory_transactionsFOR EACH ROWEXECUTE FUNCTION fn_update_inventory_balance();通过这种触发器机制,可以确保流水与结余表保持同步,从而实现:
- 读取当前库存 → 直接查
inventory_balances,性能更好。 - 需要审计或分析 → 回溯
inventory_transactions。
3. 批处理同步模式(适合大数据量、高并发)
在高并发且数据量极大的场景,实时触发器可能成为瓶颈,可以改用批处理或定时任务:
- 每隔 N 分钟/小时,对增量流水进行汇总,更新结余表。
- 或者为每条流水记录一个
processed标志,定时任务聚合处理。
示例:每小时同步一次库存结余(简化示意):
INSERT INTO inventory_balances (warehouse_id, location_id, product_id, batch_number, balance_qty, last_updated_at)SELECTwarehouse_id,location_id,product_id,batch_number,SUM(quantity_change) AS balance_qty,NOW() AS last_updated_atFROMinventory_transactionsGROUP BYwarehouse_id, location_id, product_id, batch_numberON CONFLICT (warehouse_id, location_id, product_id, batch_number)DO UPDATE SETbalance_qty = EXCLUDED.balance_qty,last_updated_at = EXCLUDED.last_updated_at;🧮 七、成本核算与 FIFO/加权平均的 SQL 实现思路
库存控制不仅关注数量,还需要准确的库存成本,特别是财务对账。
1. 移动加权平均成本(Moving Average)
核心逻辑:
每次入库(采购入库、生产入库)后,重新计算该商品的平均成本:
新平均成本 = (原数量 × 原成本 + 入库数量 × 入库单价) ÷ (原数量 + 入库数量)
可以在 SQL 中用成本表 product_costs 记录最新平均成本:
CREATE TABLE product_costs (product_id BIGINT PRIMARY KEY,avg_cost DECIMAL(18, 6) NOT NULL DEFAULT 0,last_qty DECIMAL(18, 4) NOT NULL DEFAULT 0,last_updated_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP);入库时更新平均成本示例(伪 SQL):
BEGIN;
SELECT avg_cost, last_qtyINTO v_old_cost, v_old_qtyFROM product_costsWHERE product_id = :product_idFOR UPDATE;
v_new_qty := v_old_qty + :in_qty;v_new_cost := (v_old_cost * v_old_qty + :in_price * :in_qty) / v_new_qty;
UPDATE product_costsSETavg_cost = v_new_cost,last_qty = v_new_qty,last_updated_at = NOW()WHEREproduct_id = :product_id;
COMMIT;出库时,根据 avg_cost 计算出库成本,实现成本结转。
2. FIFO 成本法的 SQL 思路
FIFO(先进先出)要求按入库批次顺序扣减库存:
- 需要维护一个
cost_layers表,记录每次入库形成的成本层。 - 出库时,从最早的未耗尽成本层开始扣减,用 SQL 事务保证顺序扣减。
成本层表结构示例:
CREATE TABLE cost_layers (layer_id BIGINT PRIMARY KEY,product_id BIGINT NOT NULL,warehouse_id BIGINT NOT NULL,batch_number VARCHAR(100),in_qty DECIMAL(18, 4) NOT NULL,remaining_qty DECIMAL(18, 4) NOT NULL,unit_cost DECIMAL(18, 6) NOT NULL,in_time TIMESTAMP NOT NULL,CONSTRAINT fk_cl_productFOREIGN KEY (product_id) REFERENCES products(product_id),CONSTRAINT fk_cl_warehouseFOREIGN KEY (warehouse_id) REFERENCES warehouses(warehouse_id));出库扣减逻辑示意:
- 查询按
in_time升序的成本层:
SELECT * FROM cost_layers WHERE product_id = :product_id AND warehouse_id = :warehouse_id AND remaining_qty > 0 ORDER BY in_time ASC FOR UPDATE;
2. 循环从最早层开始扣减 `remaining_qty`,直到满足出库数量。3. 记录每个成本层的出库数量,用于计算出库成本总额。
由于 FIFO 成本法在 SQL 中实现逻辑较复杂,许多企业会选择通过成熟进销存系统来处理这部分逻辑。
在这方面,一些可定制的进销存解决方案会提供现成的成本算法配置和 SQL 报表模板,例如云端的**进销存系统模板**,可以直接在浏览器中管理库存、成本,并通过可配置的表单和报表实现 FIFO、加权平均等不同模式,避免大量底层 SQL 开发工作。
---
## 🚨 八、安全库存、预警与补货策略的 SQL 实战
高效库存控制不仅是记录与统计,更要利用 SQL 实现**预警与决策支持**。
### 1. 安全库存与最小/最大库存配置表
可以为每个商品在每个仓库配置安全库存和补货参数:
```sqlCREATE TABLE inventory_policies (warehouse_id BIGINT NOT NULL,product_id BIGINT NOT NULL,safety_stock DECIMAL(18, 4) NOT NULL DEFAULT 0,min_stock DECIMAL(18, 4),max_stock DECIMAL(18, 4),reorder_qty DECIMAL(18, 4), -- 建议补货数量lead_time_days INT, -- 采购提前期PRIMARY KEY (warehouse_id, product_id),CONSTRAINT fk_ip_warehouseFOREIGN KEY (warehouse_id) REFERENCES warehouses(warehouse_id),CONSTRAINT fk_ip_productFOREIGN KEY (product_id) REFERENCES products(product_id));2. 安全库存预警 SQL 示例
基于 inventory_balances 和 inventory_policies,查询不足安全库存的商品:
SELECTb.warehouse_id,w.warehouse_name,b.product_id,p.product_name,b.balance_qty,ip.safety_stock,(ip.safety_stock - b.balance_qty) AS shortage_qtyFROMinventory_balances bJOINinventory_policies ipON b.warehouse_id = ip.warehouse_idAND b.product_id = ip.product_idJOINwarehouses w ON b.warehouse_id = w.warehouse_idJOINproducts p ON b.product_id = p.product_idWHEREb.balance_qty < ip.safety_stockORDER BYshortage_qty DESC;此 SQL 可以生成安全库存预警报表,提醒采购或仓储部门及时补货。
3. 自动补货建议 SQL 示例
进一步结合未完成的采购订单,得出补货建议:
WITH current_stock AS (SELECTwarehouse_id,product_id,SUM(balance_qty) AS balance_qtyFROMinventory_balancesGROUP BYwarehouse_id, product_id),pending_po AS (SELECTpo.warehouse_id,pod.product_id,SUM(pod.quantity - pod.received_qty) AS on_order_qtyFROMpurchase_orders poJOINpurchase_order_details pod ON po.po_id = pod.po_idWHEREpo.status IN ('APPROVED', 'RECEIVED') -- 未完全收货GROUP BYpo.warehouse_id, pod.product_id)SELECTip.warehouse_id,w.warehouse_name,ip.product_id,p.product_name,COALESCE(cs.balance_qty, 0) AS balance_qty,COALESCE(pp.on_order_qty, 0) AS on_order_qty,ip.min_stock,ip.max_stock,(ip.max_stock - (COALESCE(cs.balance_qty, 0) + COALESCE(pp.on_order_qty, 0))) AS suggested_reorder_qtyFROMinventory_policies ipLEFT JOIN current_stock csON ip.warehouse_id = cs.warehouse_idAND ip.product_id = cs.product_idLEFT JOIN pending_po ppON ip.warehouse_id = pp.warehouse_idAND ip.product_id = pp.product_idJOIN warehouses w ON ip.warehouse_id = w.warehouse_idJOIN products p ON ip.product_id = p.product_idWHERE(COALESCE(cs.balance_qty, 0) + COALESCE(pp.on_order_qty, 0)) < ip.min_stockORDER BYsuggested_reorder_qty DESC;此 SQL 可以帮助制定采购计划,实现数据驱动的库存控制。
📈 九、常用库存控制报表的 SQL 实现示例
在进销存系统中,常用的库存控制报表主要包括:
- 库存台账(按时间查看入库、出库、结余)
- ABC 分类与周转率分析
- 滞销品分析
- 批次追踪报告
下面给出几个典型 SQL 示例。
1. 库存台账报表(按日汇总)
按日期、商品、仓库查看每日入库、出库、期末结余:
WITH daily_movements AS (SELECTDATE(transaction_time) AS tx_date,warehouse_id,product_id,SUM(CASE WHEN quantity_change > 0 THEN quantity_change ELSE 0 END) AS in_qty,SUM(CASE WHEN quantity_change < 0 THEN -quantity_change ELSE 0 END) AS out_qtyFROMinventory_transactionsWHEREtransaction_time BETWEEN :start_date AND :end_date + INTERVAL '1 day'GROUP BYDATE(transaction_time),warehouse_id,product_id),running_balance AS (SELECTdm.tx_date,dm.warehouse_id,dm.product_id,dm.in_qty,dm.out_qty,SUM(dm.in_qty - dm.out_qty) OVER (PARTITION BY dm.warehouse_id, dm.product_idORDER BY dm.tx_date) AS end_balanceFROMdaily_movements dm)SELECTrb.tx_date,rb.warehouse_id,w.warehouse_name,rb.product_id,p.product_name,rb.in_qty,rb.out_qty,rb.end_balanceFROMrunning_balance rbJOINwarehouses w ON rb.warehouse_id = w.warehouse_idJOINproducts p ON rb.product_id = p.product_idORDER BYrb.tx_date,rb.warehouse_id,rb.product_id;2. ABC 分类分析(根据年耗用金额)
思路: 按“年耗用金额 = 年出库数量 × 单位成本”从高到低排序,分 A/B/C 三类,帮助优化库存控制策略。
WITH yearly_usage AS (SELECTproduct_id,SUM(CASE WHEN quantity_change < 0 THEN -quantity_change ELSE 0 END) AS yearly_out_qtyFROMinventory_transactionsWHEREtransaction_time BETWEEN :start_year AND :end_year + INTERVAL '1 day'GROUP BYproduct_id),usage_with_cost AS (SELECTyu.product_id,yu.yearly_out_qty,pc.avg_cost,yu.yearly_out_qty * pc.avg_cost AS yearly_amountFROMyearly_usage yuJOIN product_costs pc ON yu.product_id = pc.product_id),sorted_usage AS (SELECTuwc.*,SUM(yearly_amount) OVER () AS total_amount,SUM(yearly_amount) OVER (ORDER BY yearly_amount DESC) AS running_amountFROMusage_with_cost uwc),abc_classified AS (SELECTproduct_id,yearly_out_qty,avg_cost,yearly_amount,running_amount / total_amount AS cumulative_ratio,CASEWHEN running_amount / total_amount <= 0.8 THEN 'A'WHEN running_amount / total_amount <= 0.95 THEN 'B'ELSE 'C'END AS abc_classFROMsorted_usage)SELECTac.product_id,p.product_name,ac.yearly_out_qty,ac.avg_cost,ac.yearly_amount,ac.cumulative_ratio,ac.abc_classFROMabc_classified acJOINproducts p ON ac.product_id = p.product_idORDER BYac.yearly_amount DESC;通过 ABC 分析,可对不同类别商品制定不同的库存控制策略:
- A 类:严格控制库存水平,频繁补货。
- B 类:适中频次补货。
- C 类:减少订单和管理成本,可采用较高安全库存避免缺货。
3. 滞销品分析 SQL 示例
找出一定时间内无出库记录或出库非常少的商品:
WITH last_sale AS (SELECTproduct_id,MAX(transaction_time) AS last_out_timeFROMinventory_transactionsWHEREquantity_change < 0GROUP BYproduct_id)SELECTp.product_id,p.product_name,b.balance_qty,ls.last_out_timeFROMproducts pJOINinventory_balances b ON p.product_id = b.product_idLEFT JOINlast_sale ls ON p.product_id = ls.product_idWHEREb.balance_qty > 0AND (ls.last_out_time IS NULL OR ls.last_out_time < :threshold_date)ORDER BYls.last_out_time NULLS FIRST, b.balance_qty DESC;此报表可以识别库存积压,辅助制定促销计划或清仓策略。
🧷 十、SQL 细节优化与常见坑避雷
1. 数据类型与精度控制
在进销存系统中,数据类型设计要谨慎:
- 数量字段使用
DECIMAL(18,4)或根据行业需求调整精度。 - 金额字段使用
DECIMAL(18,2)或更高精度。 - 禁用
FLOAT/DOUBLE处理重要金额,避免精度误差。
2. 索引与查询优化建议
常见优化点:
- 为高频查询字段建立索引:
product_id、warehouse_id、transaction_time、sku等。 - 避免在 WHERE 子句中对索引字段使用
函数包裹(如DATE(transaction_time)),可通过区间查询代替。 - 将大范围历史流水归档到历史表,减少主流水表的数据量。
示例:按日期范围查询流水避免函数:
WHEREtransaction_time >= :start_dateAND transaction_time < :end_date + INTERVAL '1 day'而不是:
WHEREDATE(transaction_time) BETWEEN :start_date AND :end_date3. 并发与锁控制常见问题
- 避免对大表做
SELECT ... FOR UPDATE范围过大,增加死锁风险。 - 高并发出库场景下,建议在业务层按商品+仓库维度拆分事务,甚至使用队列化方式处理敏感商品库存变动。
- 在复杂 SQL 进销存系统中,可通过悲观锁 + 重试机制解决偶发死锁。
🧭 十一、用模板与低代码平台提升 SQL 进销存效率
虽然可以通过纯 SQL 搭建完整的进销存系统,但对于很多企业来说:
- 自行从零开始设计所有表结构、存储过程、触发器,周期长、维护成本高;
- 报表需求频繁变更,每次都要改 SQL,开发负担重。
因此,在实际项目中,常常会选择已有的进销存系统模板或低代码平台,用可视化方式配置业务流程,再在底层用 SQL 实现定制报表与复杂逻辑。
例如,某些云端进销存模板提供:
- 商品管理、仓库管理、入库出库单据、库存台账等标准模块;
- 可视化字段配置与流程审批;
- 通过 SQL 或公式配置统计报表(如库存预警、销售分析);
- 支持对接其他业务系统、BI 报表工具。
在此类平台上,像简道云进销存模板这类解决方案(链接: https://s.fanruan.com/8bn69;),可以直接使用预配置的进销存模型,然后根据自身业务调整商品字段、库存维度、审批流程和报表视图,让企业在控制成本的同时,仍能利用 SQL 的灵活性做个性化统计与分析。
🔮 十二、总结与未来库存控制趋势展望
1. 文章核心要点回顾
围绕“SQL 进销存管理技巧”和“如何高效实现库存控制”,核心实践可以归纳为:
- 数据模型清晰化
- 商品、仓库、单据、流水、库存结余等核心表结构要合理,规范化与反规范化适度结合。
- 统一库存流水表
- 所有入库、出库、调拨、盘点都记录在
inventory_transactions中,便于追溯和统计。
- 库存结余与性能优化
- 通过
inventory_balances表和触发器/批处理,实现实时库存查询与高性能。
- 成本与策略控制
- 移动加权平均和 FIFO 成本法可以通过 SQL 实现,支撑准确的库存成本与利润分析。
- 决策支持报表
- 利用 SQL 实现安全库存预警、自动补货建议、库存台账、ABC 分类、滞销分析等报表。
- 事务与并发控制
- 合理使用事务、锁、索引,确保高并发场景下库存数据一致、不超卖。
在部署层面,可以选择自己从头建设 SQL 进销存系统,也可以基于现成的在线进销存模板做定制扩展,减少开发和维护压力。
2. 库存控制与 SQL 的未来趋势
未来几年,基于 SQL 的进销存和库存管理,会呈现出以下趋势:
- 与云平台深度融合:越来越多的企业采用云数据库 + SaaS 进销存系统,通过 API 或直接 SQL 接口实现数据集成。
- 智能化补货与预测:在传统 SQL 分析基础上,引入机器学习算法,结合历史销售、季节因素、促销活动等做更精准的需求预测与补货建议。
- 实时可视化与多维分析:通过在线 BI 工具,将库存数据实时可视化,支持按品类、区域、客户、供应商多维度分析。
- 多系统协同:进销存与财务、CRM、生产管理系统深度整合,库存数据成为企业运营的中枢。
在这个过程中,SQL 依然是库存数据建模与分析的关键语言,掌握本文介绍的建模思路与 SQL 实战技巧,可以帮助你搭建稳健的进销存管理系统,并在未来升级到更智能的库存控制体系。
最后,分享一个我们公司在用的进销存系统模板,需要的可以自取,可直接使用,也可以自定义编辑修改: https://s.fanruan.com/8bn69
精品问答:
什么是SQL进销存管理系统,如何利用它实现高效库存控制?
我最近在学习企业库存管理,听说SQL进销存管理系统可以帮助提升库存控制效率,但具体它是什么,有哪些核心功能呢?如何利用SQL技术来优化库存管理?
SQL进销存管理系统是基于结构化查询语言(SQL)的库存、采购与销售数据管理平台。它通过实时数据查询、库存预警和自动补货等功能,实现高效的库存控制。具体包括:
- 实时库存查询:通过SQL语句快速检索库存状态,确保数据准确。
- 库存预警机制:利用触发器和存储过程,在库存低于安全库存时自动提醒。
- 自动补货策略:结合历史销售数据,使用SQL分析预测补货需求。
案例:某零售企业通过SQL统计月度销售量,设置库存下限触发自动补货,库存周转率提升了20%,库存积压减少15%。
如何设计SQL数据库表结构以支持高效的进销存管理?
我想搭建一个进销存管理系统,不太清楚SQL数据库表结构该如何设计才能保证数据查询和统计的效率,有什么设计技巧和注意点吗?
设计高效的SQL数据库表结构关键在于规范化与合理索引,主要步骤包括:
| 表名 | 主要字段 | 作用说明 |
|---|---|---|
| 商品表 | 商品ID(主键)、名称、规格等 | 存储商品基本信息 |
| 库存表 | 商品ID(外键)、库存数量 | 记录当前库存状态 |
| 进货表 | 进货ID、商品ID、数量、时间 | 记录采购入库信息 |
| 销售表 | 销售ID、商品ID、数量、时间 | 记录商品销售情况 |
设计技巧:
- 使用主外键关联保证数据完整性
- 为高频查询字段建立索引加快查询速度
- 适当进行表分区处理大数据量场景
案例:通过合理设计表结构,一家电商平台查询单品库存响应时间从2秒缩短至0.2秒。
有哪些SQL查询技巧能提升库存数据分析的效率?
我在用SQL做库存数据分析时,经常遇到查询效率不高的问题,有没有什么实用的SQL查询技巧或者函数,能帮助我快速得到准确的库存报表?
提升库存数据分析效率的SQL查询技巧包括:
- 使用JOIN优化表连接,避免子查询嵌套过深。
- 利用窗口函数(如ROW_NUMBER、RANK)进行排名和累计统计,简化复杂计算。
- 采用索引扫描而不是全表扫描,确保查询条件使用索引。
- 使用聚合函数(SUM、COUNT)实现快速汇总库存数据。
- 利用视图封装复杂查询,提高复用性。
案例:利用窗口函数统计近30天销售排名,某企业报表生成速度提升50%。
如何通过SQL自动化库存预警和补货流程?
库存管理中,手动监控库存很费时,想知道用SQL怎么实现库存预警和自动补货,能不能举个具体的自动化实现方案?
通过SQL实现库存预警和自动补货,主要依靠存储过程、触发器和定时任务,具体实现步骤:
- 设置库存下限阈值字段。
- 创建触发器,当库存变动时,自动检测是否低于阈值。
- 触发器触发后,执行存储过程发送预警通知或自动生成补货订单。
- 配合数据库定时任务(如SQL Agent),定期检查库存状态。
示例:某制造企业设置库存阈值为100件,库存变动触发器实时监控,低于阈值自动插入补货申请单,补货响应时间缩短40%。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/493668/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号