
我这些年在现场看设备管理,有一个很直观的感受: 很多企业的巡检,不是没做,而是“做了也没什么用”。
设备该坏还是坏,隐患该漏还是漏,问题该重复还是重复。
说白了,大多数企业的巡检,停留在一个很基础的层面:“有没有做”,而不是“有没有用”。
很多管理者第一反应是:执行不到位,是人不认真。
但如果你在一线待得久一点就会发现,问题往往不在表面上的”巡“和”检“。
- 有的企业巡得很勤,还是出问题
- 有的企业标准写得很细,现场依然看不出来异常
也就是说, 巡检做不出效果,很多时候不是“巡”没做到位,也不是“检”不专业, 而是忽略了更关键的部分:
- 巡检之前,有没有按结果导向去设计
- 巡检之后,这些问题有没有被真正管起来、解决掉
今天我们就把设备巡检这件事拆开,讲点接地气的。
如果你正好也在做这块,我这里已经沉淀成一套比较完整的设备管理与巡检系统了,可以直接拿去参考或改一版用: https://www.jiandaoyun.com
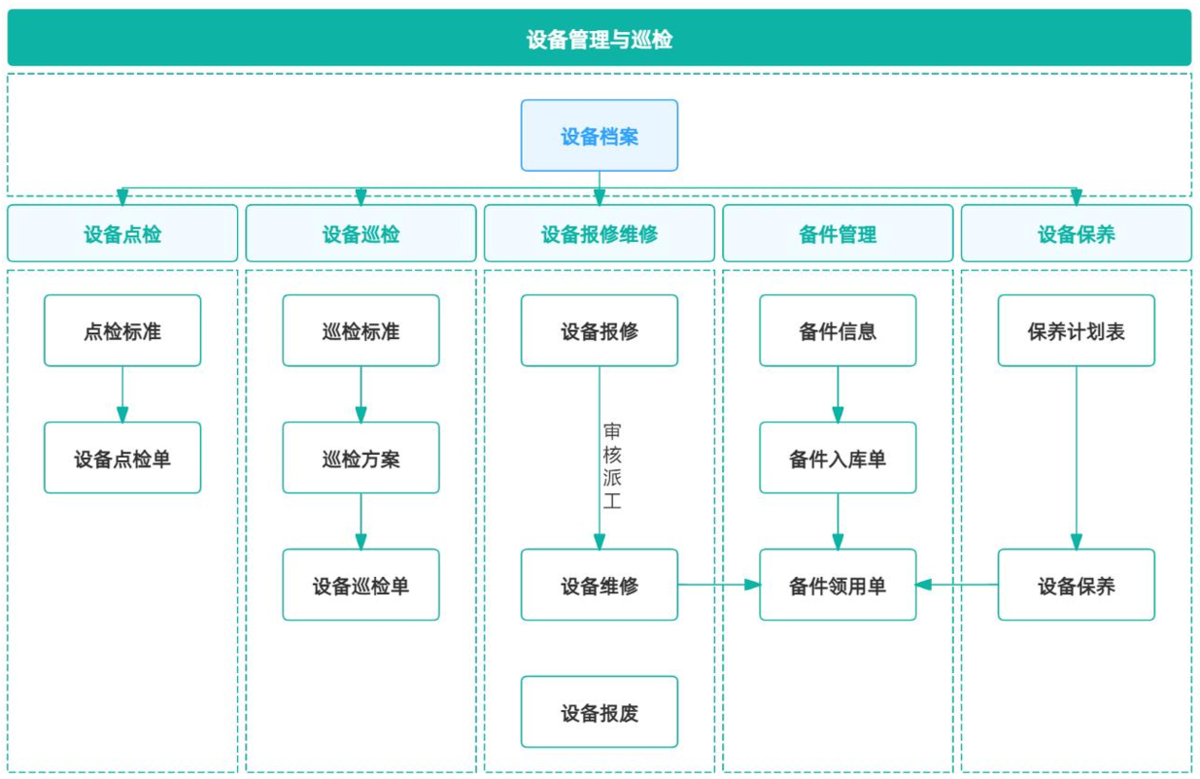
一、巡是覆盖、检是判断,闭环才是价值
我们平时说“巡检”,其实默认把它当成一个动作:
有人去现场,看一圈,记录一下,这就叫巡检。
但如果你从管理角度看,这里面其实至少有三层含义:
- 巡(走到哪里)
- 检(看什么、怎么判断)
- 处理(发现问题之后怎么办)
问题就出在,大多数企业只做了前两步,甚至只做了第一步。
1. 巡,解决的是有没有覆盖
巡,本质上是路径设计问题:
- 哪些设备要巡
- 按什么路线巡
- 多久巡一次
这些东西,只要你稍微花点时间,都能定出来。
所以绝大多数企业,其实都巡到了。
但问题在于巡到了,并不代表你真的在管理设备。
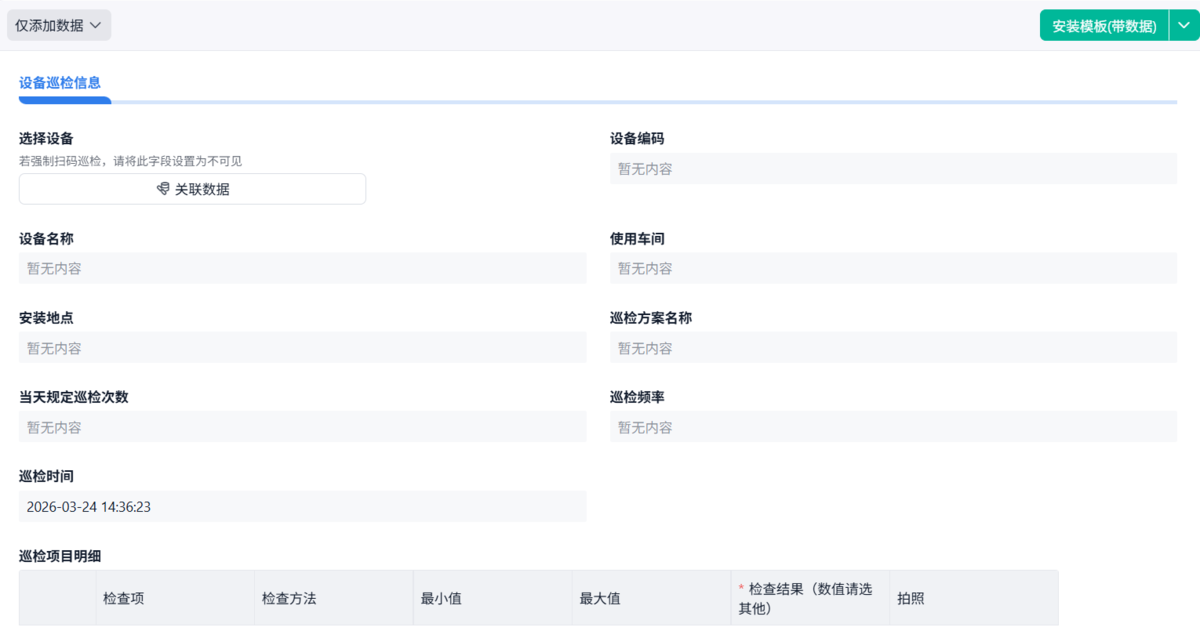
2. 检,解决的是有没有标准
检代表的是判断。难点不在有没有标准,而在标准有没有用。
很多企业也确实写了巡检标准,但往往存在几个问题:
- 标准写得很模糊(比如:是否正常)
- 很多是经验型描述(声音是否异常)
- 不同人理解不一样
结果就是同一台设备,不同的人巡检,结论不一样。老员工能看出点问题,新人基本全选“正常”。
这在小团队还能撑一撑,一旦人多、设备多,就完全不可控。
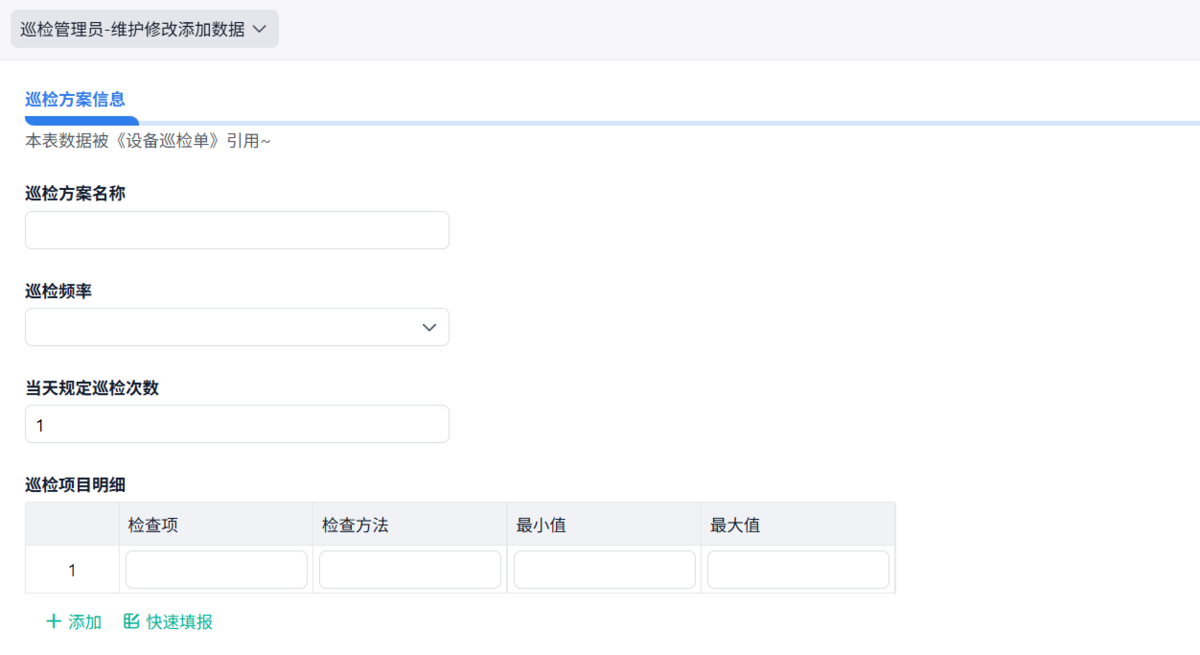
3. 真正有价值的是“闭环”
很多人一直在纠结:是巡得不够勤?还是检得不够细?
但你往下再追一步就会发现,真正的关键在于问题有没有被真正解决。
现场最典型的情况是什么?
第一天巡,发现小问题写在表上。第二天再巡,还在。过几天,直接变设备故障。
这时候你再回头看那几张巡检表,会觉得特别荒诞:问题早就出现过,但没有人真正把它当成一件必须解决的事。
所以你会发现:
- 巡,是覆盖过程
- 检,是判断手段
- 真正具有价值的,是有没有把问题闭环处理
二、巡检没效果?这四步才是闭环的关键
如果你现在的巡检效果不好,大概率不是一个点的问题,而是整套逻辑有缺口。
现场最常见的四个“卡点”,基本都卡在下面这4个地方:
- 巡检项没有突出重点风险
- 巡检标准写了,但没人真的按它判断
- 发现问题之后,没有机制去推进处理
- 数据有了,但没有被用来优化管理
你把这四件事拆开看,好像每一件都在做。表也有,标准也写了,人也在巡,记录也在留。
但问题在于,巡检是巡检,处理是处理,数据是数据,彼此之间没有真正连起来。最后就是事情做了很多,但没有形成结果。
我后来慢慢意识到一件事:
设备巡检这件事,不能按“动作”去设计,而要按“结果”去倒推。
你想要的结果其实很简单—— 问题被提前发现,并且被及时解决,而且不会反复出现。
如果按这个结果往回推,巡检就一定不是“巡 + 检”两步,而是一整套闭环。

我一般会把它拆成四步,现场也都是按这个逻辑去重新搭的:
1. 巡检项设计:盯住风险点
许多企业的巡检表,看起来很全,其实没重点。
问题不在少,而在于太过分散、太过全面。
真正有效的做法,是反过来想,这台设备,最容易出什么问题?
- 哪些部位最容易磨损
- 哪些点一旦异常,会直接影响停机
- 哪些问题是历史上反复出现的
然后围绕这些风险点去设计巡检项。
我在现场一般会建议做一个简单分层:
- 关键巡检项(直接关联故障)
- 一般巡检项(日常确认)
这样一来,一线人员在执行的时候,就知道哪些地方必须重点看,而不是一圈走完就结束。
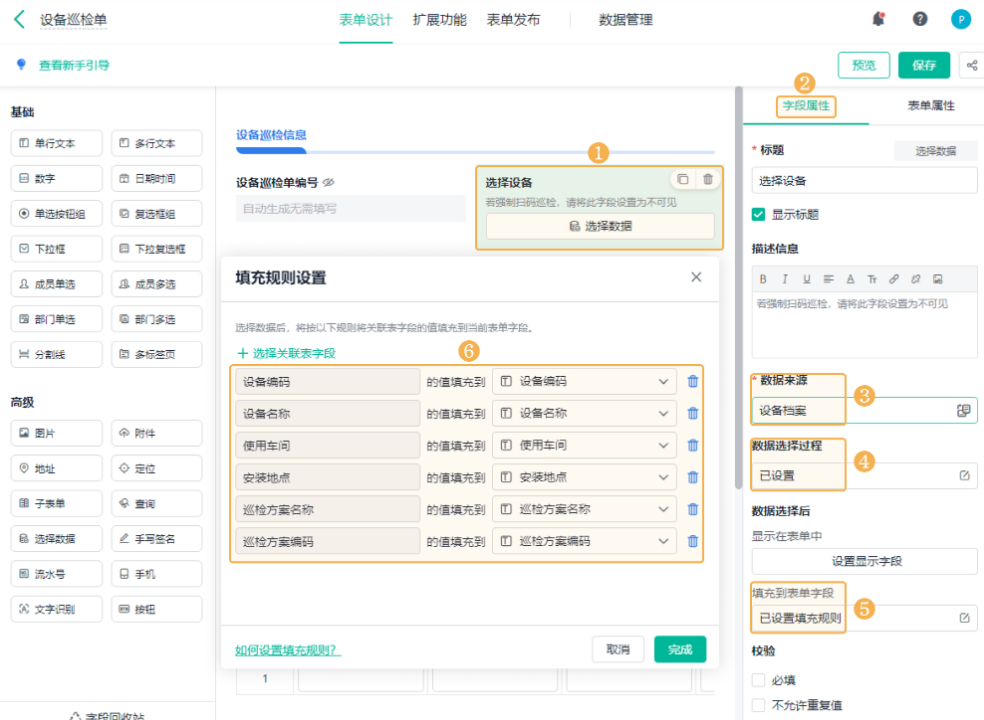
2. 巡检标准定义:不让经验成为门槛
巡检这件事,一旦依赖经验,就很难规模化。
所以标准一定要做到一个程度:换一个人来做结果也差不多。
怎么做到?我这里有几个很实用的做法:
- 能量化的尽量量化(温度、时间、频次)
- 给区间,而不是简单“正常/异常”
- 多用图片或示意,减少理解偏差
很多企业的问题是,标准写在表里,但没有真正变成现场的判断依据。
后来我们在帮一些团队优化的时候,会直接把这些标准嵌到系统里,比如巡检填报的时候,不是让你写“是否正常”,而是直接选区间,甚至可以关联历史数据做对比。
这样做的好处很直接:不是靠人记标准,而是系统帮你约束判断。
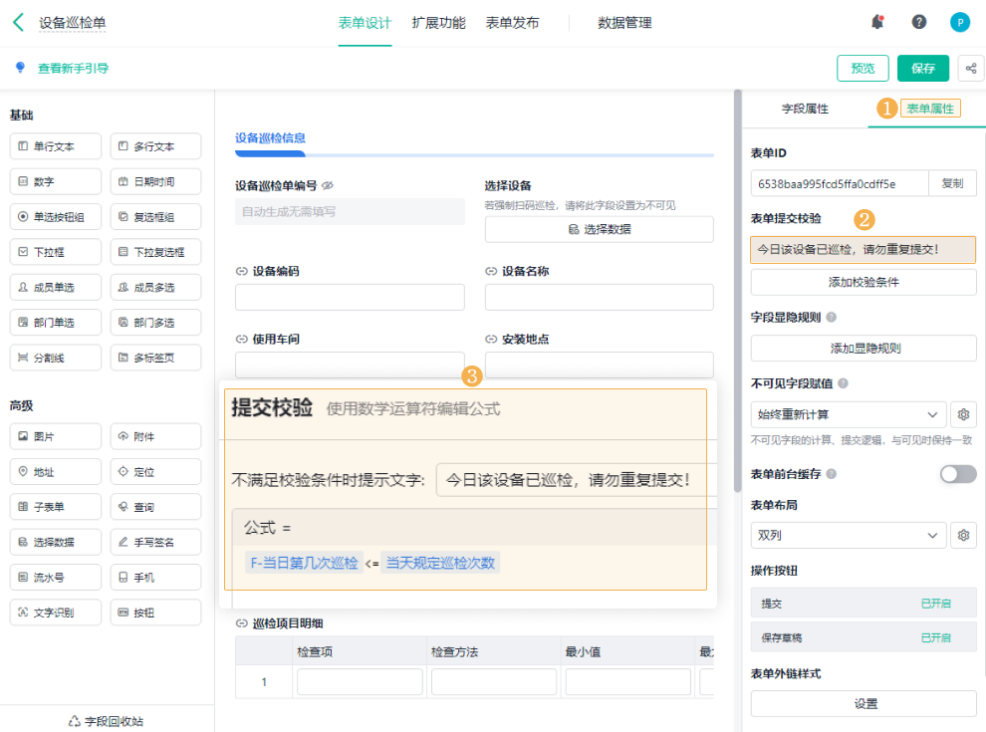
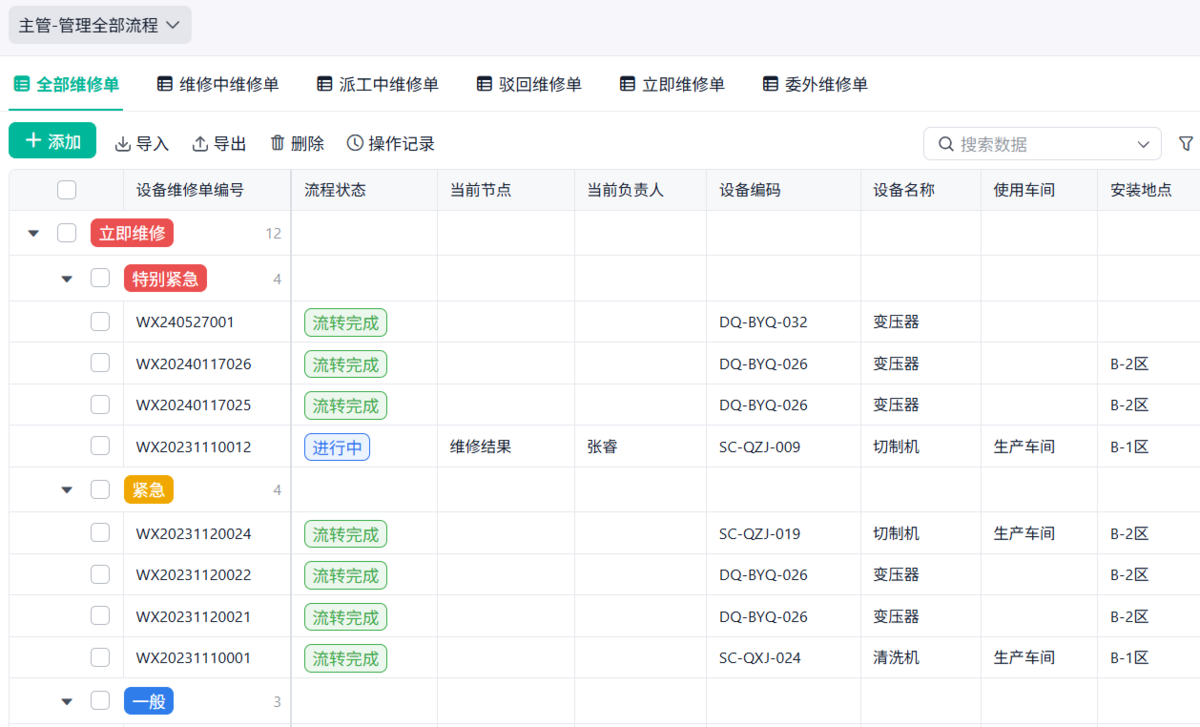
3. 异常处理机制:让问题必须被解决
这一部分,是决定巡检有没有价值的关键。
如果巡检发现问题,但没有处理机制,那前面做再多都是白搭。
一个有效的异常处理机制,我一般会要求这一步至少做到四件事:
- 异常必须结构化记录(不是随便写一句)
- 自动带出责任人
- 明确处理时限
- 有过程记录和结果确认
这一整套下来,才叫闭环。
很多企业一开始是靠人工去推动,比如发微信、打电话,但很容易漏。
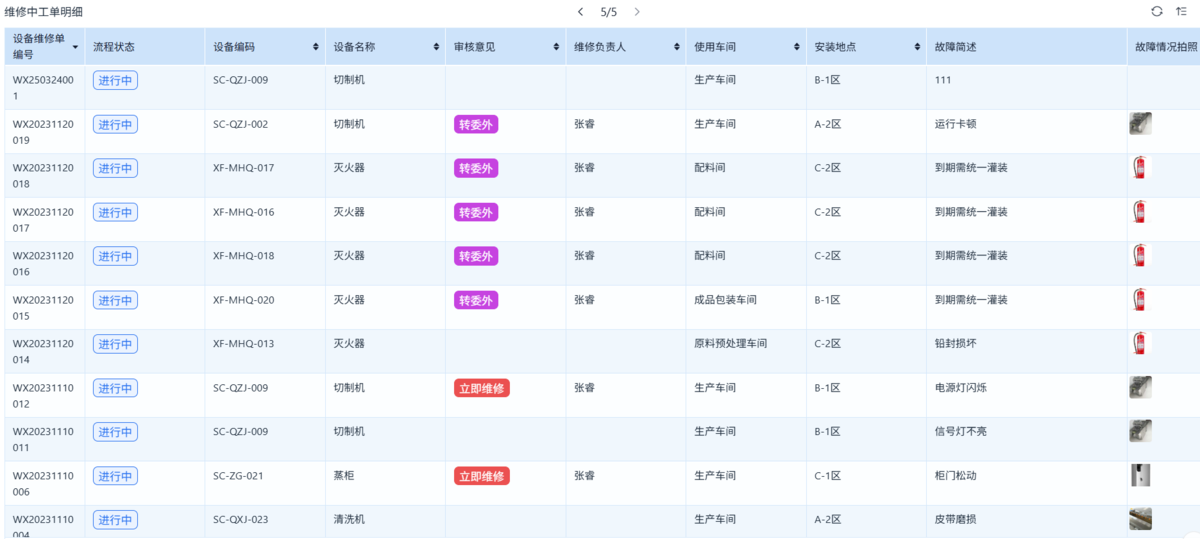
后来比较常见的做法,是直接把巡检和维修打通。
比如用一套简单的设备管理应用(比如简道云),巡检的时候一旦勾选“异常”,系统会自动生成一条维修任务:
- 责任人是谁
- 多长时间内处理
- 处理过程怎么记录
全部自动带出来。
这样一来,巡检就不再是“发现问题”,而是直接进入“解决问题”。
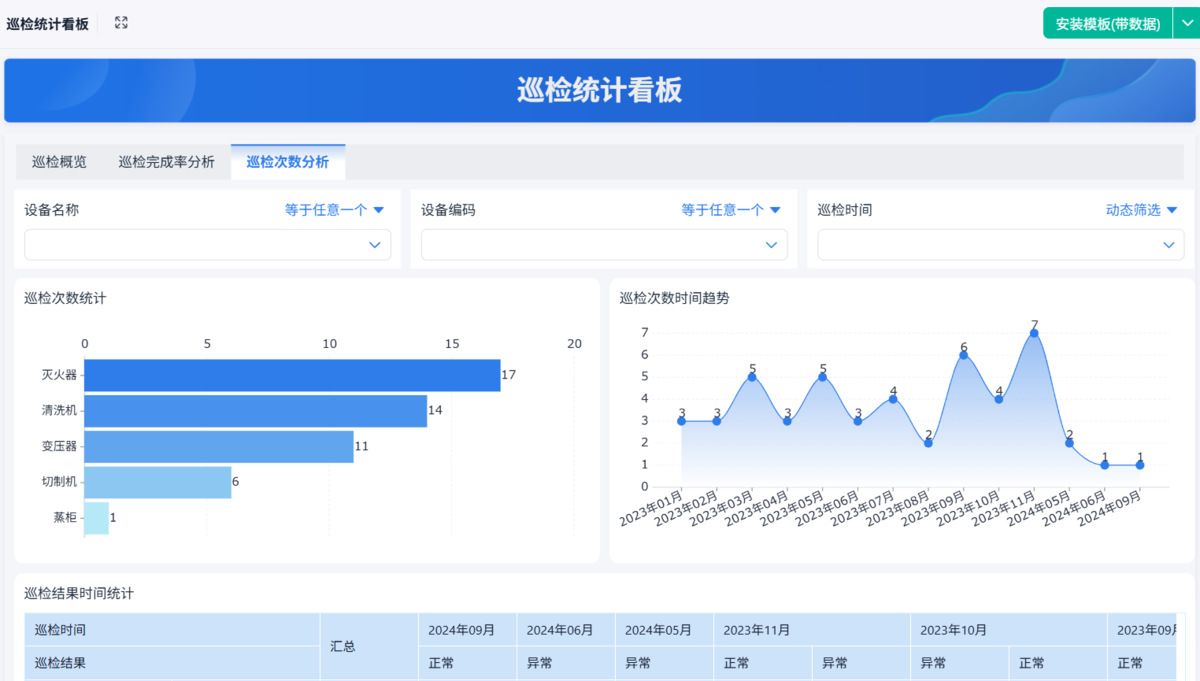
4. 数据分析与优化:让巡检越做越聪明
如果前面三步打通了,其实你已经有一套能跑的巡检体系了。
但真正拉开差距的,是有没有用数据去反过来优化。
不需要一开始就做很复杂的分析,先盯几个最实用的:
- 哪些设备问题最多
- 哪些问题在重复出现
- 巡检有没有提前发现问题
- 哪些巡检项长期没有价值
这些数据,很多企业其实都有,只是没有被用起来。
当你开始用这些数据去调整巡检项、优化维护策略的时候,你会发现:
巡检这件事,开始有“积累”了,而不是每天从零开始。
如果是放在系统里,这一步会更容易一些,比如自动统计高频故障、异常分布、处理时效这些,不需要额外去整理,现场就能直接看到。
总结一句话
很多人一直在纠结:
巡检到底是“巡”更重要,还是“检”更重要?
如果你从业务结果去看,这个问题其实不成立。
真正决定效果的,是有没有巡到关键点、有没有做出一致判断、有没有把问题真正解决掉。
所以可以用三句话总结:
- 巡,是覆盖
- 检,是判断
- 闭环,才是价值
巡检不再是一个“每天重复的动作”,而是变成一个持续优化的过程。


