
TPM,其实很多人一开始听到都会懵:这到底是个啥高级管理术语?很“制造业”、很“复杂”。但说实话,它一点也不玄乎,你可以把它理解成一句特别接地气的话:
“让设备不掉链子,让人也别只当‘修理工’,而是一起把生产搞顺。”
TPM的全称叫:Total Productive Maintenance,翻译过来就是全面生产维护。
这篇文章不讲概念,直接讲清一件事:TPM到底在解决什么问题,为什么它的核心不在维修,而在减少设备故障本身。
以下提及的系统,点击即可体验: https://www.jiandaoyun.com
一、先别管概念,TPM本质就一件事
如果非要用一句话讲清楚TPM,可以这样理解:
把“设备这件事”,从少数人修,变成所有人一起管。
很多企业的问题就在这里:
设备是大家都在用的,但“管设备”这件事,默认只属于维修部门。
结果就会出现一种很典型的状态:
- 操作工只负责干活,不管设备
- 设备出了问题,第一反应就是“找维修”
- 维修忙不过来,就变成到处救火
- 问题解决了,但原因没解决,下次还会再来
你仔细想,这其实是一个循环:
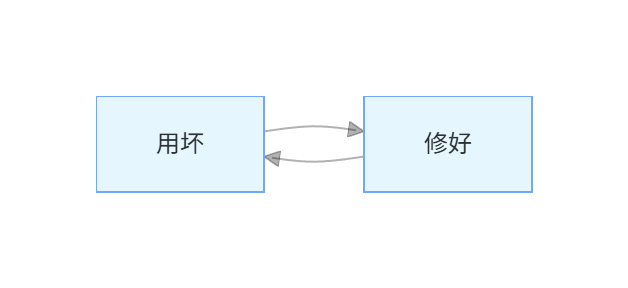
TPM做的,就是把这个循环打断。
二、为什么TPM会成为制造企业的“必选项”
很多企业在设备管理上都会遇到一个情况:
维修越来越忙,但设备问题并没有减少。
于是大家很容易形成一种默认认知:设备故障是随机的,坏了就只能修。
但实际情况并不是这样。
大多数设备故障,并不是突然发生的,而是一个逐步变坏的过程,比如:
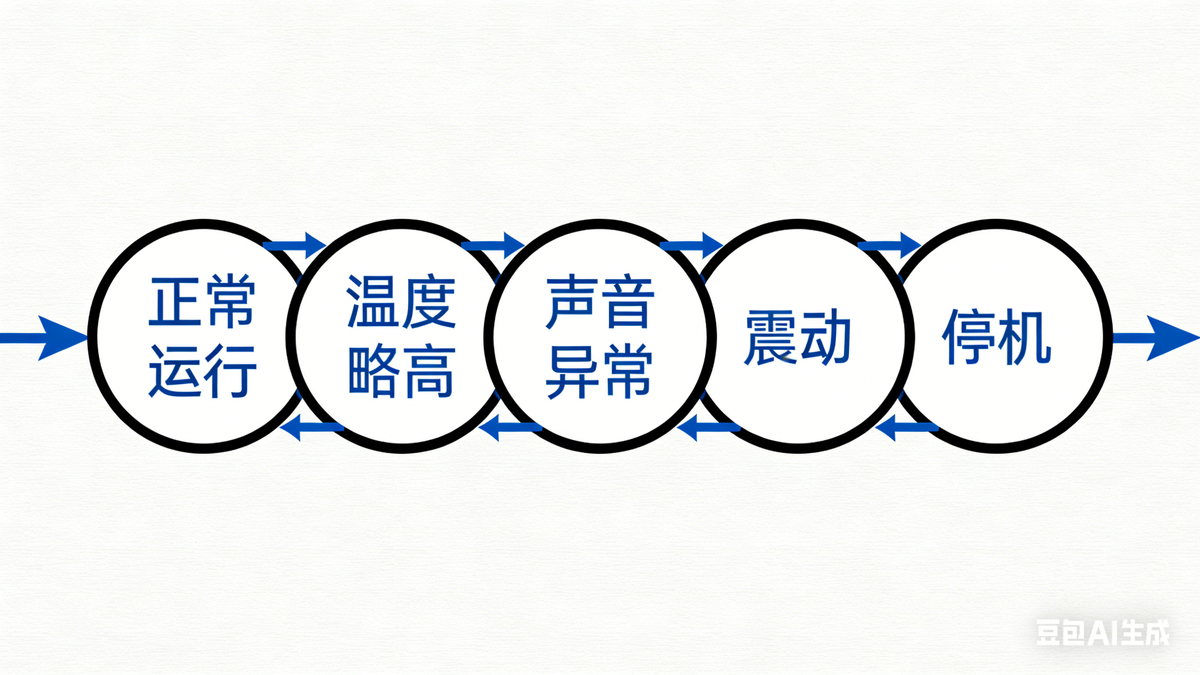
也就是说:设备不是突然坏掉的,而是慢慢“拖坏”的。
问题在于,这个过程在很多工厂里是被忽略的:
- 没人专门去检查
- 没有明确的判断标准
- 发现异常也没有记录和跟踪
结果就是,小问题不断积累,最后只能以“停机”的形式暴露出来。
所以你会看到:
- 同类故障反复发生
- 维修工作越来越多
- 设备稳定性却没有提升
本质原因很简单:企业一直在处理“结果问题”,却没有管住“过程问题”。
也正因为这一点,单纯依靠“修得更快”是解决不了问题的,这也是TPM要切入的地方。
三、TPM到底在改变什么?从“维修设备”到“管理设备”
你可以把TPM理解成一种“提前发现问题”的机制。
在传统模式下,设备管理是这样的:
出了问题 → 才有人管
在TPM模式下,是这样:
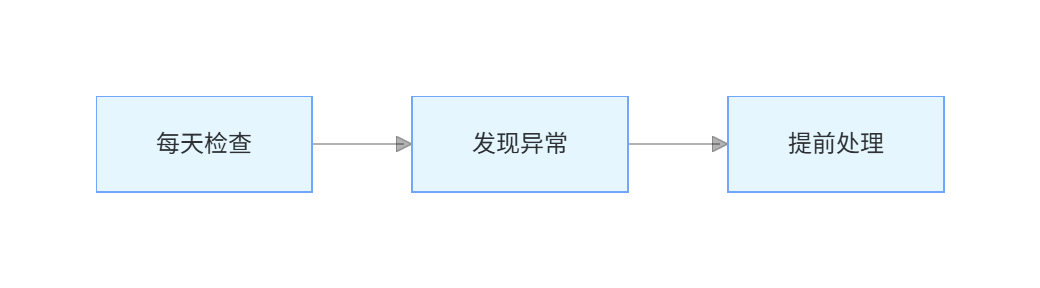
这中间最关键的动作,其实很简单:
点检 + 清扫 + 基础保养
听起来很基础,但很多企业恰恰是这些没做好。
一个操作工每天开机,但从来不擦设备、不检查状态,那他其实是“盲开”。
设备有没有异常,他是不知道的。
TPM会要求:
- 哪些位置每天要看
- 用什么方式看
- 什么情况算异常
把这些都标准化下来。
这样做的好处是:很多本来会发展成大故障的问题,在早期就被处理掉了。
四、TPM具体在做哪些事?
如果用一句话概括TPM的动作,可以理解为:让设备始终处在“可控状态”。
具体会落在几个方面。
1. 自主保全:操作工先把设备“管起来”
这是TPM中最关键的一环。
核心逻辑是:设备的第一责任人是使用者。
操作人员需要承担:
- 日常清扫
- 点检关键部位
- 做基础保养
现在不少企业的做法是,用比较简单的系统:
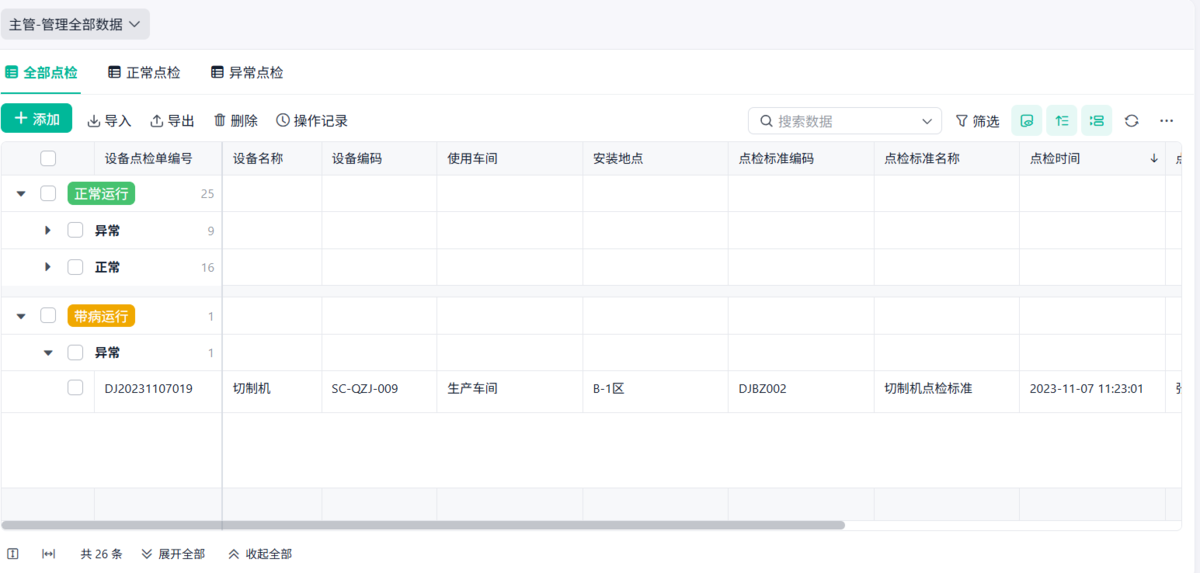
让问题尽早被发现,而不是等它爆出来。
2. 专业保全:维修从“救火”变“预防”
维修的重点不再是修得多快,而是:
- 哪些问题反复出现
- 根本原因是什么
- 怎么避免再次发生
目标是:减少问题,而不是应对问题。
3. 个别改善:盯住高频问题狠狠干
企业中总有一部分问题,占据了大部分损失(典型的80/20分布)。
TPM通过专项改善:
- 某个部件老坏
- 某台设备总卡
- 某个工位效率低
通过设备管理系统,可以直观的看到:
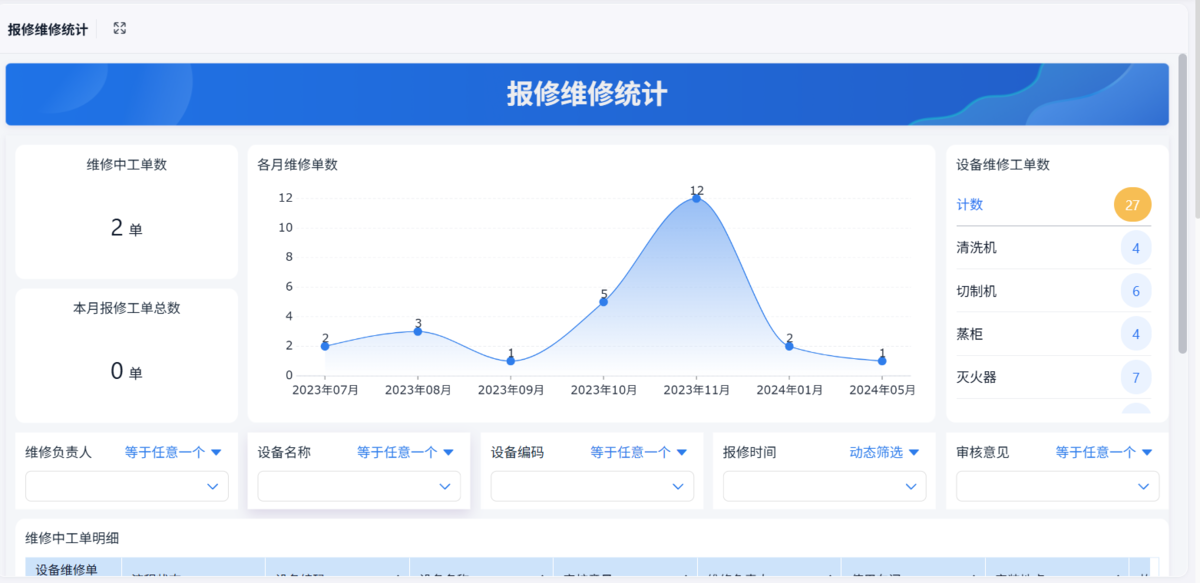
本质是:用项目化方式解决系统性问题
4. 初期管理:从设备导入阶段就控制风险
很多设备问题在采购阶段就已经埋下隐患,例如:
- 维护空间不足
- 易损件设计不合理
- 操作复杂度高
通过轻量化设备管理系统,就可以实现:
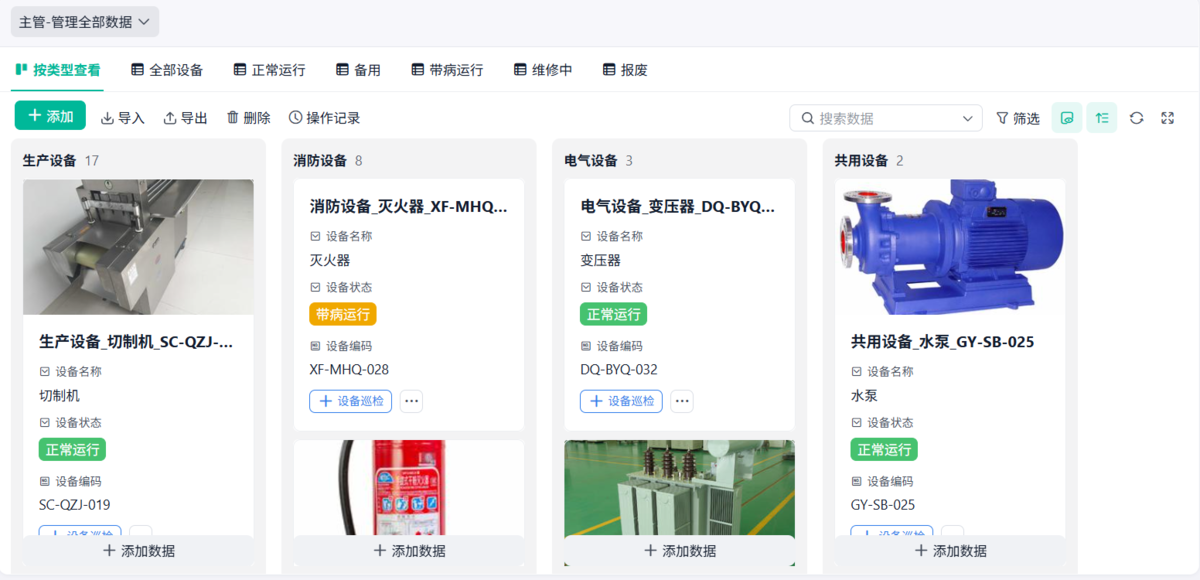
TPM要求:设备选型、安装、调试阶段就纳入管理体系。
5. 品质保全:把设备状态与产品质量直接关联
在很多生产场景中,质量波动并非工艺问题,而是设备状态波动导致。
例如:
- 温度偏差
- 压力不稳定
- 精度漂移
TPM通过控制设备关键参数,实现:
质量问题前置到设备管理层面解决。
6. 教育训练:能力体系的标准化建设
TPM强调:任何管理体系,如果无法复制,就无法规模化。
因此需要建立:
- 操作标准培训
- 点检技能培训
- 故障识别能力培训
7. 安全与环境:把风险控制嵌入日常管理
TPM将安全管理与设备管理融合,而不是单独存在。
现在很多企业已经不再写一堆制度,而是直接通过数字化设备管理系统:
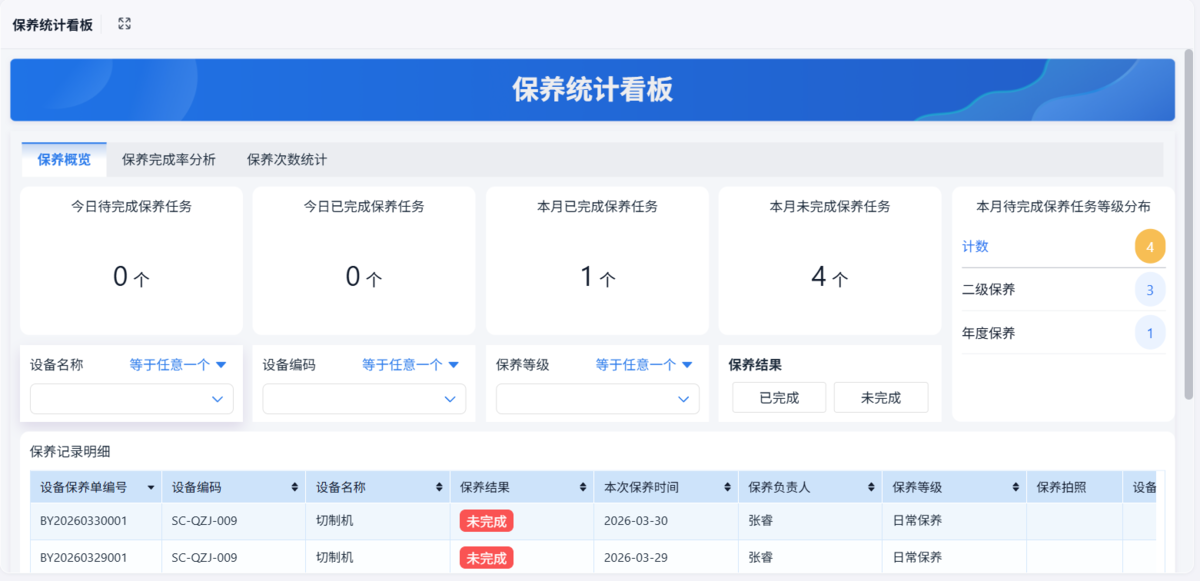
目标是:在日常操作与点检中,持续消除隐患。
8. 事务TPM:延伸到非生产环节
TPM不仅适用于生产现场,也适用于:
- 采购流程
- 计划排产
- 库存管理
本质是减少“管理性浪费”,提升整体运营效率。
五、TPM最关键的一个指标:OEE
TPM里有一个很核心的指标,叫OEE(设备综合效率)。
你可以把它理解成一句特别直白的话:
这台设备,到底有没有把它该干的活干出来。
它其实就是从三个角度看问题:
第一,设备有没有在干活(有没有停机)
第二,干活的时候有没有全速在干(有没有慢下来)
第三,干出来的东西有没有用(有没有报废)
这三个加起来,就能算出一个整体效率。
很多企业的问题在于:只盯其中一个点,比如只关注有没有停机。
但实际上:
- 设备不坏,但速度慢,也是在损失
- 设备产出多,但不良率高,也是在浪费
OEE的价值就在于:把这些“隐性损失”全部显性化。
六、TPM到底怎么落地?给你一套实操思路
很多企业TPM做不起来,不是方法问题,而是执行问题。
常见几个坑:
1. 一上来就搞复杂:各种表单、体系一起上,一线根本消化不了。
2. 只做动作,不讲逻辑:让员工填表、点检,但不说为什么,很容易流于形式。
3. 没有数据支撑:没有停机数据、没有故障分类,就很难做改善。
4. 靠人撑,而不是靠机制:一开始靠推动,后面没人盯就松掉。
那TPM到底怎么落地,我们不讲复杂方法,说一套更现实的路径。
第一步:不要全厂铺开,先选一个“能打的试点”
先选一个试点区域:
- 问题比较多(有改善空间)
- 但复杂度适中(能做出效果)
- 负责人愿意配合
核心目的只有一个:
先把方法跑通,而不是一开始就“做全面”。
第二步:先别急着改善,先让设备“看得见问题”
先做三件基础动作:
- 清扫设备(把隐藏问题暴露出来)
- 标出关键点(润滑点、易损点、异常点)
- 建一个简单点检表(控制在5–10个检查项)
通过设备管理系统,或者一些带报表能力的数字化工具,可以直接看到:
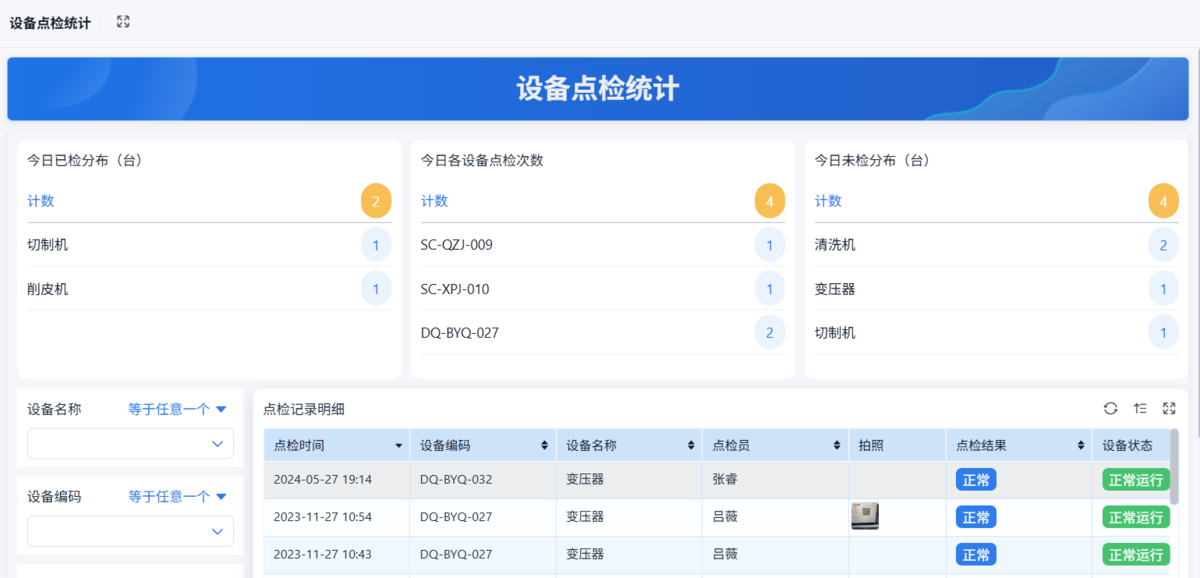
重点不是完善,而是:一线能执行,设备状态能被看见。
第三步:开始记录数据
TPM离不开数据,但一开始不用复杂。
只抓三件事:
- 停机多久(时间)
- 为什么停(原因)
- 出现几次(频率)
每周至少做一次简单复盘:
现在不少企业的做法是,用那种可以自己生成数据表格的系统:
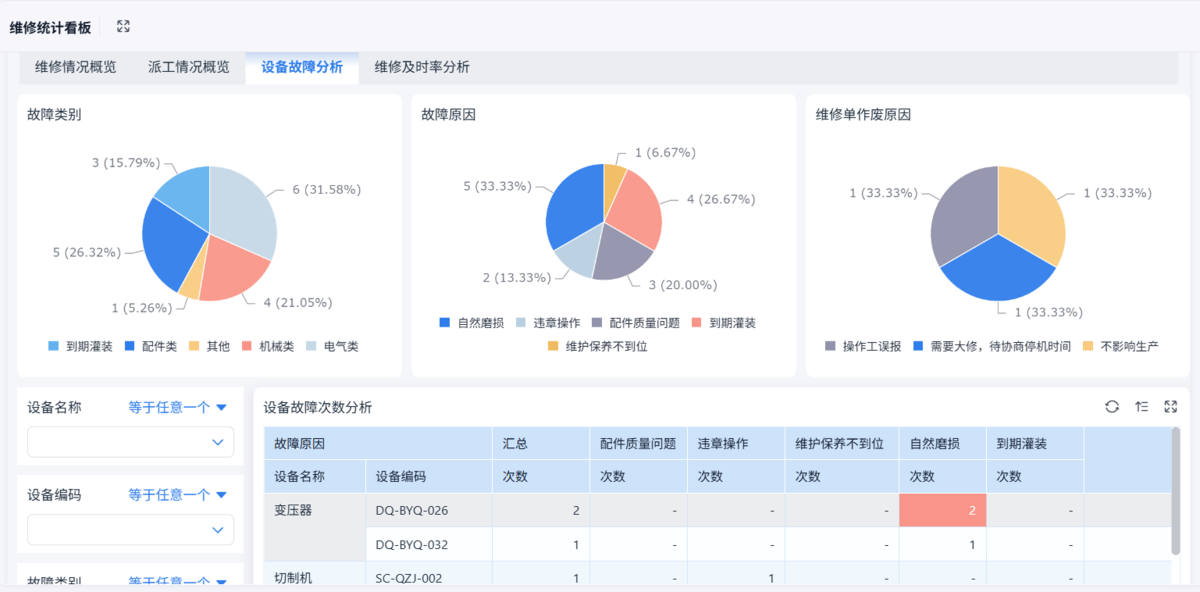
哪类问题最多,就先解决哪类。
第四步:不要贪多,先“狠狠干掉一个问题”
不要分散精力。
选一个最典型的问题,比如:
- 某设备反复停机
- 某部件频繁损坏
然后往下拆:
- 是操作问题?
- 还是保养不到位?
- 还是设计本身有问题?
目标不是“修好”,而是:这个问题以后不再出现。
第五步:把有效做法固化成标准
问题解决后,一定要做一件事:
- 写进点检标准
- 写进操作规范
- 固定保养周期
否则很快会回到原状。
本质是:把经验变成可复制的流程。
第六步:复制,而不是“重新做一遍”
试点跑通之后,再扩到其他区域。
复制的是:
- 方法
- 节奏
- 管理方式
而不是简单复制表单。
第七步:规模一上来,必须用数字化工具承接
TPM在小范围可以靠人工,但一旦扩大,就会出现:
- 点检记录分散
- 故障数据难统计
- 问题跟踪断档
这时候,引入简单的系统会更实际:
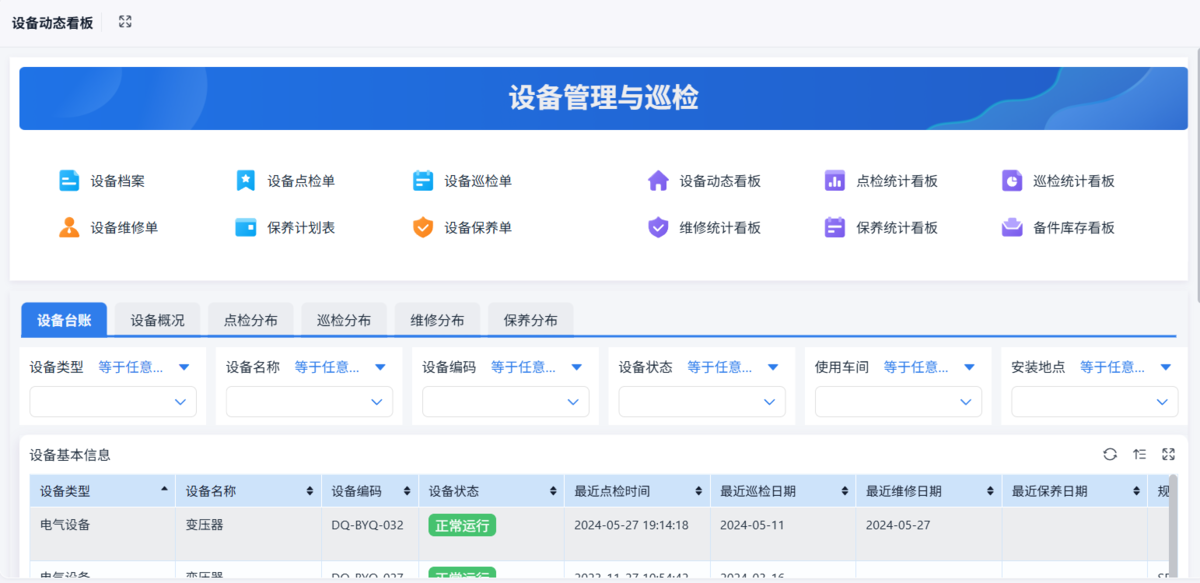
- 点检在线填,自动汇总
- 故障从上报到处理有完整记录
- 数据自动统计,直接看到问题集中在哪
作用不是“上系统”,而是:让TPM从“靠人盯”,变成“靠流程和数据在跑”。
TPM落地的关键不是复杂方法,而是这条路径:
看见问题 → 记录问题 → 解决一个问题 → 固化方法 → 再复制。
只要这个循环能跑起来,TPM就不是口号,而是一个能持续产生效果的机制。
七、说点实在的:TPM值不值得做?
如果只看短期,TPM确实会增加一些工作量:
- 多做检查
- 多做记录
- 多做分析
但从中长期看,它解决的是一个更核心的问题:让生产从“靠运气”,变成“可控制”。
当设备状态稳定下来之后:
- 停机减少
- 计划更准
- 人员不再天天救火
这些变化,最终都会体现在:效率、成本和质量上。
TPM不是把设备修得更快,而是让设备尽量少出问题,本质是把管理重心从“事后处理”前移到“过程控制”。
真正拉开效率差距的,不是设备好坏,而是企业能不能稳定控制设备状态。
如果要开始,不需要一步到位,给一个更实际的做法:
- 先选一条问题最多的产线
- 把点检和基础数据跑起来
- 集中解决一个典型问题
- 再逐步固化和复制
当这套小闭环跑顺之后,再考虑用像简道云这样的工具把点检、故障和数据串起来,让TPM从“靠人执行”变成“靠机制运转”。


