
在很多工厂里,设备管理这件事,表面上看是“有人在做”,但只要稍微往深一点问,就会发现问题并不简单。
设备每天有人巡检,点检表也在填,保养计划也不是没有,但一旦现场出现故障还是同样的场景:
- 问题来得突然
- 原因说不清楚
- 历史也查不完整
- 甚至连“之前有没有异常迹象”都回答不上来
如果你往执行层再追一层,大概率会看到一个共性问题:巡检、点检、保养,这三件事,在实际执行中被混在了一起。
所以,我们不仅仅讲概念,而是从一个更实在的问题切入:
这三件事到底分别在解决什么问题?为什么一旦混在一起,设备管理就一定会失控?
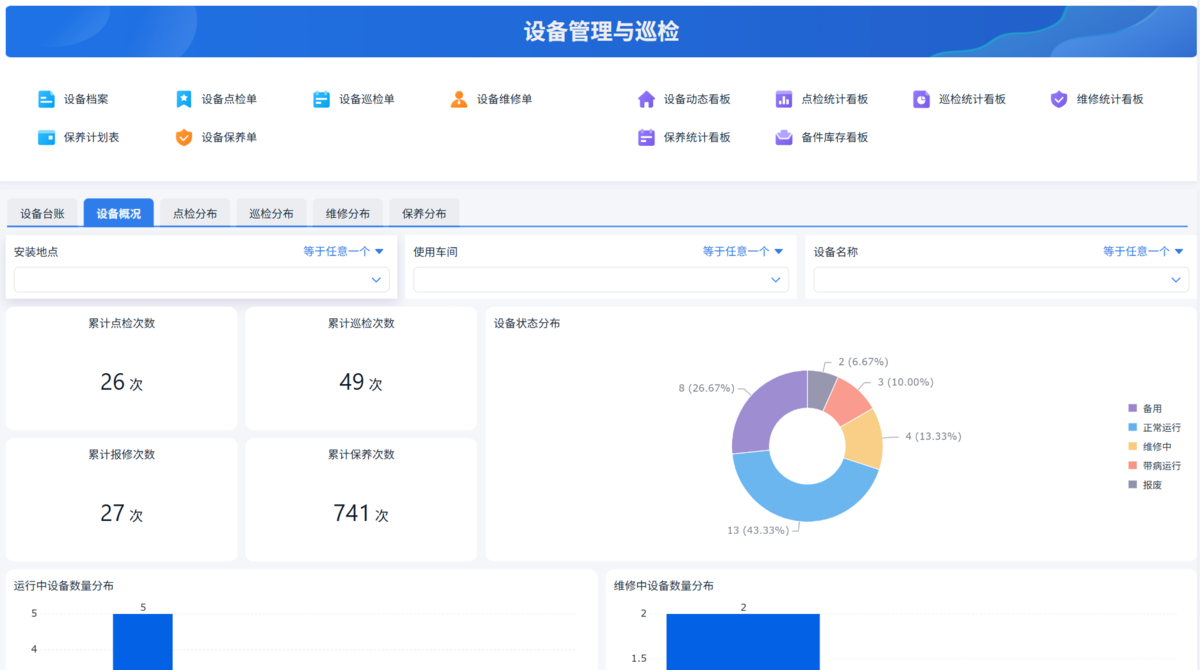
以下解读中所用到的设备管理与巡检系统
已经做成了完整的模板,可直接下载使用: https://www.jiandaoyun.com
一、为什么设备管理管不住?
大多数企业的问题,不是没做,而是做错了方式。
很多现场的管理逻辑,其实是这样的:
- 一张表,既承担巡检,又承担点检
- 一个人,既负责看现场,又负责判断状态
- 保养没有独立节奏,基本依附在“有空的时候”
短期看,这种方式似乎更高效,动作更少、流程更简单,但从管理的角度来看,它有一个很致命的后果——所有动作失去了边界,结果就没有办法被定义。
你无法说清楚:
- 哪些问题是巡检发现的
- 哪些判断是点检确认的
- 哪些风险是保养预防掉的
当动作没有边界,结果就无法归因;当结果无法归因,管理就无法优化。
所以很多企业会陷入一个循环:
做了很多动作 → 但效果不稳定 → 继续加动作 → 管理更混乱
要跳出这个循环,第一步不是加强执行,而是先把三件事彻底拆清楚。
二、核心讲透:巡检、点检、保养分别在干什么?
1. 巡检:用人的感知,尽早发现异常信号
巡检这件事,很多人理解成“检查设备有没有问题”,但这个说法其实是不准确的。
因为巡检的目标,从来就不是确认有没有问题,而是更前置的一步,尽可能早地发现那些还没变成问题的异常信号。
换句话说,巡检不是在找结果,而是在找变化:
- 声音变了、振动变了
- 温度略微上升、颜色出现变化
- 甚至只是“感觉不太对劲”
这些信号往往是模糊的、不精确的,但恰恰是最有价值的。
巡检的意义,就在于把这些“非结构化的信息”尽可能早地捕捉下来。
从动作上看,巡检其实很简单,本质就是五件事:看、听、闻、摸、对比。
但简单并不代表随意,如果没有明确的关注点和异常标准,巡检就很容易退化成走流程。
很多企业巡检做不出效果,通常有三个原因:
第一,没有把巡检项写成“异常导向”。
比如写“检查设备运行情况”,这种表述没有任何约束力,执行的人也不知道重点在哪里。
相比之下,“是否有漏油”“是否有异常噪音”“是否存在松动”,这种描述才是真正可执行的。
第二,把巡检做成了“轻量版点检”。
在巡检里强行加入大量数据填报,比如温度、压力等数值,看起来更专业,实际上反而削弱了巡检的作用。
因为巡检的优势在于快速、灵活、高频,一旦变成数据填报,现场就会开始应付。
第三,巡检发现的问题没有后续。
这是最现实的问题。
如果异常上报之后,没有人跟进处理,巡检人员很快就会形成一种本能——少报问题,避免麻烦。
时间一长,巡检就会彻底失去意义。
所以从管理角度看,巡检必须满足三个条件:
- 有明确的异常项
- 有顺畅的上报机制
- 有人对异常负责
做到这一点,巡检才真正成为问题的前哨。
2. 点检:用标准化数据,判断设备是否处于正常区间
如果说巡检解决的是“有没有异常信号”,那么点检解决的,是一个更明确的问题:当前设备的状态,到底是不是正常?
点检和巡检最大的区别,在于它不再依赖人的主观感受,而是依赖标准和数据。
一个完整的点检动作,至少包含三个要素:
- 检查项,也就是你要测什么,比如温度、电流、压力、转速等
- 标准值,也就是这些指标的正常范围
- 判断结果,也就是当前数据落在什么区间,是正常、预警还是异常
很多企业点检做不出价值,核心问题就在于只做了前两步,没有完成第三步。
现场常见的情况是,数据记录得很完整,但没有人真正去判断这些数据意味着什么。比如温度填了78℃,压力填了0.6MPa,但这些数字本身没有意义,只有放在标准范围里,才能判断出状态。
如果没有标准,或者标准没有被固化,点检就退化成了“记录工作”,而不是“判断工作”。
另一个常见问题是标准不统一。
不同班组、不同人员,对同一数据的理解不一致,导致判断结果不稳定。这种情况下,即使数据再多,也无法形成有效决策。
从更高一层来看,点检真正的价值,其实不在当下判断,而在趋势判断:
- 单次数据异常,可能只是波动
- 但连续几天的数据变化,往往意味着设备状态在发生趋势性偏移
如果点检数据不能沉淀、不能对比、不能分析趋势,那它的价值就被浪费了。
所以,一个有效的点检体系,必须具备三点能力:
- 标准清晰
- 判断自动
- 数据可追溯
只有这样,点检才能真正成为设备状态的“体检报告”,而不是一堆孤立的数据。
3. 保养:通过计划性干预,把问题消灭在发生之前
相比巡检和点检,保养的逻辑更进一步,它不是发现问题,也不是判断问题,而是直接面对一个目标:尽可能让问题不要发生。
从设备生命周期的角度来看,任何设备都会随着使用而逐步劣化,这是不可避免的。但通过合理的保养,可以延缓这种劣化过程,降低故障发生的概率。
保养的核心,不在于修,而在于防。 它是一种主动行为,而不是被动响应。
在实际执行中,保养通常分为三个层级:
- 日常保养
- 定期保养
- 计划性保养
操作工负责基础动作,比如清洁和简单检查;设备人员负责润滑、紧固、调整;专业维护团队则负责更换关键部件和深度维护。
问题在于,很多企业的保养并没有真正形成计划,而是停留在感觉。
- 什么时候做?差不多了就做
- 做了什么?记不清楚
- 有没有按时做?没人追踪
这样的保养,本质上还是被动的,无法起到预防作用。
要让保养真正发挥价值,必须满足三个条件:
- 有明确的周期
- 有刚性的计划
- 有完整的记录
周期决定节奏,计划保证执行,记录支撑优化。缺任何一个,保养都会流于形式。
三件事到底差在哪?
如果一定要用一句话把三者的区别说清楚,可以这样理解:
- 巡检,是在找异常的信号
- 点检,是在判断当前的状态
- 保养,是在干预未来的结果
也可以换一种更直白的说法:巡检是找问题,点检是判问题,保养是防问题。
一旦这三件事混在一起,一定会导致问题发现不及时、判断不准确、预防做不到位。
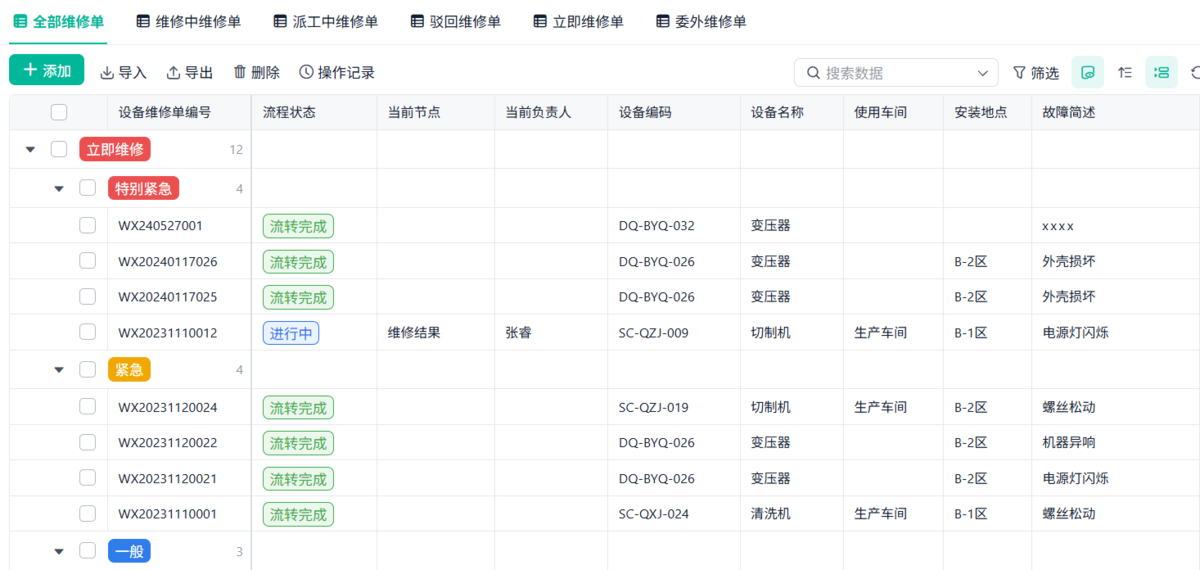
三、如何把巡检、点检、保养真正落地?
听起来不难,那为什么大多数企业会把这三件事做乱呢?
从经验来看,原因其实很简单,但很普遍。
- 没有做动作拆分。 一张表覆盖所有动作,一个人承担所有职责,短期看是“效率”,长期看是“失控”
- 没有把标准固化。 检查项模糊,判断标准不清,导致每个人都在用自己的理解做事
- 没有形成闭环。 发现的问题没有流转,执行的动作没有记录,管理层看不到真实情况
这些问题叠加在一起,就会形成一种状态:大家都很忙,但没有人真正掌握全局。
所以,如果你要从0到1把这套体系搭起来,可以抓住三个关键动作。
- 动作拆分。 巡检、点检、保养分别设计,明确各自的责任人、执行频率和使用表单,不再混用
- 标准固化。 每一个检查项,都必须对应明确的标准和判断规则,让执行不再依赖经验
- 过程留痕。 所有动作都要记录下来,谁做的、什么时候做的、结果如何,都可以被追溯
做到这一步,管理已经从“人治”开始向“规则化”过渡。

但在实际推进中,阻止落地的原因往往不是理念问题,而是工具问题。当你用Excel、纸质表单来承接这些动作时,很容易遇到几件事:
- 表单分散,数据无法统一
- 执行依赖人工提醒,容易遗漏
- 问题上报之后,没有自动流转机制
- 管理层很难实时看到整体情况
这些问题叠加在一起,会让一套本来合理的管理方案,在执行中逐渐失效。
这也是为什么越来越多企业开始引入工具(比如简道云)的原因。本质上不是为了信息化,而是为了把原本依赖人的动作,转化为可以被系统约束和驱动的流程。
以实际应用场景来看:
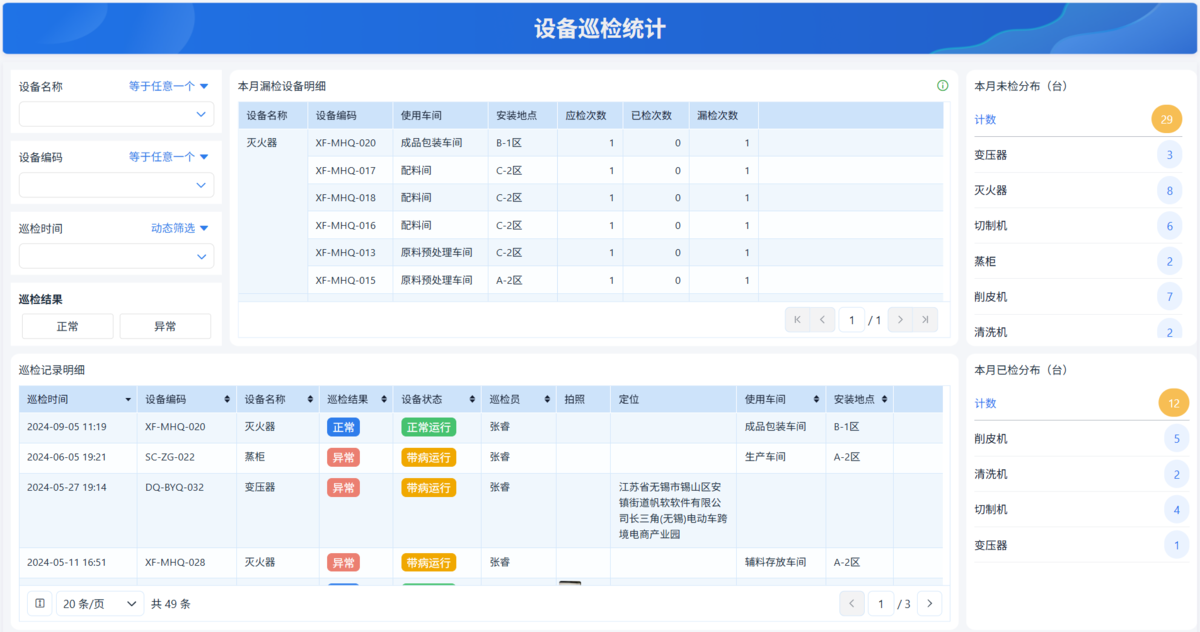
- 巡检可以通过移动端完成,异常现场直接上报,并自动生成待处理问题
- 点检可以把标准写入系统,数据录入后自动判断状态,并持续沉淀形成趋势
- 保养可以提前生成计划,到期自动提醒,执行过程全程留痕
当这些动作被系统承接之后,管理逻辑会发生一个很明显的变化:从人盯人,变成系统盯过程。
像简道云这类工具的价值,也正体现在这里,不是替代人,而是把规则落地,把流程跑通,让管理真正具备持续性。
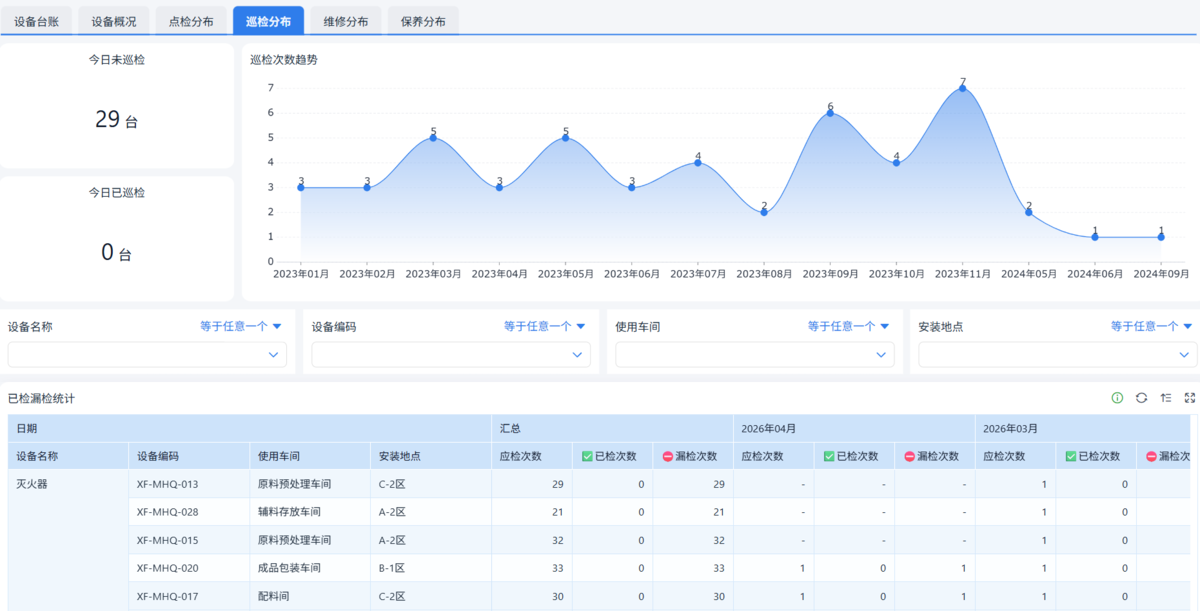
最后说一句最实在的
设备管理这件事,从来不取决于你做了多少动作,而取决于这些动作是否清晰、是否标准化、是否能被持续执行。
当巡检、点检、保养各自归位,再配合一套能够承接流程的系统,你会明显感觉到一个变化:
- 现场不再依赖经验
- 问题开始提前暴露
- 设备状态变得可判断、可追溯、也可优化
这时候,设备管理才真正进入一个稳定、可控的状态。


