
很多人把“点检做了”当成一种结果,甚至当成设备管理做得好的证明:
- 每天按时点检
- 表单填得整整齐齐,记录一大堆温度、压力、电流数据
- 巡检路线安排得明明白白,责任人也清清楚楚
看上去,这套体系很规范,甚至不少企业还上了系统,把所有点检流程都电子化了。
但问题是,设备该坏还是坏,停机该来还是来,异常该反复还是反复。
实际上,问题就出在点检。
点检从来就不是结果,它只是一个动作,是一个手段,是整个设备管理链路里最前面的那个入口。
如果你把入口当终点,那后面的事情,自然就不会发生。
而这,正是绝大多数企业设备管理失效的根本原因。
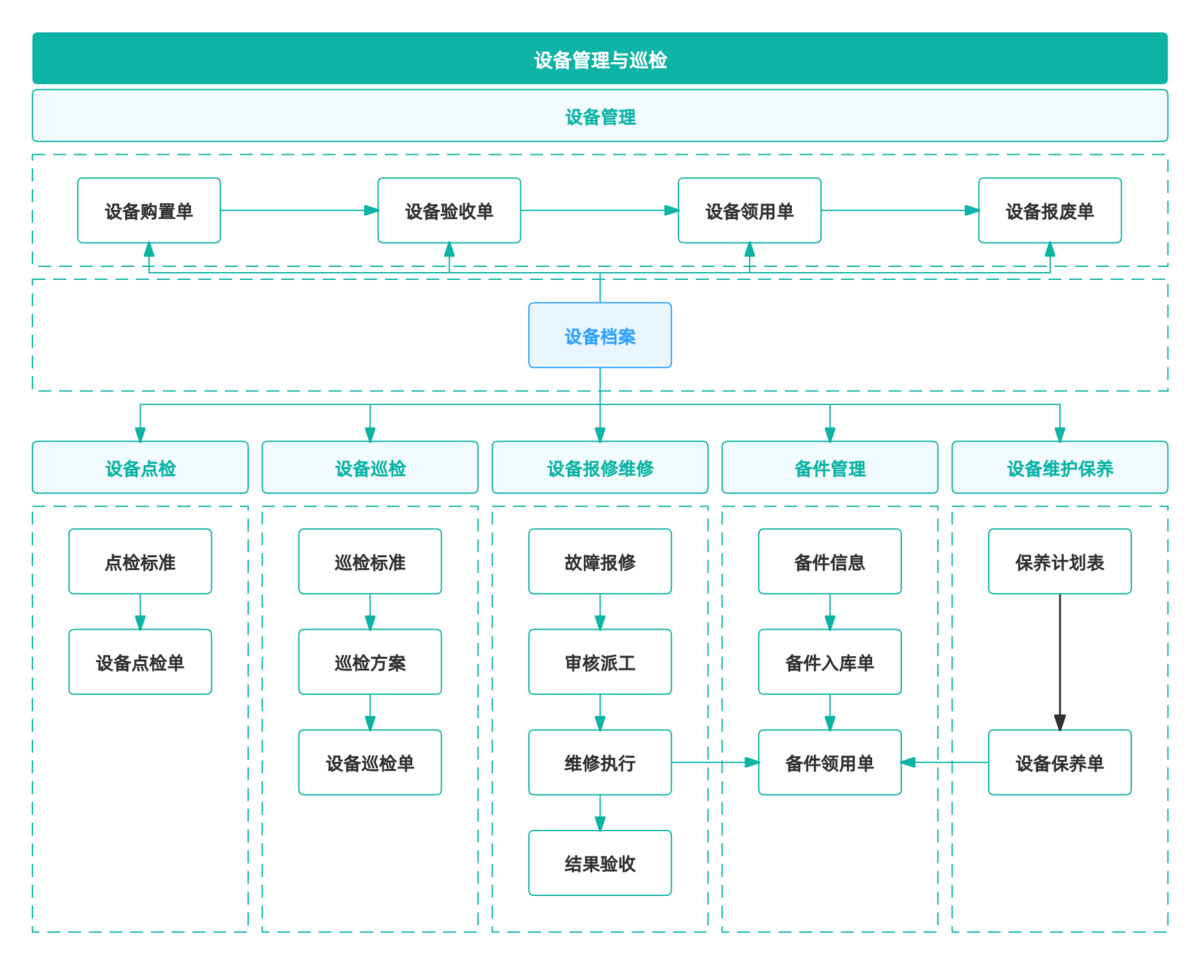
以下解读中所用到的设备管理与巡检系统——
已经做成了简道云模板,可直接参考使用:
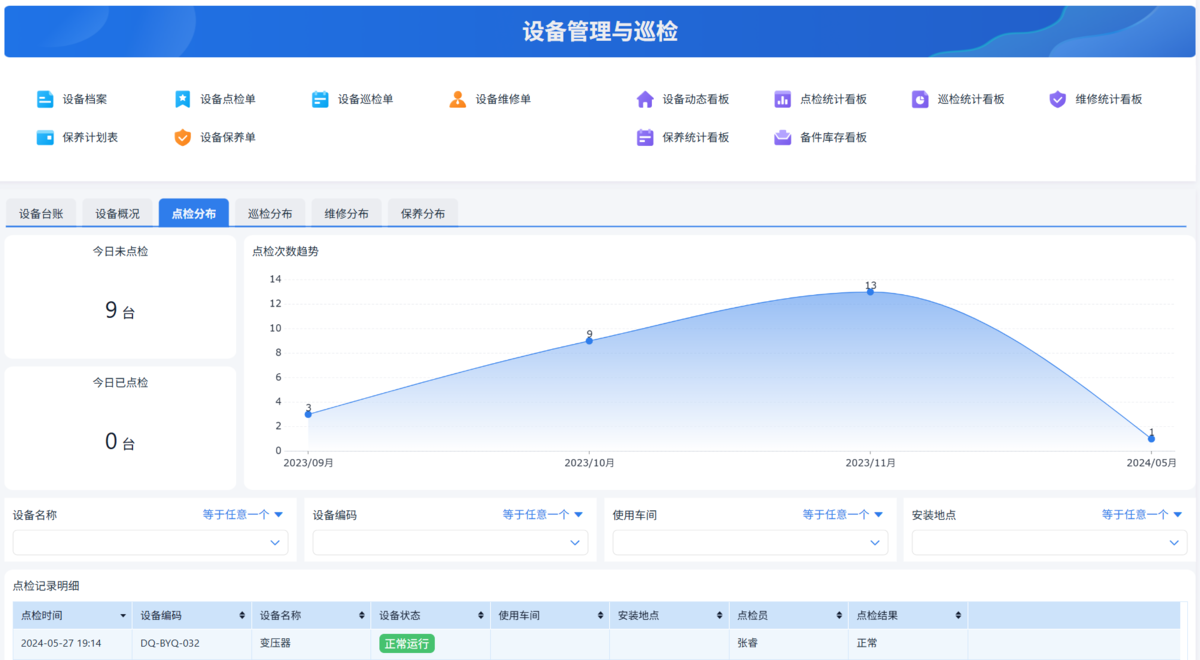
一、为什么只把点检当结果不可行?
这个误区不是因为大家不专业,而是因为大多数企业的管理方式,本身就在引导大家这么做。
1. KPI只考核有没有做
很多企业在设计点检考核的时候,关注的都是这些指标:
- 有没有按时点检
- 有没有漏检
- 表单有没有填写完整
听起来很合理,但问题是这些指标全部都停留在动作层面,没有一个是和结果直接相关的。
于是,现场人员的行为就会自然收敛成:把表填完,就算完成任务。
系统里有完整的点检表单,有时间记录、有责任人、有打卡轨迹,做得越规范,这种行为反而越容易被强化。
因为对一线来说,最确定、最直接的事情,就是把该填的填完。
至于这些数据有没有被用到、有没有触发后续动作,那是另外一回事,甚至很多时候根本没人关心。
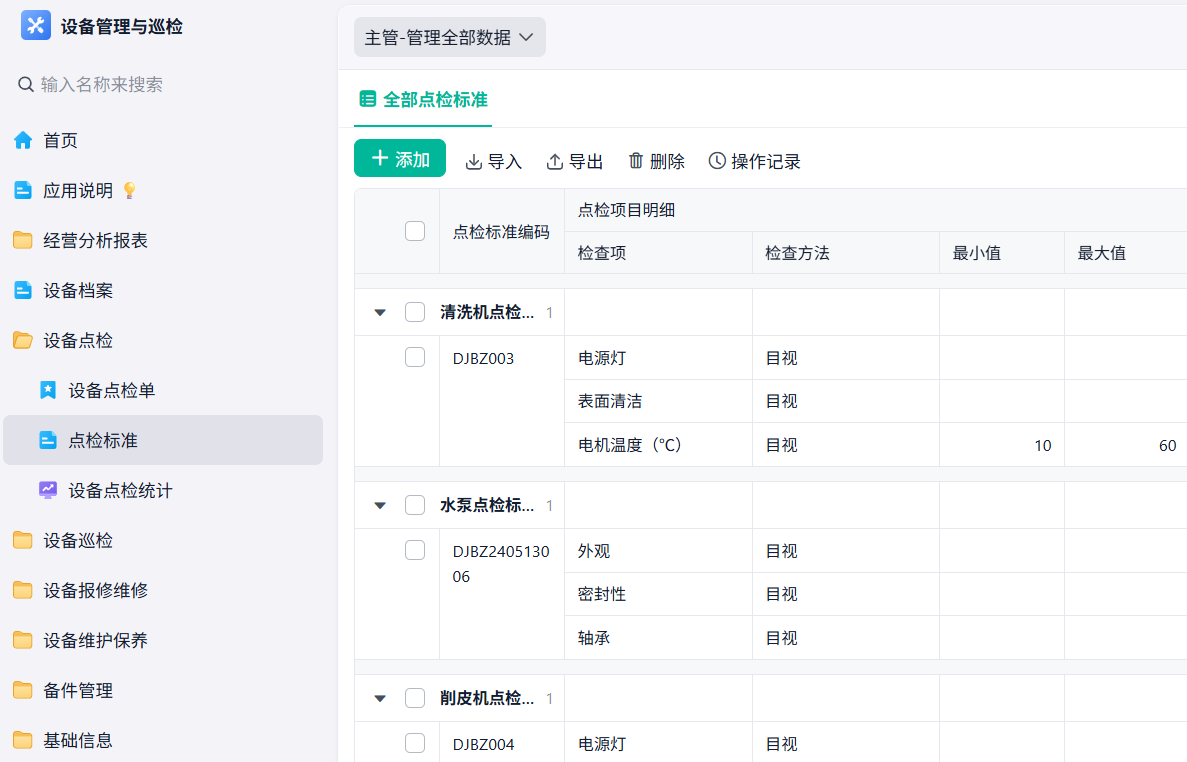
2. 数据停在记录层
点检数据记录完之后,发生了什么?
- 点检记录里写了“轻微异响”,但没有人跟进
- 某个设备温度连续几天偏高,但没有触发任何处理
- 同样的问题反复出现,但没有人去做归类分析
这些记录,看起来都在管理,但实际上只是被动存档。
久而久之,一线人员也会形成一种默契:记录是记录,处理是另外一回事,两者之间没有强关联。
甚至同一个问题,在不同时间、不同人填写的点检表里,被反复记录,但始终没有被真正解决。
这就说明,数据虽然被采集了,但没有进入动作层,也没有驱动任何实际变化。
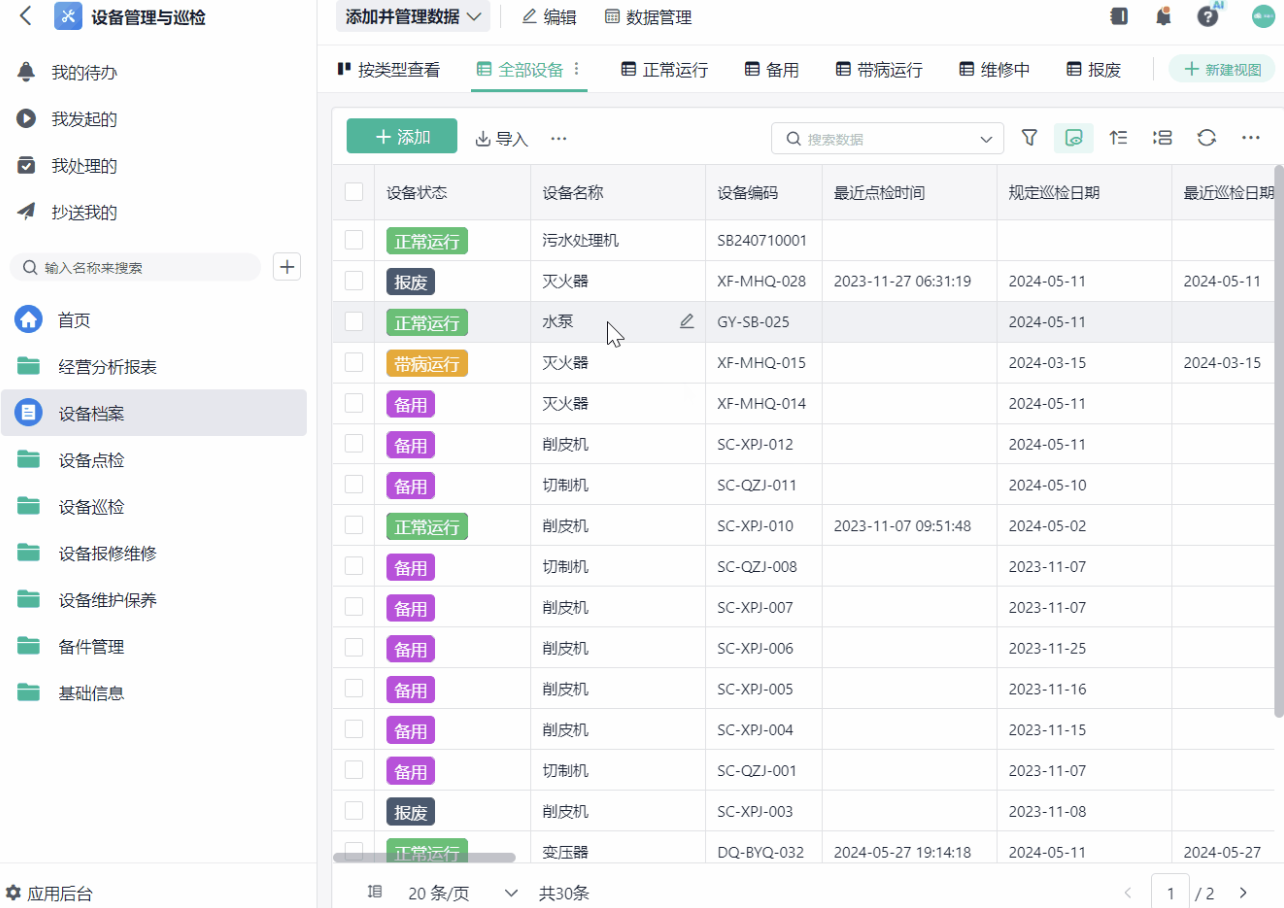
3. 管理层默认过程做了,结果自然会好
还有一个更隐蔽的问题,在管理层。
很多管理者会有一个直觉判断:只要过程被规范了,结果自然就会好。
听起来没错,但这里有一个前提—— 过程必须是有闭环的过程。
点检本来是为了发现问题,但如果发现问题之后,没有明确的处理机制,那这个过程就停在“发现”这一步。
- 问题被记录了,但没有被解决
- 甚至同一个问题,会在不同的点检记录里反复出现
如果你在简道云里没有把“点检→异常→维修→复盘”这一整条链路串起来,那点检就永远只是一个孤立动作。
好的,这里给你补一个“顺着问题自然过渡到工具”的第4点,不硬推产品,而是从“要解决刚才这些断层,必须靠系统承接”这个逻辑切进去。
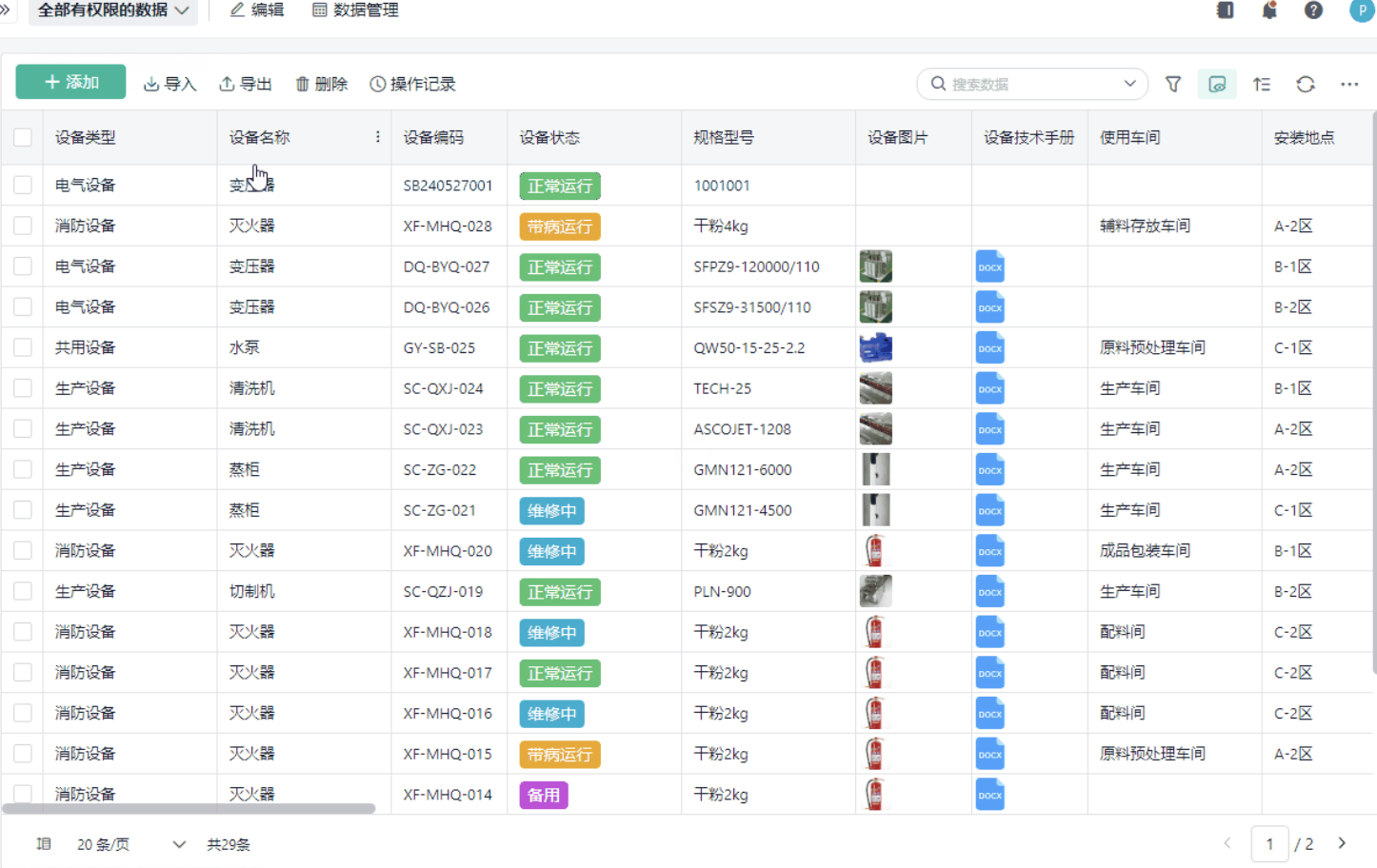
二、点检到底是什么?
要解决问题,首先要把概念讲清楚。
点检到底是什么?很多人把它理解成一种管理动作。
但实际上,点检是一种数据采集手段,是整个设备管理体系的信息入口。
1. 点检的本质,是在收集设备状态数据
你每天在做的点检,本质上是在做三件事:
- 采集设备的运行状态(温度、振动、电流等)
- 记录现场观察到的现象(异响、泄漏、磨损等)
- 做出初步判断(正常 / 异常)
这些信息,本身并不等于管理结果,它只是原材料。
如果你用简道云来做这一层,重点不应该只是能不能填,而是:
- 数据是不是标准化的(避免随意填写)
- 字段是不是结构化的(方便后续分析)
- 录入是不是足够简单(降低执行成本)
点检的价值,不在做了多少,而在这些数据能不能被用起来。
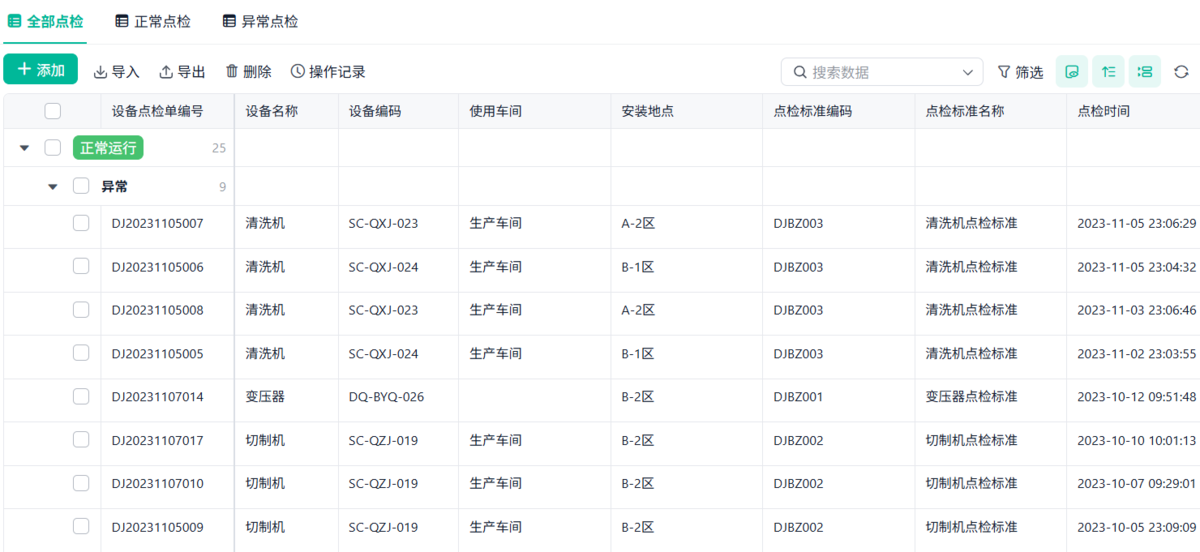
2. 点检的真正价值,在于触发后续动作
点检如果只是停留在记录层,那它几乎没有价值。
它真正的意义,在于触发。
一个有效的点检系统,一定具备这样的能力:当某个指标异常时,系统能够自动做出反应,而不是等人去看、去判断、再去推动。
举几个很具体的例子:
- 温度超过设定阈值,自动生成维修工单
- 同一设备连续3天出现异常,自动升级为重点问题
- 某类故障在一周内出现多次,自动进入分析池
这些能力,在简道云里其实很好实现:
通过流程引擎配置规则,通过条件判断触发节点,通过自动化把数据直接推到对应的人和流程里。
一旦做到这一点,点检就从记录行为,变成了管理入口。

3. 点检的终点,是支撑管理决策
管理层真正关心的,从来不是某一张点检表,而是:
- 哪些设备风险最高
- 哪些问题在反复出现
- 哪些维护动作是低效甚至无效的
这些问题,靠经验是判断不出来的,必须依赖数据。
而点检,就是这些数据的来源。
如果你在简道云里只是停留在表单层,没有把数据汇总成看板,没有做趋势分析,没有做分类统计,那点检数据就无法进入管理层视野。
也就是说,它没有完成从数据到决策的转化。
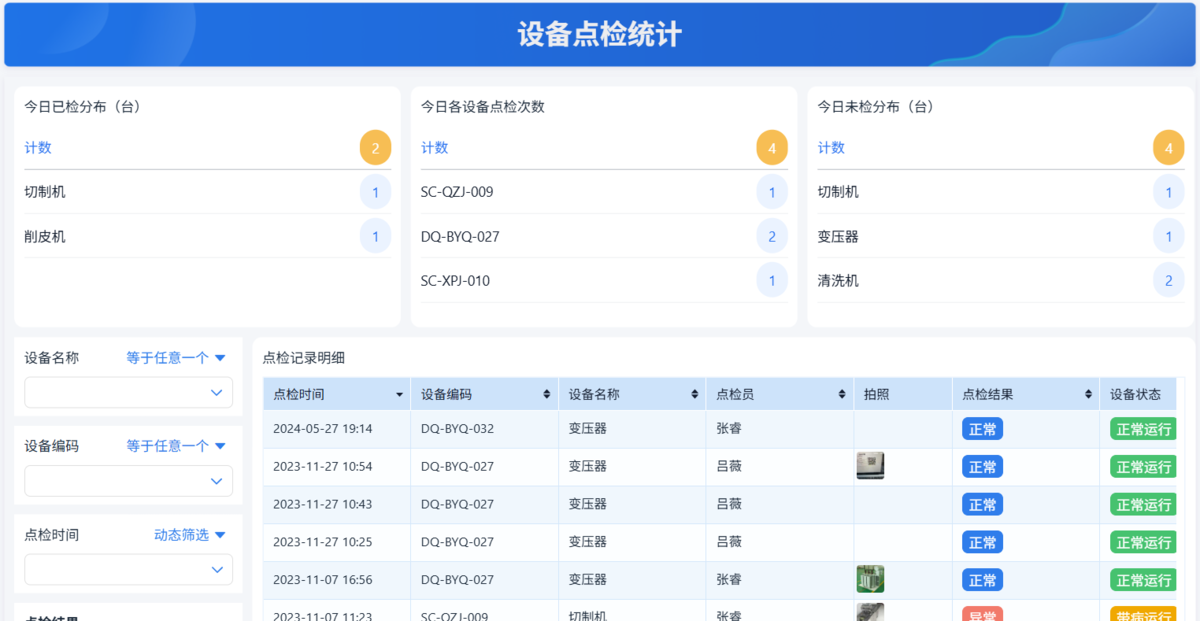
三、把点检变成真正的管理手段
这一步,关键不是多做点检,而是把点检放回它该在的位置,并围绕它构建一整套闭环。
比如可以借用简道云的设备管理与巡检系统,这是对标专业设备管理SaaS的核心场景功能、能够实现设备的全生命周期一体化监管的专业设备管理场景应用系统,把点检做成真正的管理手段。
1. 第一步:把点检表从能填改成可用
很多企业的点检表,最大的问题是——看起来很详细,但实际上不可用。
- 字段很多,但大部分是自由填写
- 描述很全,但每个人写法都不一样
- 数据很多,但没法统计、没法对比
因此,需要做的第一件事,是把点检表重构成结构化数据入口。
具体怎么做?
- 尽量用选择项替代文本输入,比如“正常 / 异常 / 待确认”
- 给关键指标设定明确标准,而不是模糊描述
- 对关键字段做必填和校验,避免漏项和乱填
用简道云的话,可以通过字段类型、校验规则、必填逻辑来实现这些约束。
这一步的目标很简单:让点检数据具备被使用的基础。
2. 第二步:让每一个异常都有去处
点检最怕的,不是没有发现问题,而是发现了问题却没有后续。
所以第二步的关键,是把异常从记录中拆出来,变成独立的管理对象。
需要建立这样的机制:
- 只要标记为异常,就必须触发处理流程
- 每一个异常,都有明确的责任人
- 每一个处理,都有时间要求和状态跟踪
在简道云的设备管理与巡检系统里,这一步可以直接打通:
点检表单 → 自动生成维修工单 → 指派责任人 → 设置处理时限 → 自动提醒和催办。
这样一来,点检就不再是终点,而是整个处理流程的起点。
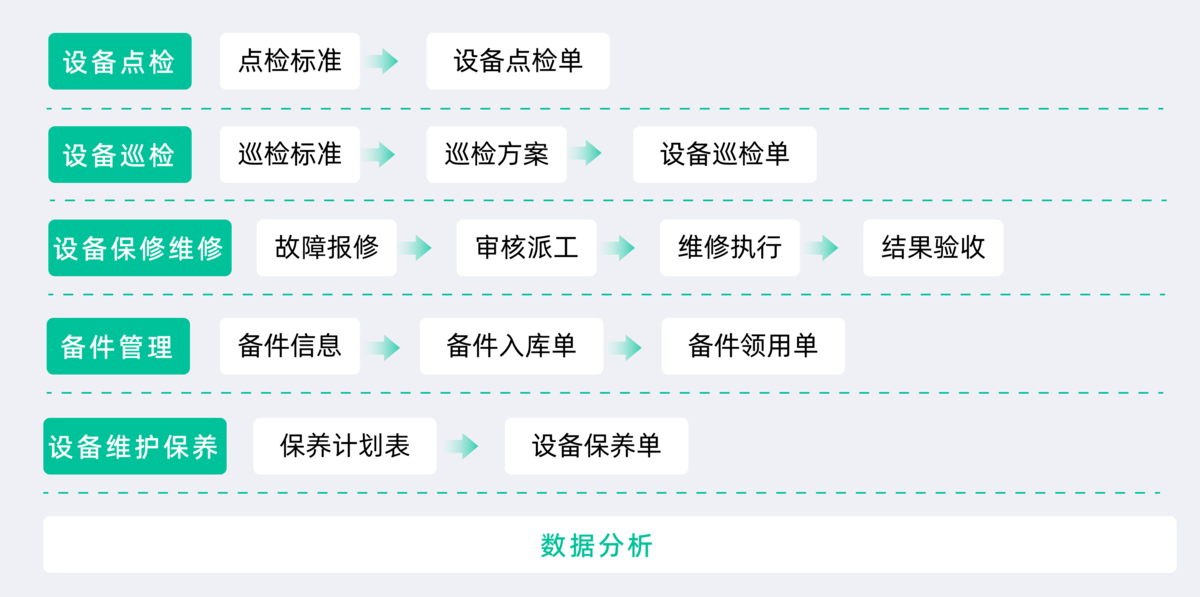
3. 第三步:把处理结果收回来,形成闭环
很多企业其实能做到第二步,但会卡在第三步。也就是问题处理完之后,就结束了。
但真正有价值的是后面的那一步:复盘。
你需要做到:
- 每一个异常都有处理结果记录
- 处理完成后要有验证(是否真正解决)
- 相同问题要能够被归类、统计
在简道云系统中,可以通过流程回写、数据关联,把维修结果反向写回点检记录,同时形成问题库。
这样你就可以明确一些非常关键的问题:
- 哪类问题最常见
- 哪些设备最不稳定
- 哪些处理方式效果最好
这一步的目标是让问题不再重复发生。
4. 第四步:把数据汇总上报,服务管理决策
最后一步,是很多企业忽略的。
前面做的所有事情,如果只是停留在执行层,那管理层依然是看不见。
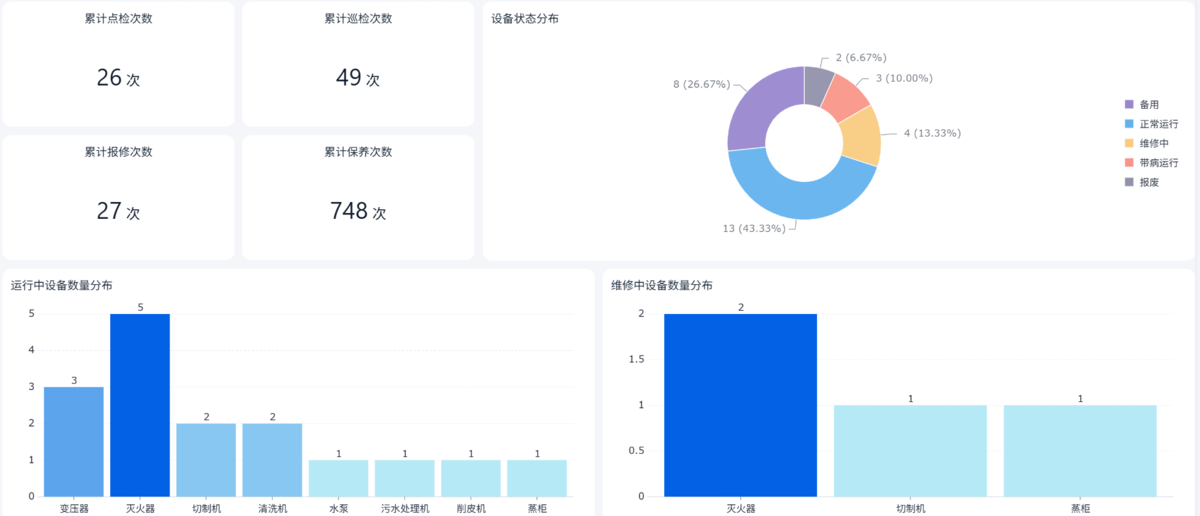
所以需要把这些数据转化成几个核心输出:
- 故障频率排名
- 设备健康度评估
- 维修响应效率
- 异常处理及时率
用简道云的可视化看板,可以把这些指标实时展示出来,并支持多维度筛选。
当管理层打开系统,看到的不再是一堆表单,而是清晰的结论时,点检的数据,才真正产生了价值。
四、一个很典型的变化:从填表到系统驱动
很多企业在做完上述改造之后,会有一个很明显的变化。
在改造之前:
- 点检是任务,是考核,是每天必须完成的一件事
- 维修靠人盯,问题靠人记,经验大于数据
- 系统只是记录工具,不参与管理
在用简道云把整条链路打通之后:
- 点检变成了入口,而不是终点
- 异常自动流转,责任和动作清清楚楚
- 数据开始积累,并逐渐替代经验,成为决策依据
本质上,点检是从人推动流程,变成了系统驱动管理。
这不是工具带来的变化,而是管理方式的改变。
最后说一句实话
当你把点检当成结果的时候,你关注的是:有没有做、做得够不够、表填得完整不完整。
但当你把点检当成手段的时候,你关注的就会变成数据有没有用、问题有没有被处理、系统有没有形成闭环。
两种思路,看起来只差一步,但最后的效果,会完全不同。
像简道云这样的工具,价值也从来不在“让你更方便填表”,而在于:
帮你把这些本来断开的环节,真正连成一套能跑起来的系统。
真正有效的设备管理,一定不是某一个动作做得多好,而是这条链路是否完整:
点检 → 发现问题 → 触发处理 → 闭环复盘 → 数据决策
少了任何一环,点检都会变成形式主义。


