进销存取数方法详解,如何高效准确取数?
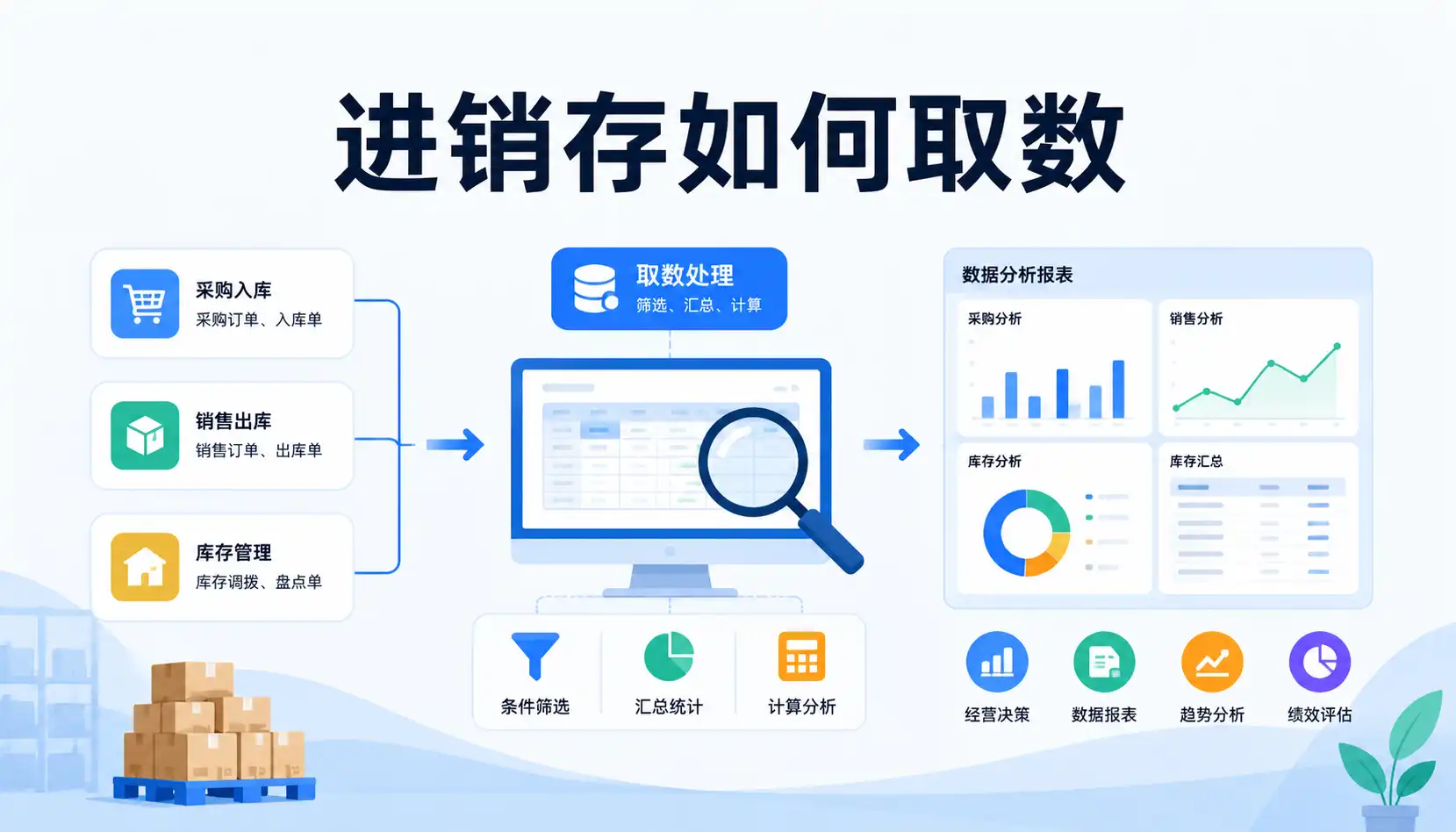
在进销存管理中,要想真正做到数据驱动决策,就必须解决“取数”的问题。高效准确的进销存取数方法,应兼顾数据口径统一、实时性、可追溯性与易操作性。通过合理设计进销存系统的数据结构、优化出入库业务流程、设置清晰的统计口径,并结合 SQL 报表、BI 工具和 API 接口等技术手段,可以大幅减少对人工导出的依赖,降低错漏风险。在多仓库、多门店、多渠道环境下,通过分层取数、预聚合、缓存与定时任务,既能保证库存和销售数据实时同步,又能满足财务、运营、采购等不同角色的分析需求,从而构建稳定可靠的进销存数据体系,支撑企业精细化运营与业务扩张。
《进销存取数方法详解,如何高效准确取数?》
一、进销存取数的核心目标与常见误区 🎯
1.1 为什么“进销存取数”会变成大问题?
在很多企业里,进销存系统(Inventory Management / ERP / POS + WMS)本身并不算复杂,难的是如何从系统里取到“可用”的数据。典型场景包括:
- 老板只想看一个“今天卖了多少钱、赚了多少”的销售报表,却需要运营下载多个 Excel 拼接、透视。
- 仓库想盘点库存,却发现系统库存在不同报表中不一致,无法判断哪个数字可信。
- 财务对进销存取数感到头疼:采购入库、销售出库、退货、调拨、盘盈盘亏相关数据散落各处。
造成“取数困难”的根本原因在于:
- 没有统一的数据口径(如“库存”到底是实物库存、可用库存,还是账面库存?)
- 业务流程设计不规范,导致同一业务发生多次记录、重复统计。
- 进销存系统中表结构不清晰、字段含义模糊。
- 取数方式过于依赖人工导出+Excel 手工统计,没有结构化的取数方法。
高效的进销存取数方法的目标,是在任何时间点,都能快速、准确、稳定地得到:进货、销售、库存、毛利等核心业务数据,并且所有角色看到的数据是一致的。
1.2 进销存取数的四大核心目标
在设计进销存取数方案时,应围绕四个目标展开:
- 准确性
- 数据无重复、无缺失、无混淆。
- 一张单据对应一条或一组明确的数据记录。
- 各模块之间(库存、销售、财务)的数据可以对得上。
- 一致性
- 不同报表、不同业务口径需要有明确约定。
- 同样的统计维度,在不同时间、不同角色查看时,应保持逻辑一致。
- 实时性 / 时效性
- 对于库存与销售,通常需要准实时数据。
- 对于经营分析、财务分析,接受 T+1 或 T+N 统计,但要确保稳定输出。
- 可复用性
- 常用取数逻辑能沉淀为固定报表或 API 接口。
- 避免每次取数都“重新来一遍”,提高取数效率。
1.3 常见的进销存取数误区
在实际项目中,经常看到以下问题:
-
误区 1:只靠 Excel 导出拼表
-
从进销存系统分别导出“采购明细”“销售明细”“库存明细”,再用 VLOOKUP 拼表。
-
风险:字段匹配错误、时间跨度过大导致 Excel 卡死、新增业务逻辑后旧模板失效。
-
误区 2:只看单一报表,不看取数口径
-
比如只看“当前库存表”,却不知道它是否包含在途库存、委外库存或锁定库存。
-
导致盘点对不上的时候,完全不知道差异从何而来。
-
误区 3:多个系统同时维护,不做统一
-
电商平台有自己的库存,线下门店有 POS,仓库有 WMS,财务有独立的账务系统。
-
取数时从多个系统各自导出,手工“对齐”,差异无处不在。
-
误区 4:忽略历史变更和追溯需求
-
只看当前数,不保留变更记录。以后需要追溯“某天当时的库存或售价”几乎不可能。
要避免上述问题,需要从数据模型设计、流程规范、系统能力和取数方式四个角度综合改造。
二、进销存数据结构与基础口径:取数之前必须搞清楚 📊
在谈“如何取数”之前,必须把基础问题搞清楚:系统里的数据是如何存储的?关键字段是什么? 只有理解了进销存的数据结构,才能设计出稳定可靠的取数方法。
2.1 典型进销存系统的核心数据表
以常见的进销存/ERP 为例,通常会包含如下核心表(逻辑层面):
| 模块 | 关键业务对象 | 常见表名示例(逻辑) | 说明 |
|---|---|---|---|
| 基础资料 | 商品 / 物料 | goods / products | SKU、条码、规格、分类等 |
| 基础资料 | 仓库 | warehouses | 仓库编码、类型、所属公司等 |
| 基础资料 | 往来单位(供应商、客户) | vendors / customers | 结算方式、信用额度等 |
| 采购 | 采购订单 | purchase_orders | 计划进货,可能未入库 |
| 采购 | 采购入库单 | purchase_receipts | 实际到货入库 |
| 销售 | 销售订单 | sales_orders | 客户下单,可能未发货 |
| 销售 | 销售出库单 | sales_deliveries / invoices | 实际发货/开票单据 |
| 仓储 | 调拨单 | transfers | 仓库间移动 |
| 仓储 | 盘点单、盘盈盘亏 | stock_counts, adjustments | 调整库存的业务凭证 |
| 库存 | 库存流水 / 库存台账 | inventory_transactions | 每一条出入库明细 |
| 库存 | 当前库存汇总表 | inventory_balances | 按商品+仓库汇总的库存数 |
| 财务 | 收款、付款、费用 | payments, receipts, expenses | 与进销存数据联动做毛利、利润 |
在实际系统中,这些表名会有差异,但逻辑结构基本类似。 理解这些表的结构,是进行高效取数的基础。
2.2 关键字段与数据关系
在每一类业务表中,通常会有两级结构:
- 单据主表(Header):记录单号、业务日期、往来单位、仓库、业务员等。
- 单据明细表(Detail):记录商品、数量、单价、金额、批次等。
例如:销售出库单
- 主表:
sales_delivery_header - 字段示例:
bill_no、bill_date、customer_id、warehouse_id、salesman_id、status等。 - 明细表:
sales_delivery_detail - 字段示例:
bill_no、line_no、goods_id、qty、unit_price、amount、tax_rate等。
取数时通常需要:
- 按时间统计:
bill_date(不要混淆录入时间与业务日期)。 - 按商品统计:
goods_id+ 商品维表中的分类、品牌等。 - 按仓库统计:
warehouse_id。 - 按客户或供应商统计:
customer_id/vendor_id。 - 按业务员/部门统计:
salesman_id/department_id。
设计取数方案时,必须提前统一这些字段的含义与使用规则,否则不同报表间无法对齐。
2.3 进销存取数中的关键口径定义
要想“取数准确”,口径定义比 SQL 技术更重要。常见需要统一的口径包括:
- 库存口径
| 名称 | 说明 |
|---|---|
| 实物库存 | 仓库中实际存在的商品数量(包含锁定/占用) |
| 可用库存 | 实物库存 − 已锁定(已分配给订单但未发货) |
| 在途库存 | 已采购但未入库,或在调拨途中 |
| 账面库存 | 系统记录的库存,有时包含未审核单据的影响 |
取数时要明确:是看当前实物库存还是可用库存,是否包含未审核单据。
- 销售口径
| 维度 | 常见选项 |
|---|---|
| 时间 | 下单日期、发货日期、签收日期、开票日期 |
| 金额 | 含税金额、不含税金额、应收金额(扣除折扣后) |
| 数量 | 发货数量、签收数量、退货后净数量 |
- 成本与毛利口径
- 成本类型:移动加权平均成本、批次成本、标准成本等。
- 毛利:销售收入 − 销售成本(有时需考虑运费、促销费用摊销)。
- 多组织/多仓库口径
- 是否跨公司统计?
- 是否汇总所有仓库?是否区分线上仓/线下仓/第三方仓?
在进销存取数方案中,一般会为每一个常用指标写出清晰的口径公式,作为后续 SQL / 报表 / BI 的统一依据。
三、常见进销存取数场景与需求分析 🧩
不同角色对进销存取数的需求完全不同,设计统一的取数体系时,要覆盖核心场景。
3.1 老板与管理层:看整体经营与趋势
典型诉求:
- 每日/每周/每月的销售额、毛利、毛利率。
- 库存周转天数、资金占用情况。
- 各渠道、各门店、各区域的销售排名与盈利情况。
- 爆款商品与滞销商品分析。
所需数据主要来自:
- 销售出库明细 + 成本数据 + 客户维度。
- 库存余额 + 采购入库 + 销售出库 + 调拨 + 盘点。
- 部门或门店维度的收益和费用。
取数特点: 偏汇总、趋势型,对实时性要求中等(T+1 即可),更看重准确性和口径统一。
3.2 采购与供应链:看缺货、在途与预测
典型诉求:
- 当前库存 + 在途采购 + 预估需求(销售预测)。
- 哪些商品需要补货?补多少?什么时候下单?
- 供应商交期表现、采购价格变化。
所需数据主要来自:
- 商品维表(安全库存、最小订购量)。
- 采购订单 + 采购入库 + 退货。
- 销售订单(未发货) + 销售历史。
- 库存余额与在途库存。
取数特点: 要求较高的实时性,尤其是多渠道订单一起冲库存时;对“库存准确性”极度敏感。
3.3 仓库与运营:看库存与出入库效率
典型诉求:
- 实时库存、按仓位或批次的库存。
- 出入库效率:每日出库单量、件数,波次拣货效率。
- 盘点差异、损耗情况。
所需数据主要:
- 库存流水表(inventory_transactions)。
- 库存余额表。
- 出入库单据(入库、出库、调拨、盘点)。
取数特点: 偏操作型,要求实时性高;取数以系统的实时查询和操作界面为主,报表为辅助。
3.4 财务与结算:看对账与利润
典型诉求:
- 对供应商的应付账款,对客户的应收账款。
- 不同渠道的收入确认与成本结转。
- 商品毛利、客户毛利、部门毛利分析。
- 与总账系统的对账。
所需数据来自:
- 采购与销售的出入库单据。
- 价格/成本数据。
- 收款、付款、费用等财务单据。
- 期初余额表。
取数特点: 以准确性与可追溯性为首要目标,可以接受 T+1 或 T+N 出表,要求能追踪到每一条数据的来源凭证。
3.5 电商与全渠道:看订单与库存同步
典型诉求:
- 多平台(Amazon、eBay、Shopify、独立站等)订单统一汇总。
- 线上线下一盘货,避免超卖和库存死角。
- 渠道销量、毛利、促销效果分析。
所需数据来自:
- 各电商平台 API 订单数据。
- 进销存/ERP 系统的库存与采购数据。
- 营销活动与折扣配置。
取数特点: 多系统、多来源,对接 API,要求有统一的数据中台或中间层;取数逻辑复杂、对去重与归因要求高。
四、进销存取数的具体方法与技术路径 🛠️
这一部分是本文的重点:进销存取数到底可以怎么做?应该用哪些工具、哪些技术? 我们按常见方式拆解说明,并给出各自适用场景。
4.1 方式一:系统内置报表取数(零技术门槛)
特点:
- 直接使用进销存系统自带的报表功能,如“采购明细表”“销售汇总表”“库存余额表”等。
- 通常支持筛选条件(日期、仓库、客户、商品等)和导出 Excel。
优点:
- 上手快,对业务人员友好。
- 对口径相对统一(系统预设好统计规则)。
- 适合作为“基础事实”使用,如库存余额、销售流水等。
缺点:
- 灵活性有限:要做复杂的维度组合或自定义指标时力不从心。
- 报表结构往往固定,难以做进一步加工分析(例如联动多表数据)。
- 当数据量较大时,系统内报表性能可能成为瓶颈。
适用场景:
- 日常操作型查询:某个客户最近订单、某商品当前库存等。
- 初期数据分析:从系统内置报表导出为 Excel 做二次分析。
- 小团队或业务复杂度不高的阶段。
4.2 方式二:Excel 导出 + 手工分析(经典但危险)
这种方式非常普遍:从进销存系统导出多张报表,在 Excel 里用透视表、函数和 Power Query 做分析。
常见步骤示例:
- 导出“销售出库明细表”(包含商品、数量、售价、金额、日期等)。
- 导出“商品资料表”(包含商品分类、品牌、成本价或成本表关联字段)。
- 在 Excel 中用 VLOOKUP/XLOOKUP 关联商品资料,再计算毛利、毛利率。
- 用透视表按日期、分类、门店等做统计。
优点:
- 极其灵活,对报表结构完全可控。
- 不依赖 IT 或开发,运营/财务人员即可完成。
- 对小数据量(< 5 万行)场景非常实用。
缺点:
- 易出错:函数引用错误、复制粘贴遗漏、字段名改变等都会毁掉结果。
- 难以复用:每次导出数据都要手动更新、重新调整。
- 不利于协同:同一指标的口径容易在不同分析中发生漂移。
风险管控建议:
- 为常用分析建立固定的 Excel 模板和说明文档。
- 尽量使用 Power Query / Power Pivot 管理数据源,减少手动操作。
- 在条件允许时,尽快将“高频分析模型”迁移到更结构化的工具中(例如 BI 平台或低代码系统)。
4.3 方式三:数据库直连 + SQL 取数(专业且通用)
对数据量中大型、分析需求复杂的企业来说,通过 SQL 从数据库直接取数是最具通用性也最稳妥的方式。
4.3.1 进销存数据库取数的基本流程
- 确定数据库类型与访问方式
- 常见类型:MySQL、PostgreSQL、SQL Server、Oracle 等。
- 安全要求:只开放只读账号,权限限制在必要的表范围内。
- 梳理核心表结构与字段
- 与实施顾问或开发确认每张表的作用、关联关系。
- 制作一份简单的数据字典(表名、字段名、含义、是否必填)。
- 编写基础 SQL 查询
- 如“销售明细取数”、“库存余额取数”等。
- 使用 INNER JOIN / LEFT JOIN 关联商品、客户、仓库等维度表。
- 封装为视图或存储过程
- 将稳定的取数逻辑封装为数据库视图或存储过程,供报表工具或 BI 使用。
- 避免每个分析人员直接拼写复杂 SQL。
4.3.2 示例:按日汇总销售额与毛利
以下为逻辑示例(字段名需按实际系统调整):
SELECTsd.bill_date,g.category_id,SUM(sd.qty) AS total_qty,SUM(sd.amount) AS sales_amount,SUM(sd.cost_amount) AS cost_amount,SUM(sd.amount) - SUM(sd.cost_amount) AS gross_profit,ROUND((SUM(sd.amount) - SUM(sd.cost_amount)) / NULLIF(SUM(sd.amount), 0),4) AS gross_marginFROMsales_delivery_detail sdJOINgoods g ON sd.goods_id = g.goods_idWHEREsd.bill_date BETWEEN '2026-05-01' AND '2026-05-31'AND sd.status = 'POSTED' -- 只统计已过账单据GROUP BYsd.bill_date,g.category_idORDER BYsd.bill_date,g.category_id;要点说明:
status = 'POSTED'/AUDITED这样的条件,可以确保只统计已审核的销售数据。cost_amount可以来自单据明细表,或根据成本方法计算后存入字段。- 使用
NULLIF避免除以 0 导致错误。
4.3.3 示例:按商品、仓库统计当前库存
SELECTit.goods_id,it.warehouse_id,SUM(CASE WHEN it.tran_type IN ('PURCHASE_IN', 'TRANSFER_IN', 'ADJUST_IN')THEN it.qty ELSE 0 END) -SUM(CASE WHEN it.tran_type IN ('SALE_OUT', 'TRANSFER_OUT', 'ADJUST_OUT')THEN it.qty ELSE 0 END) AS qty_on_handFROMinventory_transactions itWHEREit.tran_date <= CURRENT_DATEGROUP BYit.goods_id,it.warehouse_id;或从系统的库存余额表中直接查询:
SELECTgoods_id,warehouse_id,qty_on_hand,qty_availableFROMinventory_balances;推荐实践: 将上述 SQL 封装为视图,例如:
CREATE VIEW v_daily_sales_gross_profit ASSELECT ...;然后报表工具直接查询 v_daily_sales_gross_profit,避免重复编写 SQL。
4.4 方式四:BI 工具 + 数据仓库(适合多维分析)
当企业的进销存数据量增大、分析维度增多(例如商品维、客户维、区域维、渠道维、时间维等),就适合采用 BI 工具 + 数据仓库的方式。
常见国际 BI 工具:
- Microsoft Power BI
- Tableau
- Qlik Sense
- Looker(Looker Studio for Google)
典型架构:
- 从进销存数据库抽取数据到数据仓库(如 Amazon Redshift、Snowflake、Google BigQuery、PostgreSQL 等)。
- 在数据仓库里建立事实表(销售事实、库存事实)和维度表(商品、时间、客户、仓库等)。
- BI 工具通过直连或导入方式连接数据仓库,构建可视化报表与仪表盘。
- 定时刷新数据(如每小时、每天)。
优势:
- 支持大数据量、多维度的交互分析。
- 可以方便地定义指标、维度和层级(如年-季-月-日)。
- 支持权限控制、共享与协同分析。
挑战:
- 实施成本和技术门槛较高,需要数据工程和数仓建模能力。
- 对中小企业而言,投入需要权衡;如果业务尚不复杂,可考虑用低代码报表系统或 SaaS BI 替代。
4.5 方式五:API 对接与数据中台(多系统集成)
当企业存在多个业务系统(电商平台、独立站、线下 POS、WMS、第三方物流等),进销存取数往往要通过 API 接口 实现统一。
典型步骤:
- 各系统提供开放 API(RESTful / GraphQL 等),输出订单、库存、商品等数据。
- 中台系统定时或实时调用 API,同步数据到统一数据库或消息队列。
- 在中台层做去重、合并、口径统一(如订单状态、退款规则、库存逻辑等)。
- 报表和分析系统只对接中台,而不直接连接各业务系统。
适合场景:
- 跨境电商卖家,连接 Amazon、eBay、Walmart、Shopify 等多平台。
- O2O 或全渠道零售企业,线下门店 POS + 线上商城 + 小程序等。
- 需要实时库存同步、防止超卖。
关键点:
- 设计统一的商品编码、仓库编码、渠道编码。
- 明确订单流转状态(已下单、已支付、已发货、已签收、已退款等)与库存扣减时机。
- 对接口调用做日志记录,确保问题可追溯。
4.6 方式六:低代码进销存与报表平台(结合灵活与规范)
对于很多中小企业来说,完全定制化的 ERP/BI 成本较高,而传统的纯 Excel 模式又难以支撑多仓、多渠道的业务。此时可以考虑低代码进销存系统或通用低代码平台:
此类平台通常具备:
- 自定义数据表结构(商品、客户、订单、库存流水等)。
- 快速搭建表单、流程和权限控制。
- 内置统计分析与可视化报表能力。
- 提供 API,可与外部电商平台或财务系统对接。
在这样的场景中,系统就是基于“取数需求”来设计的,数据结构与报表一开始就紧密耦合起来,能显著简化后期取数工作。
举例来说,如果你需要一个可快速落地的进销存数据管理与取数模板,可以考虑使用像 简道云进销存 这类低代码进销存解决方案:在其中可以直接配置采购、销售、库存等核心模块的字段和流程,并通过可视化报表进行多维统计分析,降低 SQL 与编码门槛,适合缺乏专业 IT 人员的团队使用。
五、常见关键指标的进销存取数示例(口径+取数逻辑)📐
这一部分从实战角度出发,列举关键指标的口径和取数思路,便于套用。
5.1 销售额与销售数量
指标定义:
- 销售额(含税):在统计时间区间内,已发货/已完成的销售订单金额合计。
- 销售额(不含税):不含税金额合计。
- 销售数量:发货数量(数量基于销售出库单)。
取数逻辑:
SELECTsd.bill_date,SUM(sd.qty) AS total_qty,SUM(sd.amount_tax_included) AS sales_amount_with_tax,SUM(sd.amount) AS sales_amount_without_taxFROMsales_delivery_detail sdJOINsales_delivery_header sh ON sd.bill_no = sh.bill_noWHEREsh.bill_date BETWEEN :start_date AND :end_dateAND sh.status = 'POSTED'GROUP BYsd.bill_date;注意区分:
bill_date:业务日期 vscreated_at:录入日期。- 是否统计退货单:退货可以为负数数据,或单独统计后再做净额。
5.2 毛利与毛利率
指标定义:
- 毛利 = 销售收入 − 销售成本。
- 毛利率 = 毛利 / 销售收入。
取数逻辑关键:
- 成本来源:
- 单据行上的成本字段(推荐方式)。
- 或根据成本方法(如移动加权平均)动态计算。
示例 SQL(假设单据行有 cost_amount 与 amount):
SELECTg.category_id,SUM(sd.amount) AS sales_amount,SUM(sd.cost_amount) AS cost_amount,SUM(sd.amount) - SUM(sd.cost_amount) AS gross_profit,ROUND((SUM(sd.amount) - SUM(sd.cost_amount)) / NULLIF(SUM(sd.amount), 0),4) AS gross_marginFROMsales_delivery_detail sdJOINgoods g ON sd.goods_id = g.goods_idJOINsales_delivery_header sh ON sd.bill_no = sh.bill_noWHEREsh.bill_date BETWEEN :start_date AND :end_dateAND sh.status = 'POSTED'GROUP BYg.category_id;5.3 库存余额、周转率与周转天数
指标定义:
- 库存余额:某时点库存数量或金额(数量 × 成本单价)。
- 库存周转率(期间) = 销售成本 / 平均库存成本。
- 库存周转天数 = 期间天数 / 库存周转率。
取数示例:
- 期初库存 + 期间入库 − 期间出库 = 期末库存。
-- 期初库存余额SELECTgoods_id,warehouse_id,SUM(qty) AS opening_qtyFROMinventory_transactionsWHEREtran_date < :start_dateGROUP BYgoods_id,warehouse_id;-
期间进销数据从库存流水或采购/销售单据取数,计算平均库存即可。
-
计算周转率和周转天数,在报表工具或 BI 中完成更方便。
5.4 安全库存预警与缺货分析
关键数据:
- 商品安全库存量(可配置在商品维表中)。
- 当前可用库存量。
- 未来预估需求(如近 N 天平均日销量 × 交期)。
取数示例(缺货预警):
SELECTg.goods_id,g.goods_name,ib.qty_available,g.safety_stock,CASEWHEN ib.qty_available < g.safety_stockTHEN 1 ELSE 0END AS is_below_safetyFROMgoods gLEFT JOINinventory_balances ib ON g.goods_id = ib.goods_idWHEREg.is_active = 1;可以在系统中设定定时任务,对 is_below_safety = 1 的商品发送预警。
5.5 多渠道销售与库存整合
取数要点:
- 统一订单表结构,将不同平台订单映射为统一字段(渠道字段
channel表明来源)。 - 统一库存中心,由进销存系统维护总库存,各渠道仅记录“可卖库存”。
示例:按渠道统计销售额:
SELECTo.channel,DATE(o.order_date) AS order_day,SUM(o.qty) AS total_qty,SUM(o.amount) AS total_amountFROMunified_orders oWHEREo.order_date BETWEEN :start_date AND :end_dateAND o.status IN ('PAID', 'SHIPPED', 'COMPLETED')GROUP BYo.channel,DATE(o.order_date);六、提升进销存取数效率的结构化策略 ⚙️
取数不仅是“写 SQL”和“导报表”,更是一个系统工程。要从根本上提升效率,需要在数据结构与系统层做一些规划与优化。
6.1 建立统一的数据字典与指标口径文档
内容应至少包括:
- 每张核心业务表的含义、主键、外键。
- 每个关键字段的解释(含单位、精度、是否必填、业务含义)。
- 常用指标的公式与统计口径(如库存余额、毛利、销售额等)。
好处:
- 避免“每个人理解不一样”的情况。
- 为 BI 或数据仓库建模提供基础。
- 新人加入时可以快速上手。
6.2 数据分层与视图化:从“交易”到“汇总”
对于数据量较大的系统,直接在交易表上做复杂统计会很慢。可以采用分层与预聚合的方式:
- 交易层(明细):
- 所有出入库、订单、收付等原子记录。
- 只做轻量筛选和简单统计。
- 汇总层(预聚合):
- 按日、按商品、按仓库、按渠道等维度预先聚合数据,存入新的汇总表或物化视图。
- 如
daily_sales_summary、daily_inventory_summary。
- 应用层(报表视图):
- 面向业务的视图或接口,对复杂逻辑进行封装。
例如:
CREATE TABLE daily_sales_summary ASSELECTDATE(bill_date) AS bill_day,goods_id,warehouse_id,SUM(qty) AS total_qty,SUM(amount) AS total_amount,SUM(cost_amount) AS total_costFROMsales_delivery_detailWHEREbill_date >= :yesterdayGROUP BYDATE(bill_date),goods_id,warehouse_id;然后报表只查询 daily_sales_summary,提升性能。
6.3 标准化业务流程,减少“脏数据”
取数准确性很大程度依赖“数据质量”,而数据质量来自“业务流程规范”。关键措施包括:
- 强制限制:不允许绕过单据流程直接改库存字段。
- 审核流程:入库、出库、调拨、盘点必须有审核状态,未审核数据不进入统计。
- 字段必填与校验:如商品、数量、价格都必须有有效值;防止负库存等异常。
通过系统强制约束,可显著减少后续取数时的“异常数据处理”。
6.4 权限与审计:保证取数安全与可追溯
- 只读账号:为报表和分析使用者配置只读数据库账号,避免误操作。
- 字段级/表级权限:敏感数据(如成本、价格、利润)仅特定角色可见。
- 日志与审计:对于关键操作(如删除单据、调整库存、修改价格)必须有日志记录。
这些看似“与取数无关”的措施,实则是保证进销存数据和取数结果可信的前提。
6.5 利用低代码工具构建“轻量数据中台”
对于缺乏重型数据仓库与 BI 能力的团队,可以通过低代码平台构建轻量的进销存数据中台:
- 将核心业务数据(采购、销售、库存)定期同步到低代码平台(可用 API、导入等方式)。
- 通过平台的可视化配置功能,设计常用统计报表与仪表盘。
- 在同一平台内可以附加审批、预警、任务分配等流程,实现“从数据到行动”的闭环。
例如,当你已在进销存系统中沉淀了基础数据,可以通过像简道云进销存这样支持自定义表结构和报表的工具,将数据同步或迁移进来,通过图表、看板快速呈现销售、库存和采购关键指标,并根据实际场景调整字段与逻辑,这类方案对于预算有限却希望规范进销存取数的团队非常有价值。
七、特殊场景下的进销存取数实践案例 🔍
为了更具操作性,下面从几个特殊场景出发,说明应如何设计取数思路。
7.1 多仓多门店:如何统一库存视图?
问题:
- 一个品牌有多个仓库(总仓、分仓)和门店,每个地点都有库存。
- 老板希望在一个报表里看到“整体可用库存”和“各仓/各店库存明细”。
取数思路:
- 基于
inventory_balances表按仓库和商品统计现存量。 - 引入“组织/门店维度表”,区分仓库类型(仓库 vs 店铺)。
- 在报表中支持两种视图:
- 全局汇总视图(所有仓库合并)。
- 分仓/分店视图(按层级展开)。
示例 SQL:
SELECTg.goods_id,g.goods_name,w.org_type, -- 'WAREHOUSE' or 'STORE'w.org_name,ib.qty_on_hand,ib.qty_availableFROMinventory_balances ibJOINgoods g ON ib.goods_id = g.goods_idJOINwarehouses w ON ib.warehouse_id = w.warehouse_id;7.2 委外加工与代销:如何避免重复记收入与库存?
委外加工场景:
- 原材料从己方仓库发出(减少库存),加工后成品入库(增加库存)。
- 取数时需区分:原材料发出不是销售,成品入库不是采购。
代销场景:
- 货物属于供应商,放在自己仓库/门店销售。
- 真正收入是佣金或差价,库存可能属于对方。
取数要点:
- 为委外和代销业务设置专门的交易类型与标记字段(如
tran_type = 'OUTSOURCING'、is_consignment = 1)。 - 在统计销售额与库存时,明确是否包含代销商品、委外在制品。
7.3 盘点、盘盈盘亏与差异分析
问题:
- 盘点后调整库存,如何追溯差异?
- 如何统计一段时间内总的盘盈盘亏金额?
取数思路:
- 盘点产生的差异应体现在
inventory_transactions中,交易类型为ADJUST_IN/ADJUST_OUT。 - 统计盘点差异时,只需筛选对应的交易类型。
示例:
SELECTtran_date,goods_id,SUM(CASE WHEN tran_type = 'ADJUST_IN' THEN qty ELSE -qty END) AS qty_diffFROMinventory_transactionsWHEREtran_type IN ('ADJUST_IN', 'ADJUST_OUT')AND tran_date BETWEEN :start_date AND :end_dateGROUP BYtran_date,goods_id;7.4 退货与退款:如何正确处理负数销售?
关键点:
- 退货单建议与原销售单关联(
original_bill_no字段)。 - 取数时可以:
- 将退货视为负数销售(数量与金额为负),统一统计净销售数据。
- 或分开统计“销售”和“退货”,做对比分析。
示例:
SELECTbill_date,SUM(CASE WHEN bill_type = 'SALE'THEN amountWHEN bill_type = 'RETURN'THEN -amountEND) AS net_salesFROMsales_and_returnsWHEREbill_date BETWEEN :start_date AND :end_dateGROUP BYbill_date;八、构建高效进销存取数体系的实施路线图 🧭
如果你希望从零或从“Excel 拼表”状态过渡到一个高效、稳定的进销存取数体系,可以参考以下路线:
8.1 阶段一:梳理需求与现状
- 列出所有角色的核心取数需求(老板、采购、仓库、财务等)。
- 对现有数据来源做盘点:进销存系统、POS、电商平台、Excel 等。
- 识别当前最严重的问题:库存不准?毛利算不清?订单对不上?
8.2 阶段二:统一数据口径和基础结构
- 与实施顾问或 IT 一起建立简易数据字典。
- 为关键指标(销售额、库存、毛利)写出“可被所有人看懂”的口径说明。
- 确定唯一的“权威数据源”:如库存以进销存系统为准,销售以订单系统为准。
8.3 阶段三:构建标准报表与固定取数接口
- 对高频需求(如“按日销售报表”“库存报表”)建立标准报表或接口。
- 能用系统内置报表解决的先用内置,不能的通过数据库视图或低代码平台实现。
- 尽量减少 ad-hoc(一次性)分析,避免重复造轮子。
在这个阶段,引入一套模板化且可扩展的进销存系统会很有帮助。如果你所在团队缺乏 IT 资源,可以尝试用 简道云进销存 等低代码工具,通过现成模板快速搭好采购、销售和库存结构,然后按自己的业务调整字段、流程与报表,实现从“随意取数”到“结构化取数”的过渡。
8.4 阶段四:引入 BI / 数据仓库(视规模而定)
- 对于数据量大、分析维度多的企业,可搭建数据仓库,构建销售、库存等事实表。
- BI 工具连接数据仓库,提供交互式分析和对比。
- 沉淀指标体系,为后续数据驱动运营提供基础。
8.5 阶段五:持续优化与治理
- 持续发现报表口径不一致、数据缺失、流程漏洞并修复。
- 建立数据质量监控,如库存负数、单据金额异常等自动预警。
- 把“取数需求”及时反馈到业务系统设计中,逐步减少“补救式取数”。
九、总结与未来趋势展望 🔮
进销存取数看似是技术问题,实质是制度、流程、系统与数据共同作用的结果。要想让“进销存取数”真正支持企业管理与决策,需要从以下几个方面综合发力:
- 先统一口径,再谈技术实现
- 不要急着写 SQL 或买 BI 工具,先把“库存”“销售”“毛利”等关键概念在组织内讲清楚。
- 建立数据字典与指标说明,是一切取数工作的起点。
- 用系统+流程保证数据质量
- 规范采购、销售、调拨、盘点等业务流程,避免“直接改库存”“绕流程”。
- 对关键字段做必填与校验,减少脏数据。
- 分层取数,避免一次性“大杂烩”
- 区分交易层、汇总层、应用层,视情况采用视图、物化视图或汇总表。
- 报表和分析尽量基于汇总层,保证性能和稳定性。
- 充分利用低代码与云工具降低门槛
- 对于很多中小企业来说,全自研 ERP + 数据仓库投入大、周期长。
- 通过像简道云这类低代码平台构建或改造进销存模块,可以在不牺牲灵活性的情况下,迅速搭建起可用的取数与分析体系。
- 向实时化与智能决策演进
- 随着业务复杂度上升,实时库存同步、多平台订单统一与自动补货建议会越来越重要。
- 系统会逐步从“提供报表”转变为“提供决策建议”(如补货量、调拨路线、促销组合等)。
从趋势来看,进销存取数将越来越强调:
- 实时性:实时库存、实时订单、实时预警。
- 一体化:进销存与财务、电商、WMS、CRM 等系统打通。
- 智能化:基于历史数据的销量预测、缺货预警与智能补货。
如果你正在搭建或优化自己的进销存取数体系,可以从最迫切的几个报表需求入手,逐步统一口径、规范流程,再通过数据库、低代码平台或 BI 工具进行结构化取数,最终形成一个可复用、可信赖的数据基础。
最后,分享一个我们公司在用的进销存系统模板,需要的可以自取,可直接使用,也可以自定义编辑修改: https://s.fanruan.com/8bn69
精品问答:
进销存取数方法有哪些?如何选择最适合的取数方法?
我在做进销存数据分析时,发现市面上的取数方法很多,但不太清楚各自的优缺点和适用场景。如何判断哪种进销存取数方法更高效准确?
进销存取数方法主要包括数据库直连取数、API接口取数、导出表格取数及ETL工具取数。选择合适的方法需根据业务规模、数据实时性需求和技术条件:
- 数据库直连取数:适用于技术能力强的团队,实时性高,数据准确率达99.8%。
- API接口取数:适合系统集成环境,支持自动化,稳定性好。
- 导出表格取数:简单易用,但人工操作多,易出错,准确率约85%。
- ETL工具取数:适合大数据量处理,支持数据清洗和转换,效率提升30%以上。
通过结合业务需求和技术条件,选择合适的进销存取数方法,能显著提升数据处理效率和准确性。
如何利用结构化布局提升进销存数据取数的可读性?
我在整理进销存取数结果时,觉得数据杂乱难以解读。有没有好的结构化布局方法,能帮助我提升数据的可读性和分析效率?
结构化布局能显著提升进销存取数数据的可读性。关键方法包括:
- 采用分级标题(H1、H2、H3)自然融入关键词“进销存取数”,方便快速定位信息。
- 使用列表(如步骤清单、注意事项)增强逻辑清晰度。
- 利用表格对比不同取数方法的参数(准确率、实时性、适用范围),提升信息密度。
例如:
| 取数方法 | 准确率 | 实时性 | 适用场景 |
|---|---|---|---|
| 数据库直连 | 99.8% | 实时 | 技术成熟团队 |
| API接口 | 98.5% | 几分钟延迟 | 系统集成 |
| 导出表格 | 85% | 延迟较大 | 小规模或临时需求 |
通过合理的结构化布局,能帮助用户更快理解和使用进销存取数数据。
在进销存取数过程中,如何通过案例降低技术术语的理解门槛?
我对进销存取数涉及的技术术语不太熟悉,很多文档看起来晦涩难懂。有没有什么方法或案例,能帮助我更好理解这些专业术语?
降低技术术语理解门槛的有效方法是结合实际案例讲解。比如:
- 术语“API接口”:可以解释为“就像餐厅菜单,告诉系统怎样点菜和取餐”,通过形象比喻帮助理解。
- 术语“ETL”:即数据提取(Extract)、转换(Transform)、加载(Load),通过示例说明,如将销售数据从多个分店汇总清洗后统一导入仓库系统。
案例示范:
某企业使用ETL工具,将多渠道销售数据每天自动提取并转换成统一格式,减少人工错误50%,提升数据准确性至99%。
通过案例结合通俗语言,能帮助非技术人员快速掌握进销存取数的关键技术概念。
怎样通过数据化表达增强进销存取数方法的专业说服力?
我在写进销存��数相关的报告时,想让内容更有说服力。单纯讲理论很难打动人,有什么数据化表达技巧可以增强报告的专业度?
数据化表达是提升进销存取数方法专业说服力的核心。技巧包括:
- 引入具体数据指标,如准确率、处理时间、错误率等,量化效果。
- 使用对比数据表格,展示不同取数方法的性能差异。
- 结合图表(柱状图、折线图)直观呈现数据趋势和改进效果。
例如:
通过数据库直连取数,数据准确率提高了14个百分点,从85%提升至99%,同时数据处理时间缩短了40%。
这些量化数据配合清晰的视觉呈现,使报告更具说服力和专业性。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/492624/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号