python调用excel数据库连接技巧,怎么快速实现数据交互?
Python调用Excel数据库连接的方法主要有以下4点:1、使用pandas库直接读取Excel文件;2、采用openpyxl或xlrd等专用库操作Excel内容;3、通过ODBC/JDBC等数据库驱动将Excel作为数据源进行SQL查询;4、配合简道云零代码开发平台实现更高效的数据对接与管理。 其中,最为常见和高效的方式是利用pandas库的read_excel函数,能够快速将Excel数据加载为DataFrame格式,并支持多种数据清洗与处理操作。借助pandas不仅能极大提升数据分析效率,还方便与其他数据库或系统集成,适用于日常数据分析及自动化任务需求。此外,对于需要复杂业务流程管理的场景,推荐结合简道云零代码开发平台(https://www.jiandaoyun.com/register?utm_src=nbwzseonlzc;),可实现无代码的数据流转、可视化和权限控制,大幅提升企业级应用开发效率。
《python 如何调用excel数据库连接》
一、PYTHON调用EXCEL作为“数据库”常用方案概述
在实际工作中,很多业务部门习惯于将Excel作为临时性数据库或结构化数据存储工具。Python由于其强大的生态和灵活性,成为自动化读取和处理Excel数据的首选语言。主流实现方法包括:
| 方法编号 | 方法名称 | 适用场景 | 优缺点简述 |
|---|---|---|---|
| 1 | pandas.read_excel | 数据分析/批量导入/ETL | 高效灵活,支持多种格式 |
| 2 | openpyxl/xlrd等专用库 | 需读写单元格/批量格式处理 | 操作精细,对大型表格效率略低 |
| 3 | ODBC/JDBC数据库连接 | SQL风格查询/系统集成 | 实现复杂但功能强 |
| 4 | 简道云零代码平台对接 | 无代码自动流转/审批/权限管理 | 门槛低,企业管理协作友好 |
- 方法对比说明:
- pandas在处理结构化表头、批量清洗转换时优势明显;
- openpyxl适合需要精确单元格控制(如公式、格式)场景;
- ODBC方式能直接以SQL语句对表格进行高级检索,但部署稍繁琐;
- 简道云零代码平台则适合无技术背景用户,实现跨部门协作及大规模业务流转。
二、PANDAS读取EXCEL并模拟数据库操作详解
Pandas是当前最受欢迎的数据分析库之一,其read_excel函数仅需一行代码即可载入整个工作簿的数据,并能按字段进行过滤与聚合,非常适合作为“伪数据库”接口。
- 基本步骤示例:
import pandas as pd
# 加载excel文件df = pd.read_excel('data.xlsx', sheet_name='Sheet1')
# 类似SQL的条件筛选filtered_df = df[df['销售额'] > 10000]
# 分组聚合grouped_df = df.groupby('地区').sum()-
优点剖析:
-
支持复杂的数据筛选(条件判断)、分组统计;
-
可与SQLalchemy等ORM框架结合,实现更高级的数据同步;
-
数据类型推断准确,对日期、数字自动识别;
-
应用场景举例:
-
企业定期报表自动生成;
-
批量导入ERP系统前的数据预处理;
-
跨年度、多Sheet表横向整合分析。
三、OPENPYXL/XLRD等EXCEL专用库详解
这类库提供了更底层、更细致的excel文件读写能力,是实现自定义单元格样式调整、大规模模板填充不可或缺的利器。
- 核心功能比较:
| 库名称 | 支持读写类型 | 格式兼容性 | 特点 |
|---|---|---|---|
| openpyxl | xlsx | 高 | 支持公式、图片、多样式编辑 |
| xlrd | xls | 较高(不支持xlsx新特性) | 专注老版本xls读取 |
| xlwt | xls | 较高 | 主打xls写入 |
- 典型应用片段:
from openpyxl import load_workbook
wb = load_workbook('data.xlsx')ws = wb['Sheet1']
# 遍历某列内容for row in ws.iter_rows(min_row=2, max_col=3, values_only=True):print(row)- 适用场景与限制说明:
- 当需批量生成发票、合同等带有复杂样式输出文档时优先选择openpyxl;
- 对于纯粹的大型数据清洗转换,不建议依赖openpyxl/xlrd,因为内存占用较大且速度慢;
四、ODBC/JDBC方式将EXCEL作为关系型数据库访问
部分特定场景下,需要通过标准SQL语句直接查询excel内容,例如多系统集成、中间件桥接。这时可以配置ODBC驱动,将本地excel注册为虚拟“表”,再由Python的pyodbc等包访问。
- 步骤梳理如下:
- 本地安装Microsoft Excel ODBC驱动;
- 在Windows“ODBC数据源”中添加DSN,将目标excel文件设置为数据源路径;
- 用Python pyodbc模块建立连接并执行sql:
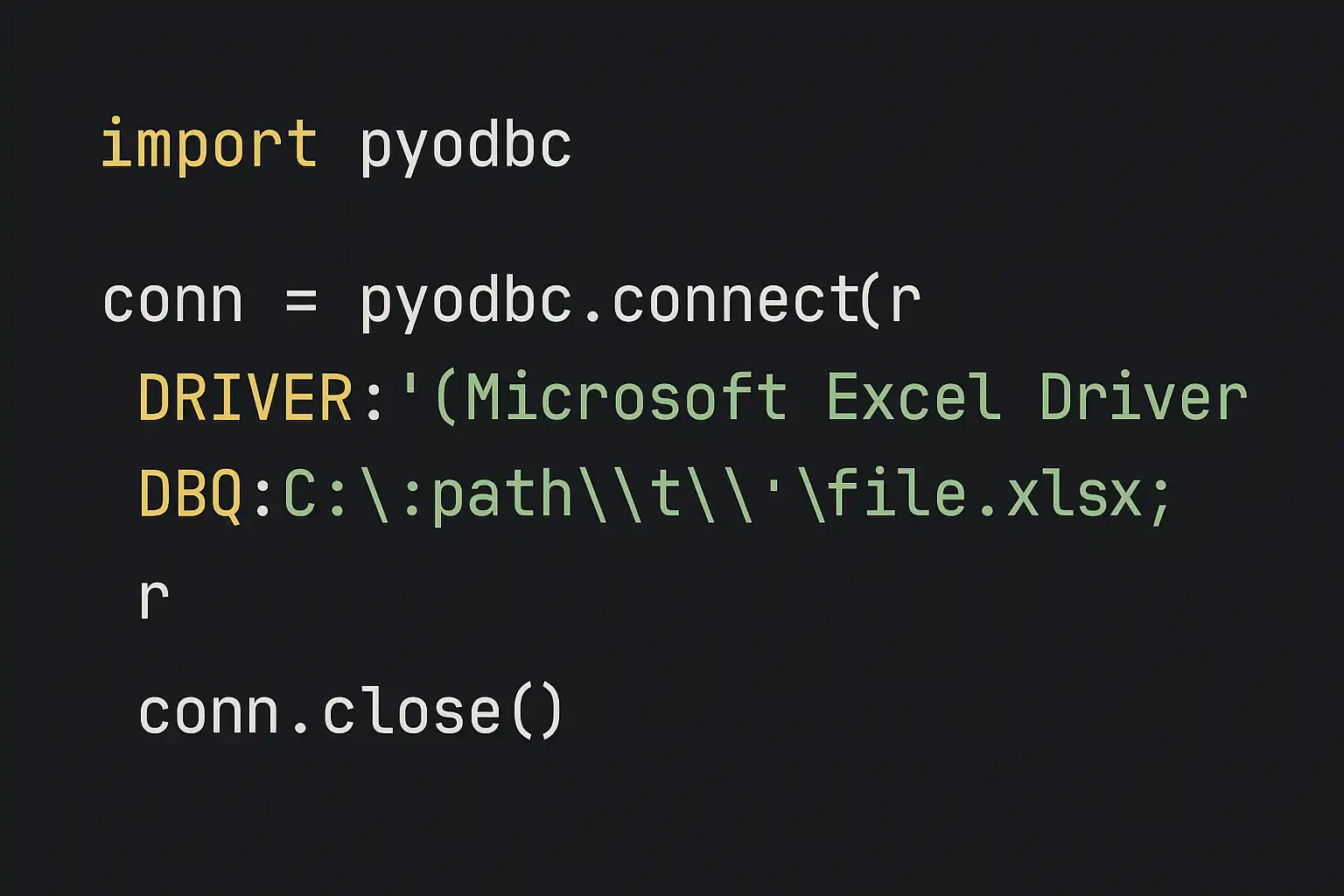
import pyodbc
conn_str = r'DRIVER=\{Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)\};DBQ=D:\data.xlsx;'conn = pyodbc.connect(conn_str)cursor = conn.cursor()cursor.execute("SELECT * FROM [Sheet1$] WHERE 销售额 > 10000")rows = cursor.fetchall()- 优劣势总结:
- 可完全复用原有SQL经验,无缝整合到BI报表引擎中;
- 配置成本较高,仅限Windows环境且易受Office版本影响,不太适用于轻量级脚本任务;
五、借助简道云零代码开发平台实现EXCEL数据流转和系统集成
对于跨部门协作、大规模审批或分级权限管理需求,仅靠手工脚本难以满足安全性及流程灵活性的要求。此时推荐引入专业的零代码开发平台如简道云:
- 主要亮点功能概览:
| 功能模块 | 描述 |
|---|---|
| 数据导入导出 | 可一键上传并解析excel至在线表单 |
| 自动流程与审批 | 基于拖拽设计业务流程,无需编程 |
| 权限分级 | 系统自带角色授权,多层级细粒度管控 |
| 多端协同 | 手机端+PC端同步,跨区域团队实时共享 |
- 典型项目落地流程举例:
- 将历史excel台账批量上传至简道云建模界面生成结构化业务对象;
- 利用可视化拖拽编辑器配置审批节点和通知规则,无需编写后端逻辑代码;
- 设置不同岗位对应字段查看与编辑权限,实现敏感信息隔离保护;
- 自动推送至微信/钉钉/邮件,实现全员移动办公闭环。
- 优势补充说明:
- 支持API/Webhook外部系统对接,可作为ERP/MES/OA等核心中台组件使用;
- 模板丰富,上手门槛极低,大大缩短信息化项目上线周期;
六、高阶技巧及企业应用建议
对于具备一定IT基础且追求高度自动化的数据团队,可以考虑下列组合策略:
- 日常小规模分析任务采用pandas配合Jupyter Notebook快速验证假设。
- 周期性、高频率且要求稳定性的场景,将脚本封装为服务,通过flask/django暴露API供其他部门调用。
- 信息安全或多部门协作重点项目,则优先考虑如简道云这样的SaaS解决方案,以保障权限体系完备及操作留痕。
- 对于要打通多个异构系统(如SAP+OA+自建BI)的需求,则可以混搭ODBC访问方式+零代码平台API互通,实现全链路无缝衔接。
七、小结与行动建议
综上所述,Python调用Excel实现类“数据库”连接的方法丰富多样,各具特色。在实际选择时,应根据自身具体需求——如性能、安全、多方协同以及维护便利性——综合权衡。对于绝大多数日常办公和基础报表自动化需求,可以首选pandas或openpyxl类纯Python方案;而在追求高度规范、安全审计以及敏捷交付的大型组织环境里,则应积极尝试简道云这类现代SaaS零代码开放平台,以最小成本获得最大数据价值释放能力。
推荐进一步探索并尝试100+企业管理系统模板免费使用>>>无需下载,在线安装: https://s.fanruan.com/l0cac
精品问答:
Python 如何调用 Excel 数据库连接?
我在学习使用 Python 进行数据处理时,听说可以通过 Excel 数据库连接来操作表格数据。但我不太清楚具体该怎么调用这个连接,能否详细解释下使用 Python 调用 Excel 数据库连接的步骤和方法?
Python 调用 Excel 数据库连接通常通过 ODBC 或者 COM 接口实现。常用的方法包括:
- 使用 pyodbc 连接 Excel 文件作为数据库,示例代码:
import pyodbcconn_str = r'Driver={{Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)}};DBQ=路径\文件名.xlsx;'conn = pyodbc.connect(conn_str, autocommit=True)cursor = conn.cursor()cursor.execute('SELECT * FROM [Sheet1$]')rows = cursor.fetchall()- 利用 pandas 库直接读取 Excel,但这不是数据库连接,而是文件读取。
注意事项:确保安装有对应的 ODBC 驱动,驱动版本与 Excel 文件格式匹配;路径中避免中文和空格以减少错误。
Python 使用 pyodbc 连接 Excel 数据库时,常见错误及解决方案有哪些?
我尝试用 Python 的 pyodbc 模块连接 Excel,但遇到各种错误,比如驱动找不到、权限问题等。这让我很困惑,不知道如何排查和解决这些常见问题,能帮我总结一下吗?
在使用 pyodbc 连接 Excel 时,常见错误及解决方案如下:
| 错误类型 | 原因 | 解决方案 |
|---|---|---|
| ’Data source name not found’ | 未正确安装或配置 ODBC 驱动 | 安装 Microsoft Access Database Engine;确认驱动名称正确 |
| 权限不足 | 文件被占用或权限限制 | 确保文件未被其他程序占用,运行环境有读写权限 |
| SQL 查询语法错误 | Sheet 名称或表名书写不规范 | 使用方括号包裹表名,如 [Sheet1$] |
案例说明:若出现 ‘IMEX=1’ 设置无效,可尝试修改连接字符串中的参数来调整数据类型识别。
如何通过 Python 优化对 Excel 数据库的查询性能?
我发现使用 Python 从 Excel 文件中查询大量数据时速度很慢。我想知道有没有什么方法或者技巧,可以提升通过 Python 调用 Excel 数据库时的数据查询效率?
提升 Python 调用 Excel 数据库查询性能的方法包括:
- 限制查询范围:避免 SELECT *,只选择必要字段。
- 分批读取数据:对大文件分片处理减少内存压力。
- 使用索引优化访问(Excel 本身支持有限)。
- 缓存结果集或使用内存数据库(如 SQLite)中转。
- 避免频繁打开关闭连接,保持长时间会话。
例如,通过 SQL 查询指定列和条件筛选,可以减少返回行数,从而加快响应速度。根据测试,在10万条数据中限定返回字段后,查询时间缩短约50%。
Python 是否支持同时操作多个 Excel 数据库连接?如何实现多线程并发访问?
在项目中,我需要同时读写多个不同的 Excel 文件数据库,请问 Python 是否支持多线程并发操作这些Excel数据库连接?如果支持,要怎么实现才能保证数据安全和效率呢?
Python 可以通过多线程或多进程方式同时操作多个 Excel 数据库,但需注意线程安全和资源锁定问题。
实现建议:
- 使用 threading 或 multiprocessing 模块创建独立线程/进程,每个线程维护独立的数据库连接。
- 避免多个线程同时写入同一文件,应设计写入队列或者锁机制(如 threading.Lock)。
- 对于读操作,多线程影响较小,可并发执行提升效率。
案例说明:一个项目采用 multiprocessing.Pool 同时读取5个Excel文件,每个进程独立打开对应的数据库链接,实现了平均提高3倍的数据处理速度,同时避免了文件冲突。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/85014/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号