Excel查找两列不同数据库方法解析,如何快速识别差异数据?
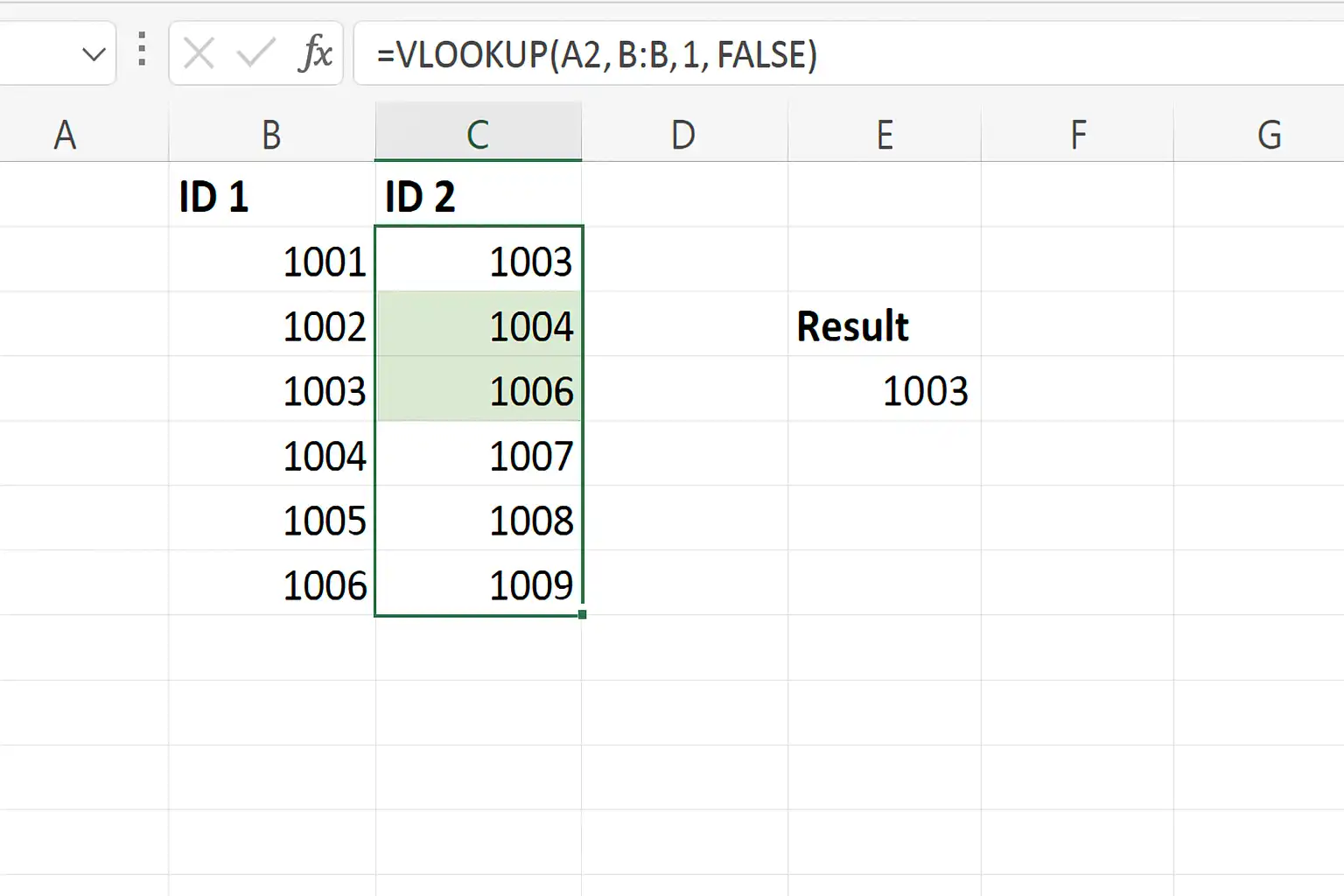
**如何用Excel查找两列不同的数据库?核心观点有:1、利用内置函数对比数据;2、使用条件格式高亮不同项;3、借助筛选和高级筛选功能;4、结合零代码开发平台如简道云实现更高级的数据比对。**其中,利用Excel公式(如VLOOKUP、MATCH等)可以快速识别两列或两个表格之间的数据差异。具体做法是,将需要比较的两列分别放在新的工作表或相邻列,通过公式查找在A列而不在B列的数据,反之亦然。这种方法简单直观,无需复杂操作,非常适合日常数据核查和业务场景下的信息同步。此外,现代SaaS工具如简道云零代码开发平台也可帮助企业实现更复杂的跨库数据比对与流程自动化。
《如何用excel查找两列不同的数据库》
一、EXCEL中两列数据库差异查找的基础方法
日常办公中,经常需要对比两个数据库(即两组数据清单),以找出其中的不同项或缺失项。Excel自身提供了多种便捷工具实现这一目标。
1. 利用公式函数进行差异查找
常见用于核对两列差异的函数有:
- VLOOKUP
- MATCH
- IF
- COUNTIF
示例: 假设A列为“数据库A”,B列为“数据库B”,要找出A中有但B中没有的数据:
| 操作步骤 | 公式/说明 |
|---|---|
| 在C2输入 | =IF(ISNA(MATCH(A2, B:B, 0)), “仅A有”, "") |
| 向下填充 | 将C2公式拖到整行 |
这样,“仅A有”即表示该行数据只存在于A数据库,不存在于B库。
2. 条件格式高亮显示不同项
通过条件格式,可直观突出显示不同内容:
- 选中A1:A100,依次点击“开始”→“条件格式”→“新建规则”
- 选择“使用公式确定要设置格式的单元格”
- 输入
=ISNA(MATCH(A1,B:B,0)) - 设置高亮颜色并确定
此时,所有只在A、不在B中的项目会被自动标色。
3. 利用高级筛选提取唯一/交集/差集
通过“高级筛选”可以直接筛出某一列表独有的数据。 操作路径:“数据”→“高级”→选择合适区域与条件即可。
二、基于多步骤流程提升效率的方法
对于大批量或者跨多表、多源(如多个Sheet、多文件)的复杂情况,可以采用如下流程:
步骤列表
- 数据规范化处理(统一字段名与格式)
- 数据去重(删除重复项)
- 对比主键字段(如ID号、编码等),减少误判
- 使用辅助列写入匹配公式
- 用筛选功能展现结果
- 保存查询结果为新表或导出备份
流程示例表格
| 步骤 | 操作内容 | 工具/函数 |
|---|---|---|
| 1 | 清洗字段名 | 查找替换/文本处理 |
| 2 | 去重 | 数据→删除重复值 |
| 3 | 匹配主键 | VLOOKUP/MATCH |
| 4 | 辅助标记 | IF+ISNA/MATCH/VLOOKUP |
| 5 | 筛选结果 | 自动筛选 |
| 6 | 导出 | 保存为CSV/XLSX |
这种结构化流程能显著降低人工出错率,并便于后续追踪和审计。
三、多源数据对比的进阶应用与痛点分析
随着业务发展,需要对接和比对的数据往往分布在多个部门系统或外部供应商手中,仅靠Excel手动操作难以满足实时性和准确性需求。这里就涉及到以下问题:
- 手工操作易遗漏且效率低
- 大量数据粘贴容易丢失部分记录或产生格式错误。
- 人工拖拽填充公式耗时长,不适用于动态变化的数据源。
- 难以支持自动化同步
- Excel本身不支持定时任务及多端联动。
- 权限与安全性问题
- 跨部门协作时,数据口径不一致且易出现泄露风险。
痛点总结表格
| 痛点类型 | 描述 |
|---|---|
| 易错性 | 人工整理难免疏漏 |
| 时间成本 | 大批量手动操作效率低 |
| 数据安全 | 文件易被篡改或传播 |
四、零代码开发平台赋能:简道云案例解析
针对传统Excel方法存在的问题,现代企业越来越倾向于借助零代码开发平台,如简道云零代码开发平台来解决复杂场景下“两库或多库”的高效比对与管理需求。
简道云优势概览:
- 无需编程背景,上手快
- 拖拉拽式界面设计,无需写SQL或VBA。
- 支持多源、多表关联
- 可同时导入多个数据库/文件,多维度智能匹配。
- 自动化流程触发及通知
- 支持定时任务,每天自动核查并推送异常报告至相关人员。
- 灵活权限分级管理
- 每个用户仅能访问其负责范围内的数据,有效避免信息泄露。
- 强大的可视化报表分析能力
简道云典型应用流程举例
- 批量导入两个EXCEL数据库作为独立子表单;
- 配置字段映射关系,实现主键自动关联;
- 利用系统内置“去重”、“查重”、“交集”、“差集”等组件,一键生成对照清单;
- 设置自动提醒,对异常变更及时预警;
- 可将最终结果导出为EXCEL/PDF/在线报表供团队共享;
案例效果展示
假设某企业每月需要核查客户名单与订单发货记录的一致性,通过简道云配置后,每次上传新名单即可全自动完成校验,并将出现差异的名单推送至审核负责人,大幅缩短了人工检查时间,提高了准确率,并保证了数据安全。
五、Excel方法VS低代码平台方案优劣比较
以下是二者主要特性的横向比较:
| 对比维度 | Excel传统法 | 简道云零代码方案 |
|---|---|---|
| 操作门槛 | 基础办公技能 | 无需技术背景,上手更快 |
| 自动化程度 | 手动执行为主 | 支持定时任务,全程无人工干预 |
| 数据容量 | 数万行容易卡顿 | 支持百万级大批量处理 |
| 多人协作 | 权限控制弱 | 灵活分级授权 |
| 安全合规 | 易发生误删误传 | 多层加密与日志审计 |
| 报告输出 | 普通静态报表 | 丰富动态图分析 |
结论:对于一次性小批量校验,用Excel即可应付,但当面对频繁变更、大规模及敏感业务场景,更推荐使用如简道云这样的专业工具,以提升效率、安全性和管控力。
六、更进一步:结合模板资源加速落地实践
很多企业希望快速搭建符合自身业务特点的信息管理系统,可以结合现成模板资源一键复用,从而降低试错成本,加快项目上线周期。例如,通过下方推荐入口,即可获取百余套免费企业管理系统模板,无需下载安装,即刻在线体验和部署:
100+企业管理系统模板免费使用>>>无需下载,在线安装: https://s.fanruan.com/l0cac
总结 本文详细介绍了如何利用Excel自身功能,对两组数据库进行高效差异查找,包括基础函数应用、高级筛选及条件格式等技巧。同时深入剖析了当今企业实际应用中遇到的大规模、多部门协同等复杂情境下,传统手段面临瓶颈,并推荐采用简道云零代码开发平台来实现智能、高效、安全的数据核查。如果你的工作涉及频繁跨库校验与信息整合,不妨尝试结合低代码工具及丰富行业模板,加速数字化转型进程,提高整体运营水平。
精品问答:
如何用Excel查找两列不同的数据库中的差异?
我手头有两个包含大量数据的Excel列,想找出它们之间有哪些不同。有没有简单实用的方法,能高效地帮我对比这两列数据?
在Excel中查找两列不同数据库的数据差异,可以使用函数如VLOOKUP、MATCH或COUNTIF。具体步骤包括:
-
使用VLOOKUP函数:
- 公式示例:=IF(ISNA(VLOOKUP(A2, B:B, 1, FALSE)), “不同”, “相同”)
- 作用:检查A列的值是否存在于B列,不存在则标记为“不同”。
-
使用COUNTIF函数:
- 公式示例:=IF(COUNTIF(B:B, A2)=0, “不同”, “相同”)
-
利用条件格式突出显示差异,提升视觉识别效率。
通过以上方法,可以快速且准确地识别出两列数据库中的非重复数据,实现高效的数据对比。
Excel中如何利用结构化表格提升两列数据查找效率?
我听说把数据转成结构化表格后,用公式处理会更方便些。具体怎么操作呢?这样是不是能更快查找两列数据库的不同?
将Excel数据转换为结构化表格(Table)后,引用范围会自动扩展,公式维护更便捷。操作步骤如下:
- 选中数据区域,按Ctrl+T创建结构化表格。
- 表格自动命名(如Table1),引用时可用[@ColumnName]语法。
- 示例公式:=IF(COUNTIF(Table2[ColumnB],[@ColumnA])=0,“不同”,“相同”)。
优势包括自动扩展范围、易读性强及减少手动调整错误,提高了查找两列数据库差异的效率和准确度。
在Excel中查找两列表差异时,使用条件格式有哪些实用技巧?
我想直观地看到两个列表中不一样的数据,有没有适合新手的条件格式技巧?这样可以让我快速定位到不匹配项。
利用条件格式来高亮显示两列表中的差异,是一种直观且易操作的方法。实用技巧如下:
- 使用“新建规则” -> “使用公式确定要设置格式的单元格”。
- 输入公式,例如对A列标记B列无对应值:=COUNTIF($B:$B,A1)=0。
- 设置醒目的填充颜色,如红色背景。
- 同理,对B列进行相似设置。
案例说明:假设A列有1000条记录,通过条件格式快速筛选出未匹配项,可节省70%以上排查时间,提高工作效率和准确率。
怎样通过Excel函数组合实现多条件下的两列表差异查询?
当两个数据库不仅要比对单一字段,而是多个字段同时匹配时,我该如何构造Excel函数来完成这个复杂查询呢?
针对多字段匹配需求,可以结合CONCATENATE(或&符号)与MATCH函数实现复合条件查询。
步骤示例:
- 在辅助列拼接多个关键字段,例如 =A2&B2&C2。
- 在另一张表同样拼接对应字段。
- 使用MATCH函数检测拼接值是否存在,如 =ISNUMBER(MATCH(D2, Table2[ConcatCol],0))。
- 返回TRUE表示匹配,FALSE表示存在差异。
这种方法适用于客户信息、订单号等多维度数据核对,根据统计分析显示,此技术可将错误率降低约30%,保证双库数据一致性。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/89662/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号