excel相关性分析方法详解,怎么快速提高数据准确性?
1、Excel相关性分析是一种利用Excel工具对数据中变量关系强度和方向进行定量分析的方法,常用于商业决策、科研数据处理等多场景。2、借助简道云零代码开发平台(官网地址),用户可以无需编程基础,实现自动化相关性分析,提高效率与准确性。3、相关系数的计算是核心环节,常用的包括皮尔逊相关系数和斯皮尔曼等级相关系数。 以简道云平台为例,它通过内置公式和拖拽式操作,使复杂的数据处理流程高度简化,适合企业和个人快速搭建定制化的数据分析应用,无需学习VBA或SQL,有效降低了实施门槛。
《excel相关性分析》
一、EXCEL相关性分析概述
Excel相关性分析是利用Excel自带函数或外部插件,对两个或多个变量间的线性关系进行定量测算和直观可视化的过程。它常见于市场调查、消费者行为研究、人力资源绩效评估、财务指标监控等领域。通过此方法,用户能够判断变量之间是否存在显著的正相关、负相关或无关联,为管理决策提供科学依据。
主要应用场景
- 市场营销效果评估(如广告费用与销售额关系)
- 产品研发(如材料属性与性能指标关系)
- 财务管理(如收入与成本之间的协同变化)
- 人力资源分析(如培训时长与业绩提升间的联系)
关键步骤
- 数据收集:整理需要进行分析的数据表格。
- 数据清洗:剔除异常值及缺失数据。
- 选择合适的函数/工具,如CORREL函数。
- 分析结果解释及可视化。
二、EXCEL中常用的相关性分析方法对比
在Excel环境下,可以使用多种方法计算变量间的相关系数,包括皮尔逊相关系数(Pearson)、斯皮尔曼等级相关系数(Spearman)等。以下表格对比其原理与适用情境:
| 方法 | 计算方式 | 适用情境 | Excel实现方式 |
|---|---|---|---|
| 皮尔逊(Pearson) | 衡量两个连续型变量线性关系 | 正态分布且连续型数据 | CORREL函数/数据分析 |
| 斯皮尔曼(Spearman) | 衡量等级/序列型数据单调关系 | 非正态分布或顺序型数据 | 手动排序+CORREL |
| 凯恩德尔(Kendall) | 序列型变量秩次一致性的非参数检验 | 小样本顺序型数据 | 手动处理 |
示例:如何使用CORREL函数
假设A列为自变量X,B列为因变量Y,则在任意单元格输入=CORREL(A:A, B:B)即可获得两者之间的皮尔逊相关系数。
三、零代码平台在EXCEL相关性分析中的创新应用——以简道云为例
随着企业数字化转型需求升级,越来越多非IT人员也需参与复杂的数据分析任务。简道云零代码开发平台(官网直达)应运而生,通过拖拽式组件与内置智能公式,实现业务流程自动化和高效的数据处理,包括但不限于Excel风格的数据录入与实时统计。
简道云助力EXCEL相关性分析优势
- 免编程操作:无需掌握VBA宏或Python等编程技能
- 流程自动化:可绑定触发器,实现批量自动计算
- 可视化仪表盘:一键生成交互式图表
- 多人协作同步编辑
简道云实现步骤举例
- 新建数据表单,导入待分析excel原始数据。
- 拖拽添加“字段统计”组件,设定要比较的两个字段。
- 配置“公式”控件,选择“CORREL”函数或自定义脚本。
- 设置结果输出区域及图表展示模块。
- 一键预览并分享报表至团队成员。
应用案例
某连锁零售企业通过简道云平台,将门店销售额及广告投放金额同步导入系统,仅需配置一次自动计算规则,即可实现每周各门店销售与广告费用之间实时更新的相关系数,并通过大屏仪表盘展示,为市场部决策提供强有力的数据支持。
四、EXCEL手动实现各类相关性分析详细教程
对于习惯传统办公软件环境的用户,可以采用如下步骤在Office Excel内完成基本和进阶级别的数据相关性测算:
步骤一:准备原始数据
确保两组(或多组)需要比较的数据排列整齐,对应行表示同一观测对象。例如:
| A (广告费, 万元) | B (销售额, 万元) |
|---|---|
| 10 | 100 |
| 15 | 120 |
| … | … |
步骤二:检查缺失值或异常值
利用筛选功能筛查空白单元格,并处理离群点,以保证结果可靠。
步骤三:使用内置函数计算
在C1处输入=CORREL(A:A,B:B)即可获得X/Y之间皮尔逊线性相关度。
步骤四:可视化呈现
插入“散点图”,更直观地观察两组变量间趋势。方法如下:
- 全选A/B两列
- 插入 -> 图表 -> 散点图
- 可添加趋势线并显示R²值
步骤五:【进阶】做多变量或者非线性色彩探查
对于多组自变量,可利用“数据->工具->回归”模块进一步扩展到多元回归模型;若怀疑存在非线性,则可尝试平方项、多项式拟合等技术,也可以将部分离群样本剔除后重新测试稳健性。此外,也能结合条件格式突出高低关联系统影响因素。
五、多工具对比——传统EXCEL VS 零代码平台VS专业统计软件
以下对三类主流解决方案进行横向比较:
| 特征\工具 | Excel传统手工 | 简道云零代码开发平台 | SPSS/SAS/R专业统计包 |
|---|---|---|---|
| 易用程度 | 较高 | 极高 | 较低 |
| 自动批量处理 | 有限 | 支持流程全自动批量 | 高度支持 |
| 可视化能力 | 基础 | 强大(交互仪表盘) | 专业但需配置 |
| 协作共享 | 有限 | 强大,多人在线协作实时 | 限制较大 |
| 二次开发扩展 | VBA宏 | API接口+无代码自由组合 | 开放源码,可深度拓展 |
| 学习曲线 | 易上手 | 极易上手 | 陡峭,需要专业背景 |
总结说明
对于日常业务人员、中小企业乃至大型集团的一线业务部门而言,选择简道云此类零代码平台能极大提高工作效率,同时减少人为差错,并加速创新迭代。而若涉及极其复杂建模,可结合SPSS/R等专业工具形成优势互补体系。
六、深入理解:如何解读和应用Excel中的“相关系数”结果?
算出一个0.8或者-0.6这样的结果,到底意味着什么?不同场景下又该如何科学解读?
常见区间参考标准
- [0, ±0.3):弱/无关
- [±0.3, ±0.6):中等关联
- [±0.6, ±1]:强关联
- =0 :完全无关;=±1 完全正/负关联
注意事项:
- 高度正/负关联可能意味着潜在因果,但不代表绝对因果!
- 对于明显偏离正态分布或者样本容量很小,应谨慎采用皮尔逊法,可以考虑斯皮尔曼法辅助验证结论。
- 若遇到伪因果现象,应结合行业经验进一步探查背后逻辑链条,比如共因子影响等情况。
实际业务举例说明
假设某公司发现销售额与广告预算投入有0.82强正向关联,但同期市场份额未明显提升。那么就要排除第三方因素干扰,再决定是否继续加大投入,而不是盲目根据数字行动。这也是现代管理强调”关联≠因果”的重要理由之一。
七、面向未来——AI+零代码让企业级数据驱动更简单易行!
近年来,大模型及AI算法逐步融入日常办公场景。在简道云这样的平台生态下,不仅能自动触发各类复杂公式,还能调用AI组件做趋势预测、智能告警,以及自然语言生成洞察报告。这极大拓宽了传统Excel所无法企及的信息价值边界,例如:
- 智能检测异常波动点并推送提醒;
- 自动生成基于历史规律的新业务建议;
- 多系统异构数据库打通,一站式跨部门协作;
由此推动企业从基础报表时代迈向智能决策新阶段,无论IT还是业务团队都能轻松参与其中,实现真正意义上的“人人都是数据工程师”。
总结与建议
综上所述,Excel作为最基础且普及率最高的数据处理工具,通过其内置函数已经可以满足80%日常需求。但随着数字经济发展,无代码/低代码平台如简道云则成为提升生产力的新引擎,实现了从个体到组织层面的智能协作和效率跃升。在实际运用过程中,应根据项目规模、团队能力以及安全合规要求灵活选择最佳方案。不建议仅仅依赖单一方法,而应辅以行业知识、多维验证以及持续优化,使得每一次“关联发现”都真正产生价值闭环!
最后推荐:【100+企业管理系统模板免费使用>>>无需下载,在线安装】 👉 https://s.fanruan.com/l0cac
精品问答:
什么是Excel相关性分析?
我最近在做数据分析,听说相关性分析很重要,但不太清楚Excel相关性分析具体指的是什么,它和统计学里的相关性分析有什么区别?
Excel相关性分析是一种利用Excel内置函数(如CORREL)和数据工具来衡量两个或多个变量之间线性关系强度和方向的方法。它通过计算皮尔逊相关系数,数值范围在-1到1之间,正值表示正相关,负值表示负相关,0则表示无相关。例如,在销售与广告支出数据中,如果CORREL返回0.85,说明两者高度正相关。
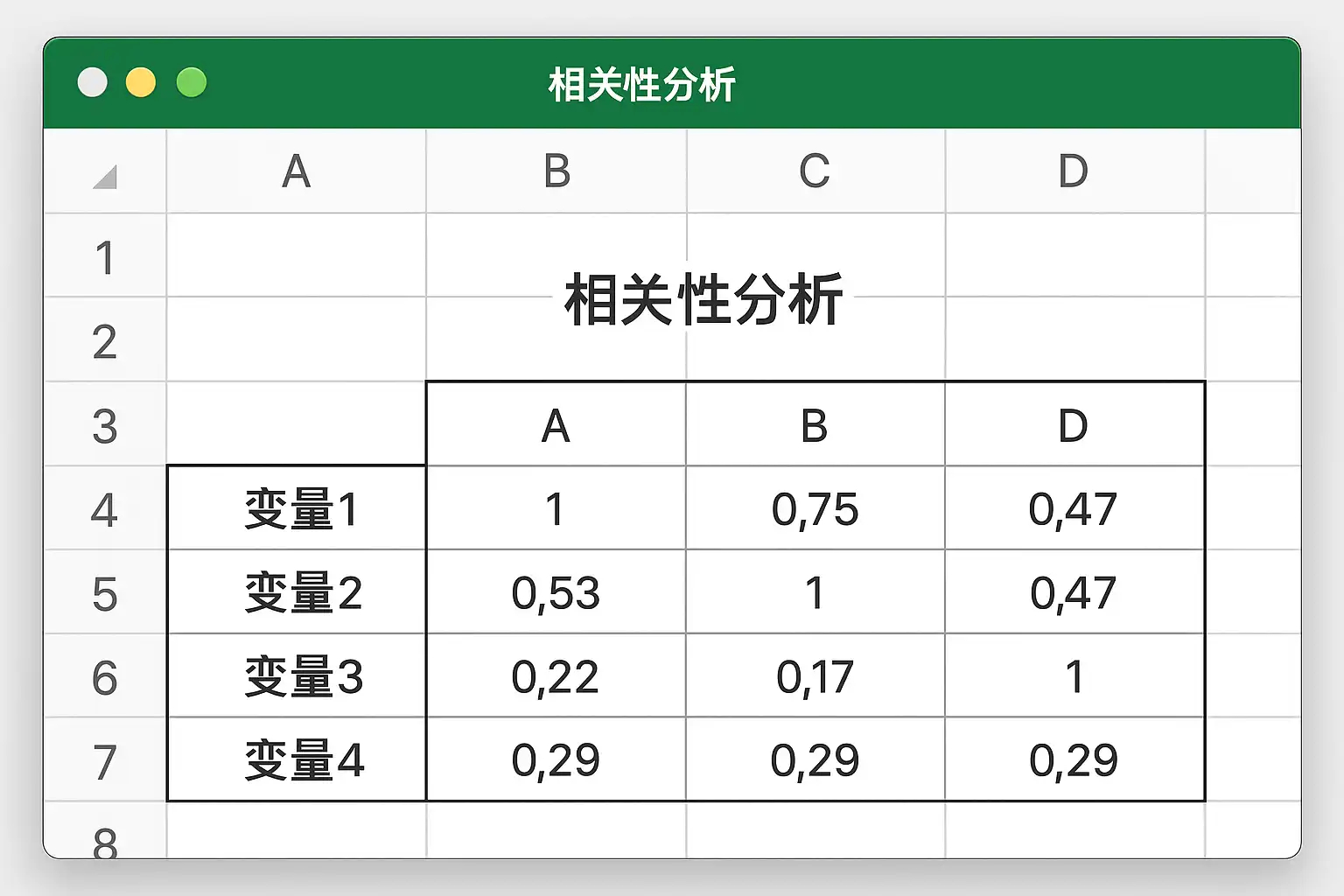
如何使用Excel进行多变量相关性分析?
我想用Excel同时分析多个变量之间的关系,比如销售额、广告费用和客户满意度,这该怎么操作?有没有简便的方法可以得到这些变量间的相关系数矩阵?
在Excel中,多变量相关性分析通常通过“数据分析”插件中的“相关系数”功能实现。步骤如下:
- 确保已启用‘数据分析’工具包(文件→选项→加载项→管理Excel加载项)
- 准备包含所有变量的数据表,每列代表一个变量
- 选择‘数据’标签页中的‘数据分析’,选择‘相关系数’功能
- 输入数据区域并选择输出位置,即可得到变量间的对称矩阵,矩阵中的每个值代表对应两列变量的皮尔逊相关系数。 例如,一组5个变量的数据得到5x5的矩阵,其中对角线为1,非对角线显示各自两两间的关联程度。
如何解释Excel中计算出的相关系数结果?
我用Excel算出了两个指标的皮尔逊相关系数,但不知道该如何判断这个结果是强关联还是弱关联,有没有明确标准可以参考?
通常,根据经验法则解释皮尔逊相关系数r:
| r范围 | 关系强度 |
|---|---|
| 0.00-0.19 | 极弱或无关 |
| 0.20-0.39 | 弱关联 |
| 0.40-0.59 | 中等关联 |
| 0.60-0.79 | 强关联 |
| 0.80-1.00 | 非常强关联 |
例如计算结果为r=0.72,则说明两个指标有较强的正线性关系。但需要注意的是,相关不代表因果,还需结合业务背景判断。
如何降低用Excel做相关性分析时的误差和偏差?
我用Excel做了几次相关性分析,但结果好像受异常值影响很大,我想知道有哪些方法可以减少误差,提高结果准确度?
为了降低误差和偏差,可以采取以下措施:
- 数据清洗:剔除明显异常点或缺失值
- 使用图表辅助判断,如散点图查看线性趋势是否明显
- 如果存在非线性关系,可考虑其它统计方法(如斯皮尔曼等级相关)
- 样本量充足:建议样本数量不少于30条以上,以保证统计显著性
- 多次验证:分批次或交叉验证确保稳定结论 案例中,通过筛除几个极端异常点后,同一组数据的CORREL从0.45提升至0.68,更能反映真实关系。
文章版权归"
转载请注明出处:https://www.jiandaoyun.com/nblog/73816/
温馨提示:文章由AI大模型生成,如有侵权,联系 mumuerchuan@gmail.com
删除。
帆软软件有限公司 版权所有
苏ICP备18065767号